
ransformer是目前人工智能领域(尤其是大语言模型)最核心的深度学习架构。
简单来说,它是所有现代大模型(如GPT-4. Claude, Llama, Qwen等)的“发动机”。没有Transformer,就没有今天的生成式AI热潮。
1. Transformer是用来干什么的?
它的核心任务是处理序列数据(如文字、代码、音频、视频帧),并理解数据内部的长距离依赖关系。
- 传统痛点:在 Transformer 出现之前(2017 年前),主流模型是 RNN(循环神经网络)。RNN 像人读书一样,必须一个字一个字按顺序读,读到后面就忘了前面,且无法并行计算,训练极慢。
- Transformer 的突破:
- 并行计算:它可以同时“看”整句话的所有字,训练速度提升几十倍甚至上百倍。
- 长距离记忆:无论句子多长,它能直接捕捉第一个字和最后一个字的关系,解决了“读了后面忘前面”的问题。
- 通用性:最初用于翻译,现在已统摄 NLP(文本)、CV(图像)、音频甚至生物制药(蛋白质结构预测)。
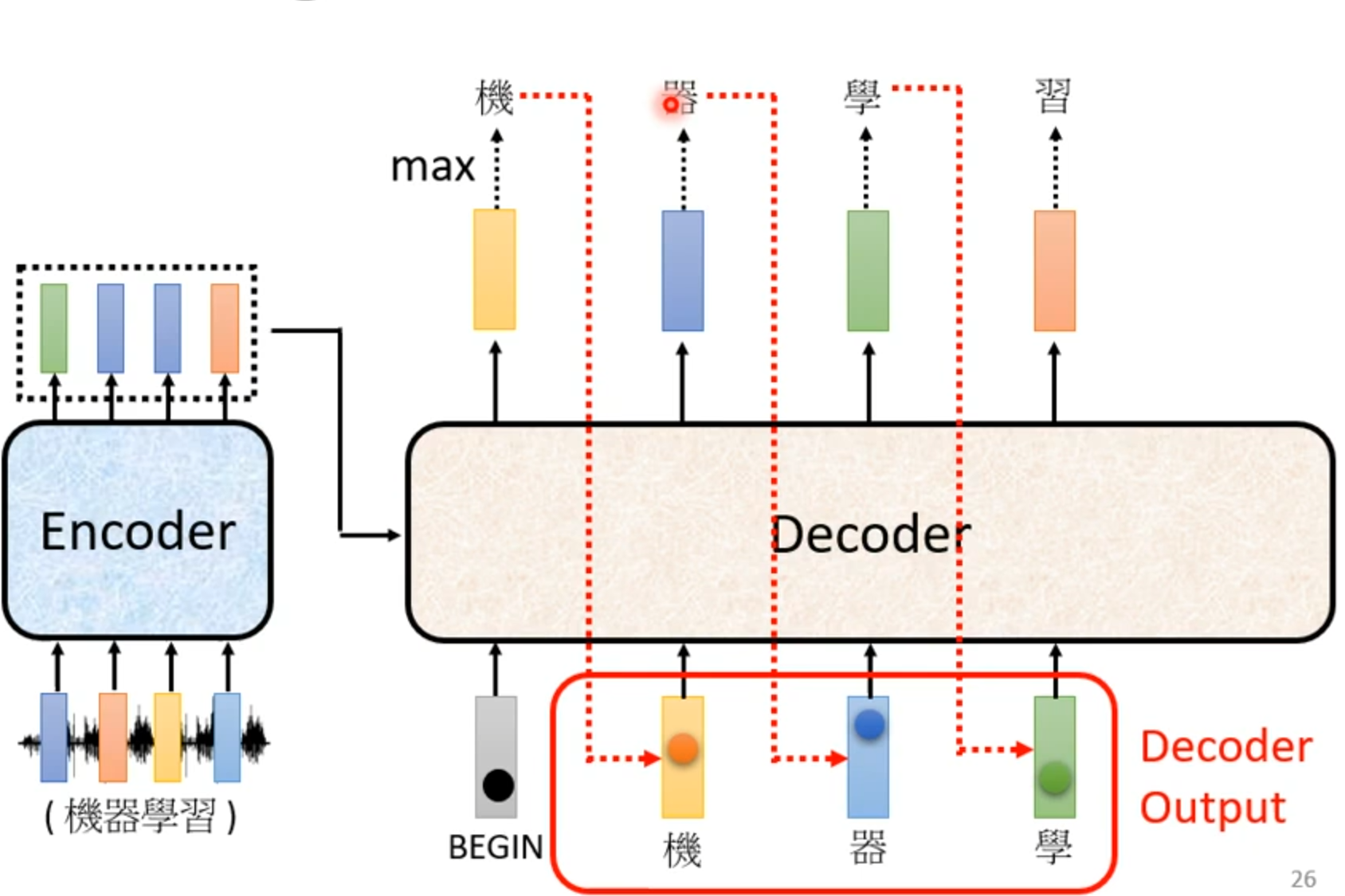
2. Transformer的核心架构
Transformer 架构由两个主要部分组成:编码器(Encoder) 和 解码器(Decoder)。但在大语言模型(LLM)中,通常只使用Decoder-only结构(如 GPT 系列)。
其核心组件包括:
A. 自注意力机制 (Self-Attention) —— 灵魂组件
这是 Transformer 最革命性的创新。
- 作用:让模型在处理每一个词时,都能“关注”到句子中其他所有词的重要性。
- 例子:在句子“它走在街上,因为它累了”中,模型需要知道两个“它”指代的是谁。自注意力机制会让“它”这个词与上下文中的名词(如“小明”或“狗”)建立强连接,从而理解指代关系。
- 原理简述:通过计算 Query (查询), Key (键), Value (值) 三个矩阵的相互作用,动态分配权重。
B. 多头注意力 (Multi-Head Attention)
- 作用:相当于让模型拥有“多双眼睛”,从不同角度同时关注信息。
- 例子:一个头关注语法结构,一个头关注指代关系,一个头关注情感色彩。最后将这些信息合并,使理解更全面。
C. 前馈神经网络 (Feed-Forward Network, FFN)
- 作用:对注意力机制提取的特征进行进一步的非线性处理和转换,相当于模型的“思考”层,增加模型的表达能力。
D. 位置编码 (Positional Encoding)
- 痛点:因为 Transformer 是并行读取所有词的,它本身不知道词的顺序(即不知道“猫吃鱼”和“鱼吃猫”的区别)。
- 解决:给每个词加上一个代表其位置的向量(如第 1 个词加向量 A,第 2 个词加向量 B),让模型感知到顺序。
E. 残差连接 (Residual Connection) & 层归一化 (Layer Norm)
- 作用:防止网络太深导致梯度消失,确保信息能顺畅地传递到深层,让训练几百层的超大模型成为可能。
3. 工作原理流程(以生成一句话为例)
假设你要让 AI 续写:“天空是__”
- 输入嵌入 (Embedding):
将“天空”、“是”转换成高维向量(数字列表)。 - 添加位置编码:
告诉模型,“天空”在第 1 位,“是”在第 2 位。 - 自注意力计算 (Self-Attention):
模型计算“是”这个词应该多关注“天空”。它会发现“是”后面的内容必须描述“天空”的属性。 - 前馈网络处理:
结合上下文信息,进行深层逻辑推理。 - 输出预测:
经过多层(比如 96 层)的重复计算,最后输出一个概率分布:- “蓝”的概率:80%
- “黑”的概率:10%
- “圆”的概率:0.1%
- 采样生成:
模型选择概率最高的“蓝”,将其作为新输入,重复上述过程预测下一个字(如“色的”),直到生成完整句子。
4. 为什么它如此重要?
- 扩展性 (Scalability):Transformer 架构极其适合堆叠算力。只要增加数据、增加参数、增加层数,模型智能就会线性甚至指数级提升(Scaling Law)。这是大模型能发展到今天万亿参数规模的根本原因。
- 统一框架:它证明了同一个架构可以处理文本、图片(Vision Transformer)、声音甚至视频,实现了真正的“多模态”统一。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...