
大模型解码器(Decoder) 是大语言模型(LLM)和序列生成任务中的核心组件,主要负责根据已生成的内容和上下文信息,预测并生成下一个词(Token),从而逐步构建出完整的输出序列。
在现代大模型架构(尤其是基于Transformer的模型)中,解码器的作用至关重要。
1. 什么是大模型解码器?
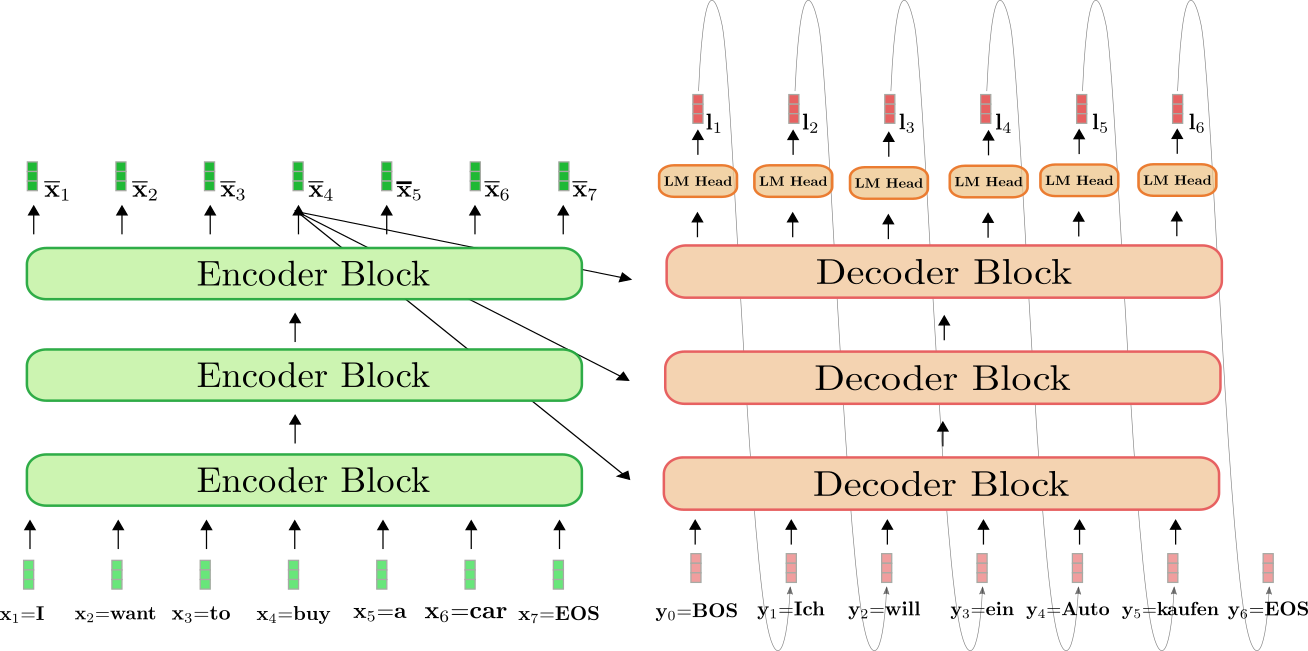
- 编码器:负责“理解”输入,将输入序列(如一句话、一篇文章)转换为富含语义信息的向量表示。
- 解码器:负责“生成”输出,利用编码器提供的信息(或在纯解码模型中利用自身历史信息),自回归地生成目标序列。
注意:目前主流的大语言模型(如LLaMA、GPT 系列、PaLM 等)大多采用 “Decoder-only”(纯解码器) 架构。这意味着它们去掉了编码器,直接让解码器同时承担理解输入和生成输出的任务,这种架构在通用文本生成任务上表现更为高效和强大。
2. 解码器的核心作用
解码器的主要作用可以概括为以下几点:
A. 序列生成(自回归生成)
这是解码器最本质的功能。它不是一次性生成所有结果,而是逐个词(Token-by-Token)地生成:
- 接收一个起始符号(如
<bos>)或已有的部分序列。 - 预测下一个最可能的词。
- 将预测出的词追加到序列末尾,作为新的输入。
- 重复上述过程,直到生成结束符号(如
<eos>)或达到长度限制。
B. 掩码自注意力机制(Masked Self-Attention)
为了防止“作弊”(即在预测当前词时偷看到未来的词),解码器引入了掩码(Masking)机制:
- 在计算注意力时,当前位置只能关注到它之前的位置,无法关注到后续位置。
- 作用:确保了生成的因果性(Causality),即模型只能根据“过去”和“现在”的信息来预测“未来”,这符合自然语言生成的逻辑。
C. 上下文融合(在 Encoder-Decoder 架构中)
在机器翻译等任务的传统架构中,解码器还包含一个交叉注意力(Cross-Attention)层:
- 它将解码器当前的状态与编码器输出的源序列信息进行融合。
- 作用:确保生成的每一个词都紧密结合原始输入的含义(例如,翻译时确保译文忠实于原文)。
- 注:在 Decoder-only 架构的大模型中,输入提示(Prompt)和待生成的内容被视为同一个长序列,通过自注意力机制统一处理,不再需要独立的交叉注意力层。
D. 概率分布预测
解码器的最后通常包含一个线性层和一个Softmax函数:
- 它将内部的高维向量映射到词汇表大小的维度。
- 输出一个概率分布,表示词汇表中每个词作为下一个词的可能性。
- 模型根据这个分布采样或选择概率最高的词作为输出。
3. 工作流程简述
以一个简单的对话生成任务为例,解码器的工作流程如下:
- 输入:用户输入“你好,今天天气”。
- 嵌入与位置编码:将文字转换为向量,并加上位置信息。
- 多层处理:
- 数据流经多层解码器块(每层包含掩码自注意力、前馈神经网络等)。
- 在每一层,模型学习词语之间的依赖关系(例如,“天气”这个词会让模型倾向于预测“好”、“坏”、“晴朗”等)。
- 预测:最后一层输出向量经过分类器,计算出下一个词是“怎么”的概率最高。
- 循环:将“怎么”加入序列,再次输入解码器,预测下一个词(如“样”),如此循环直到句子结束。
小编概括一下
大模型解码器本质上是一个条件概率生成器。它的核心使命是在保证因果律(不看未来)的前提下,利用已有的上下文信息,高质量地预测下一个语言单元。正是解码器的这种自回归生成能力,使得大模型能够写文章、写代码、回答问题以及进行多轮对话。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...