大模型分词器(Tokenizer) 是大型语言模型(LLM)的“翻译官”和“预处理引擎”。它的核心作用是将人类可读的自然语言文本(字符串),转换为模型能够理解和计算的数字序列(词元 IDs),以及在模型生成数字后,将其还原为人类可读的文本
如果没有分词器,大模型就无法“阅读”任何文字。
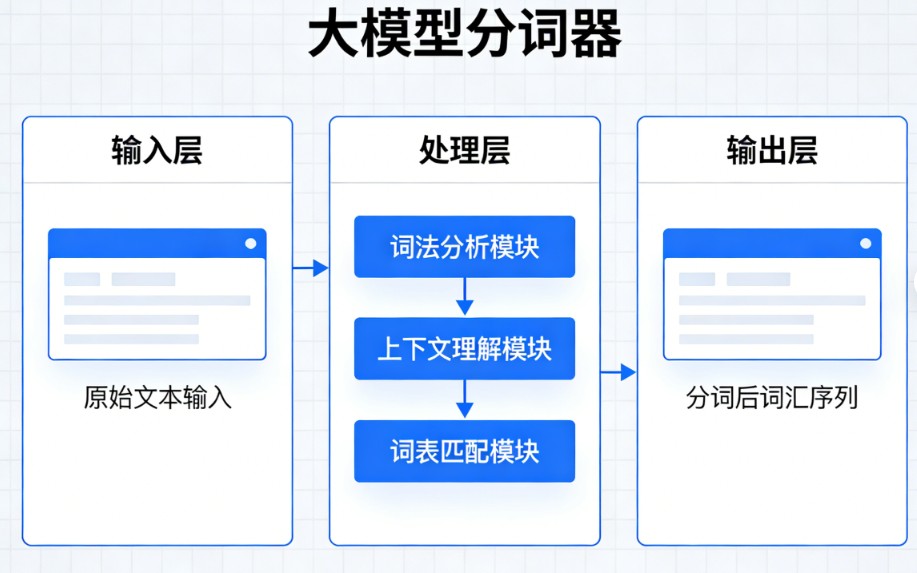
1. 核心功能:双向转换
分词器主要执行两个相反的过程:
- 编码(Encoding / Tokenization):
- 输入:人类语言(如:“你好,世界”)。
- 过程:
- 切分:根据特定规则将文本切分成一个个“词元”(Tokens)。
- 映射:在模型的“词汇表”(Vocabulary)中查找每个词元对应的唯一数字编号(ID)。
- 输出:数字序列(如:
[1523, 408, 99, 2045])。模型实际处理的就是这些数字。
- 解码(Decoding / Detokenization):
- 输入:模型预测生成的数字序列。
- 过程:根据词汇表将数字反向查找回对应的词元字符串,并按规则拼接。
- 输出:人类可读的文本。
2. 关键组成部分
一个分词器通常包含两个核心要素:
- 词汇表(Vocabulary):
- 这是一个巨大的列表,包含了模型认识的所有“词元”及其对应的 ID。
- 例如:
"hello" -> 5025,"ing" -> 328,"" -> 101。 - 不同模型的词汇表大小不同(常见的有 3万、5万、10万甚至更多)。词汇表越大,能直接表示的完整单词越多,但模型参数量也会相应增加。
- 分词算法(Algorithm):
- 决定了如何将未见过的词拆解为词汇表中已有的片段。主流算法包括:
- BPE (Byte-Pair Encoding):通过统计字符共现频率,将频繁出现的字符对合并。这是 GPT 系列、Llama 系列使用的经典算法。
- WordPiece:Google BERT 模型使用的算法,倾向于保留完整的词根。
- Unigram / SentencePiece:常用于多语言模型,不依赖空格分词,对中文等无空格语言更友好。
- 决定了如何将未见过的词拆解为词汇表中已有的片段。主流算法包括:
3. 为什么分词器如此重要?
- 决定模型的“识字量”:
如果分词器的词汇表中没有某个词(比如一个新的人名或专业术语),它必须将其拆分成更小的碎片。拆分得越碎,模型理解该词的含义就越困难,生成的序列也越长。 - 影响效率与成本:
- 压缩率:优秀的分词器能用更少的词元表达相同的意思。例如,对于英文常用词,好的分词器可能用一个词元表示整个单词;差的可能需要拆成 3-4 个。词元越少,推理速度越快,API 调用成本越低。
- 多语言能力:早期的分词器对英文优化很好,但对中文、阿拉伯文等支持较差(导致中文被拆成单字,序列极长)。现代大模型(如 Llama 3, Qwen)都在大幅扩充词汇表以提升多语言效率。
- 处理特殊字符与边界情况:
分词器还负责处理空格、标点、换行符以及未知字符(通常用 “ 表示),确保模型不会因非法输入而崩溃。
4. 举个具体的例子
假设我们有一个简化的分词器,词汇表包含:
["I", " love", " AI", "ing", ""]。- 输入句子:”I loving AI”
- 分词过程:
I-> 匹配到"I"(空格) +loving-> 词汇表里没有loving,但有love和ing。于是拆分为" love"+"ing"。(空格) +AI-> 匹配到" AI"。
- 最终词元序列:
["I", " love", "ing", " AI"](共4个词元) - 对应的数字 ID:
[101, 205, 309, 412](假设值)
小编最后归纳一下
大模型分词器是连接人类语言世界与机器数学世界的桥梁。 它不仅决定了模型如何“看”懂文字,还直接影响着模型的智能表现、运行速度以及跨语言的能力。不同的模型(如GPT-4, Claude, Llama 3)都拥有自己专属训练的分词器,这也是为什么同一个句子在不同模型中计算出的 Token 数量往往不同的原因。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...