
预训练模型(Pre-trainedModel) 是人工智能(特别是深度学习)领域的一个核心概念。
简单来说,它就是一个已经“读过很多书”、“见过很多世面”的模型基础。开发者不需要从零开始教它认字或认图,而是直接在这个“博学”的基础上,针对具体的任务进行少量的“特训”,就能让它快速上手工作。
为了让你彻底明白,我们可以用一个生动的比喻:
1. 核心比喻:大学生 vs. 小学生
- 没有预训练模型(从零训练):
就像你要培养一个医生。如果你从零开始,你得先教他识字、学拼音、读小学课本、再读中学课本……这需要十几年时间,耗费巨大的精力和学费(算力成本)。 - 使用预训练模型:
就像你直接招聘了一个名牌大学的医学毕业生。- 预训练阶段:他已经读完了小学、中学、大学的所有基础课程(通识教育),认识了世界上几乎所有的字,懂得了基本的逻辑和常识。这部分工作别人已经帮他做完了。
- 微调阶段 (Fine-tuning):你只需要花几周时间,教他你们医院特有的流程、或者专门教他如何看“眼科”或“心脏科”。
结果:你省去了十几年的基础教育时间,直接用最低的成本得到了一个专家。
2. 两个关键阶段
预训练模型的工作流程通常分为两步:
第一步:预训练 (Pre-training) —— “通识教育”
- 做什么:让模型在海量、通用的数据集上学习(比如整个互联网的文本、ImageNet的千万张图片)。
- 学什么:学习通用的规律。
- 语言模型:学习语法、词汇关系、世界常识(如“巴黎是法国的首都”)。
- 视觉模型:学习边缘、纹理、形状、物体轮廓(如“圆形的、红色的可能是苹果”)。
- 特点:耗时极长、算力成本极高(往往需要几百张显卡跑几个月),通常由大公司(如Google, Meta, 百度, 阿里)完成。
- 产出:一个通用基础模型(Base Model)。
第二步:微调 (Fine-tuning) —— “专业进修”
- 做什么:拿着上面的基础模型,用少量、特定领域的数据进行进一步训练。
- 学什么:学习特定任务的技能。
- 例子1:用法律条文数据微调,变成法律助手。
- 例子2:用医疗病历数据微调,变成问诊机器人。
- 例子3:用猫狗图片数据微调,变成宠物识别器。
- 特点:速度快、成本低、数据量少,普通公司甚至个人开发者都能做。
3. 为什么要用预训练模型?
- 省钱省力 (降低成本)
从头训练一个大模型可能需要数百万美元的算力费。使用预训练模型,你只需要支付微调的电费,成本可能只有原来的千分之一。 - 数据少也能行 (小样本学习)
很多特定领域(如罕见病诊断、小语种翻译)根本没有足够的数据去从头训练模型。预训练模型因为已经具备了通用知识,只需要很少的样本就能学会新任务。 - 效果更好 (迁移学习)
研究发现,经过大规模预训练的模型,其泛化能力(举一反三的能力)远强于从零训练的小模型。它把“通用知识”迁移到了新任务上。
4. 常见的预训练模型例子
你可能听过这些名字,它们本质上都是预训练模型:
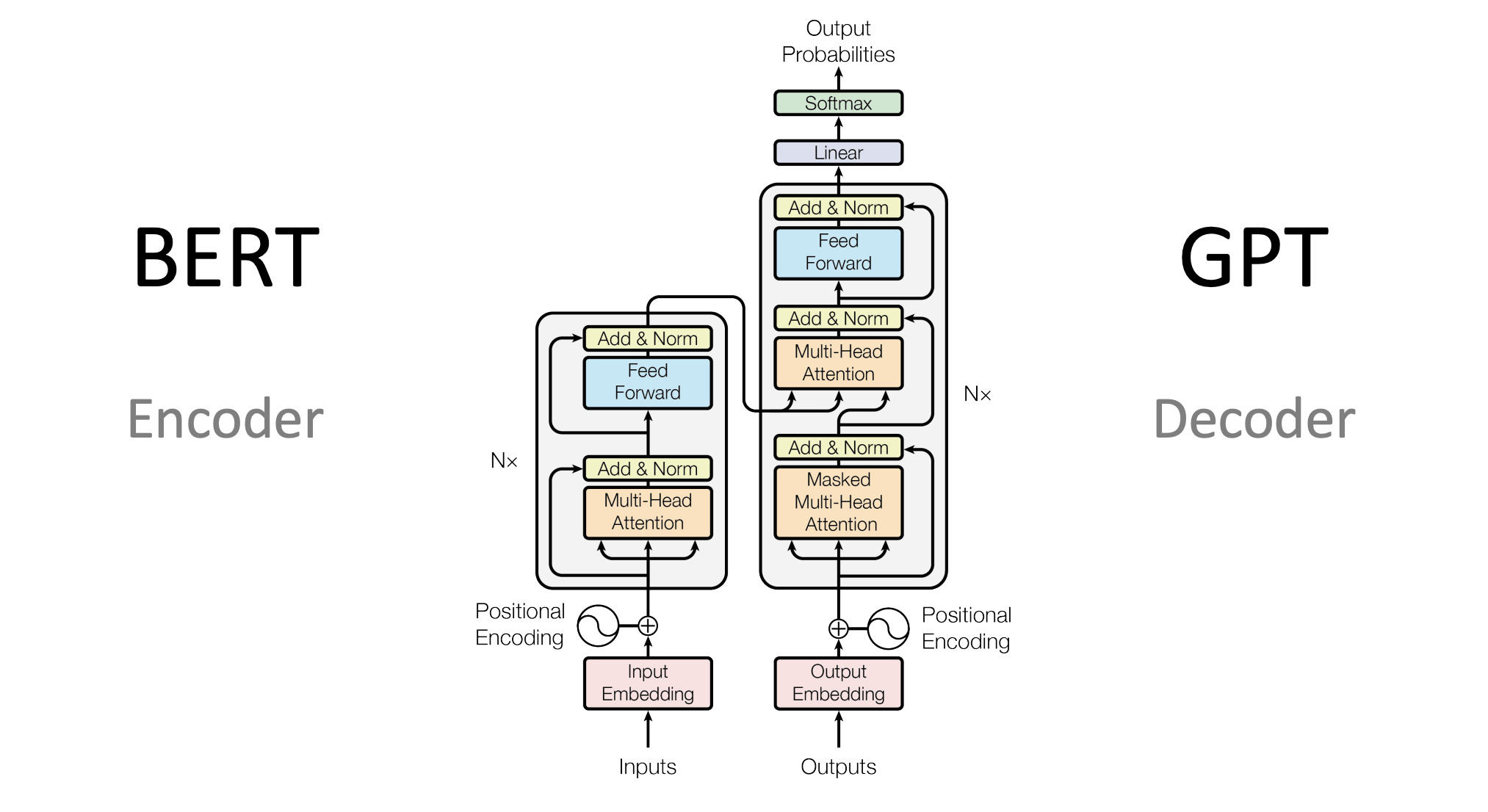
- BERT:谷歌出品,擅长理解句子含义(常用于搜索、情感分析)。
- GPT 系列:OpenAI出品,擅长生成文本(聊天、写作)。
- Llama / Qwen (通义千问):开源或国产的大语言模型基座。
- ResNet:微软出品,经典的图像识别基石。
- ViT (Vision Transformer):将Transformer架构用于图像识别。
- YOLO 系列:预训练后常用于实时的目标检测(如监控摄像头)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...