
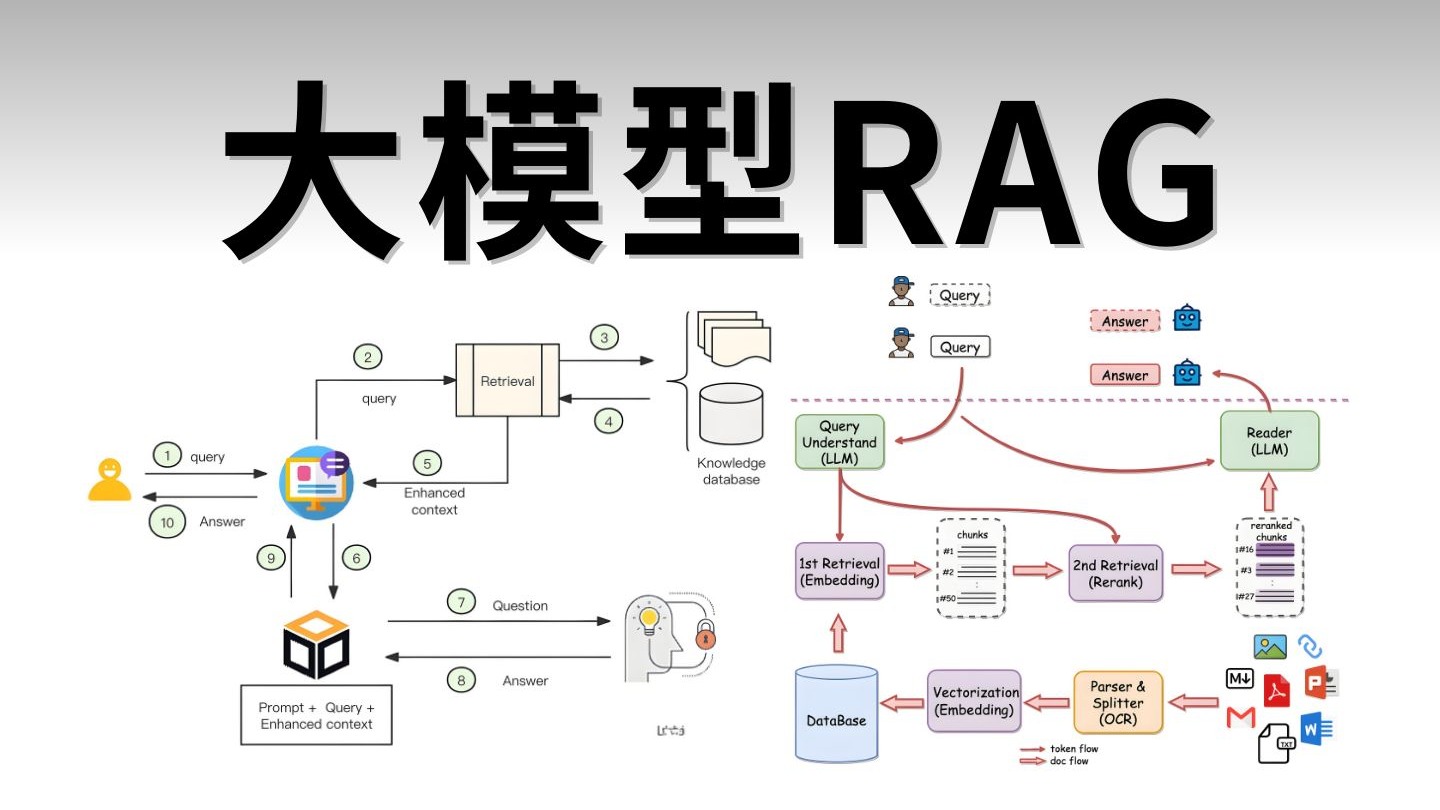
大模型RAG是Retrieval-Augmented Generation(检索增强生成)的缩写。
简单来说,它是一种让大模型在回答问题时,不再仅靠“死记硬背”的训练数据,而是先像查字典一样去外部知识库中检索相关信息,再结合检索到的内容生成答案的技术架构。
如果把大模型比作一个博学的学者,RAG就是给这位学者配了一位图书管理员。当学者遇到不懂或需要最新数据的问题时,图书管理员会迅速从图书馆(外部数据库)找出相关资料递给学者,学者基于这些资料给出准确回答,而不是凭空捏造。
大模型RAG系统的核心作用
- 问题:大模型有时会“一本正经地胡说八道”(即幻觉),尤其是在面对它不知道的事实或复杂逻辑时。
- RAG的作用:通过强制模型基于检索到的真实文档片段(Context)来生成答案,极大地减少了虚构事实的概率。模型必须“有据可依”,从而显著提升回答的可信度。
2. 突破知识时效性,实现实时更新
- 问题:大模型的知识截止于训练结束的那一天(例如某模型只学到2023年的数据),无法知道昨天发生的新闻或最新的股价。重新训练模型成本极高且周期长。
- RAG的作用:只需更新外部知识库(如上传最新的新闻文档、公司财报),模型就能立即利用这些新信息回答问题,无需重新训练。这让大模型具备了“与时俱进”的能力。
3. 激活私有数据,保障数据安全
- 问题:企业内部的文档、代码库、客户记录等私有数据,不可能全部拿去训练公共大模型(存在泄露风险且成本高昂)。
- RAG的作用:企业可以将私有数据存储在本地安全的向量数据库中。当员工提问时,RAG系统只在内部检索权限允许的数据,并将其作为上下文传给模型。这样既利用了大模型的推理能力,又确保了数据不出域,实现了私有化部署下的智能问答。
4. 提供可追溯的来源(引用依据)
- 问题:普通大模型生成的答案通常无法告诉用户“这句话是从哪来的”。
- RAG的作用:RAG系统可以在生成答案的同时,标注出引用的具体文档段落或来源链接。这对于法律、医疗、金融等需要严谨依据的场景至关重要,用户可以点击溯源验证信息的真实性。
5. 降低长上下文成本
- 问题:虽然现在的模型支持超长上下文(如100万字),但将所有知识库内容一次性塞入提示词(Prompt)不仅昂贵,而且会干扰模型的注意力,导致“迷失中间”现象。
- RAG的作用:RAG只检索与当前问题最相关的少量片段(例如几段文字)喂给模型。这大大减少了输入令牌(Token)的数量,降低了推理成本,同时让模型更聚焦于关键信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...