要把自注意力机制(Self-Attention)讲得通俗易懂,我们完全可以把那些复杂的数学公式( Q,K,VQ,K,V 、矩阵乘法、Softmax)先扔到一边。
你可以把它想象成人类在阅读时的一种“本能反应”:当读到某个词时,大脑会自动把目光聚焦到句中其他相关的词上,从而理解它的真正含义。
下面用三个生活化的场景来帮你彻底搞懂它。
🌟 场景一:玩“连连看”找对象(解决指代不明)
句子:
“那只动物没有穿过街道,因为它太累了。”
问题:这里的“它”到底是指“动物”还是“街道”?
- 如果是字典查词,“它”就是个代词,没意义。
- 但人脑一读就知道:“累”的肯定是“动物”,“街道”不会累。所以“它”=“动物”。
自注意力机制是怎么做的?
想象“它”这个词是一个侦探,它手里拿着一个放大镜(Query),在句子里到处扫描:
想象“它”这个词是一个侦探,它手里拿着一个放大镜(Query),在句子里到处扫描:
- 扫描“动物”:侦探发现“动物”和“累”逻辑很通,匹配度 90%!🔴(高亮)
- 扫描“街道”:侦探发现“街道”和“累”没关系,匹配度 5%。⚪(忽略)
- 扫描“穿过”:有点关系,匹配度 20%。🔵(微亮)
结果:
当模型处理“它”这个字时,它不再是孤立的,而是“借用了”90%的“动物”的特征。
在计算机眼里,此时的“它” ≈ “那只累了的动物”。
当模型处理“它”这个字时,它不再是孤立的,而是“借用了”90%的“动物”的特征。
在计算机眼里,此时的“它” ≈ “那只累了的动物”。
通俗总结:自注意力就是让每个词都能“回头看”或“向前看”,找到句子里跟它关系最铁的“搭档”,把搭档的信息融合到自己身上。
🌟 场景二:微信群聊里的“@所有人”(解决上下文关联)
假设有一个微信群,群名是《句子》,群里有几个成员:
[我]、[爱]、[吃]、[苹果]。如果没有自注意力(像老式录音机):
大家各说各话。
大家各说各话。
苹果说:“我是水果,也是手机品牌。”(由于不知道上下文,它很迷茫,两个意思都有)。
有了自注意力(像智能群聊):
苹果发起话题:“嘿,大家谁跟我关系大?”(发出 Query 信号)吃回复:“我跟你的关系最大!因为只有水果才能被吃,手机通常不被‘吃’。”(Key-Value 匹配成功)爱回复:“我也跟你有关,但我主要修饰‘吃’。”我回复:“我是主语,跟你也有关。”
最终效果:
苹果 听到了大家的反馈,尤其是 吃 的大声疾呼。于是 苹果 在心里默默更新了自己的状态:“哦,既然吃这么强调,那我现在的身份就是100%的水果,不是手机了。”
通俗总结:自注意力机制让句子里的每个字都变成了“社交达人”,它们互相交流,根据周围人的反馈,动态确定自己当下的确切含义。
🌟 场景三:聚光灯舞台(权重的概念)
想象舞台上有一排演员,分别代表句子里的词。
导演(自注意力机制)手里有很多盏聚光灯。
导演(自注意力机制)手里有很多盏聚光灯。
当镜头要给演员 C(中心词) 特写时:
- 导演不会只照亮 C。
- 导演会根据剧情,把最亮的光打在跟 C 关系最好的演员 A 身上。
- 把微弱的光打在关系一般的演员 B 身上。
- 把光关掉打在无关的演员 D 身上。
最后摄像机拍出来的画面(生成的向量),是所有演员被光照亮部分的叠加。
- 因为 A 的光最亮,所以画面里主要呈现的是 A 的特征。
- 这就解释了为什么计算机能“加权”:重要的信息权重高,不重要的权重低。
💡 核心三问三答(极简版)
为了让你记得更牢,我们用最简单的话回答三个核心问题:
1. 为什么要叫“自”注意力?
- 答:因为它是自己关注自己所在的这个句子。不是拿这篇文章去关注那篇文章,而是让句子里的“我”去关注句子里的“你”和“他”,内部消化,自我理解。
2. 它解决了什么痛点?
- 答:解决了“距离远就忘”和“一词多义”的问题。
- 以前(RNN模型):读到句尾忘了句首。
- 现在(自注意力):无论相隔多远,只要关系铁,瞬间就能“连线”。
- 以前:“银行”不知道是存钱的地方还是河岸。
- 现在:看到旁边的“钱”,立马知道是存钱的地方。
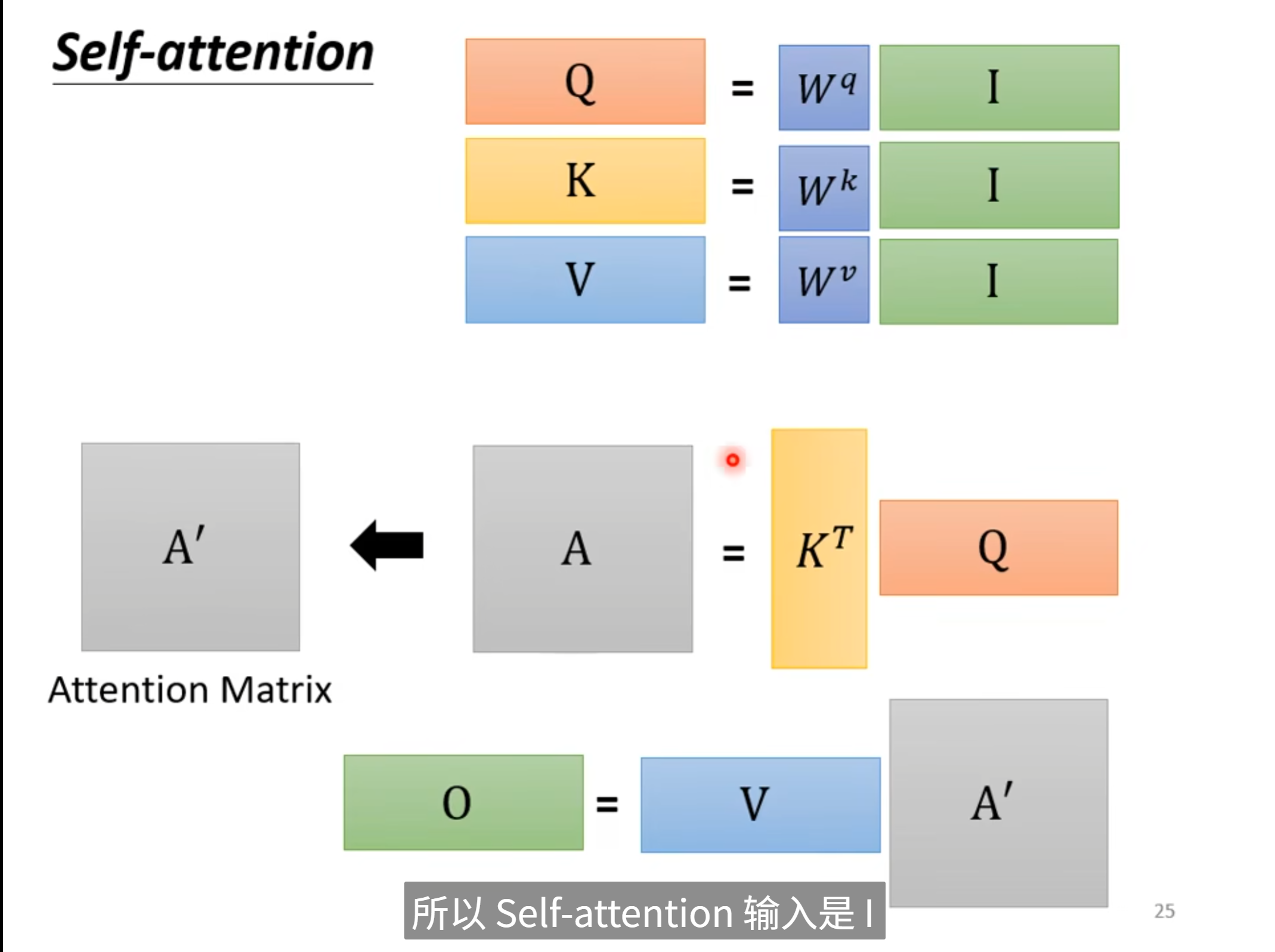
3. 它是怎么做到的?(QKV大白话版)
- Query (Q) = 搜索词(我想找谁?)
- Key (K) = 标签(我是谁?)
- Value (V) = 内容(我具体是什么?)
- 过程:拿着搜索词去匹配所有人的标签,匹配度高的,就把他的内容拿过来用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...