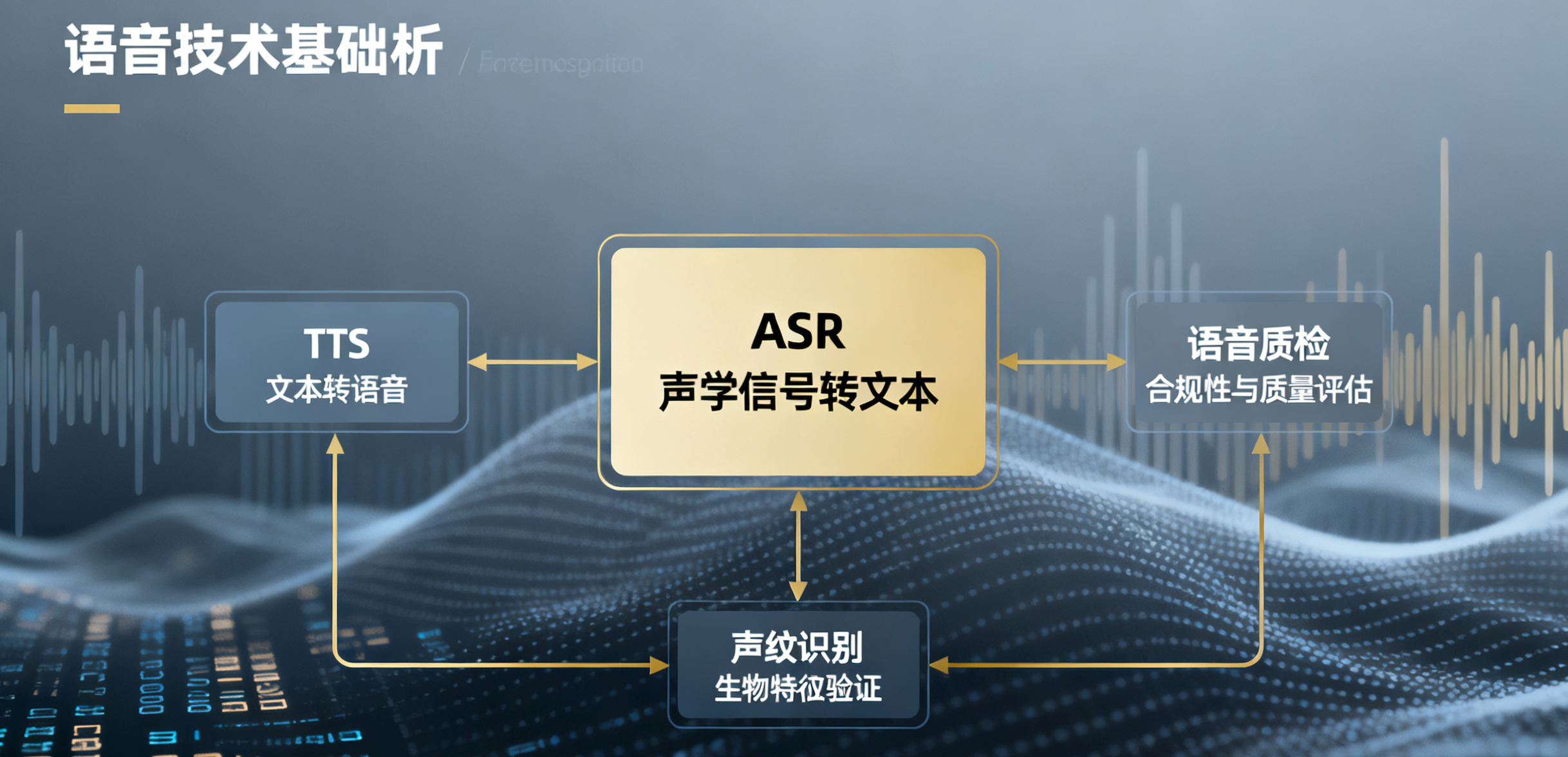
ASR语音识别技术(Automatic Speech Recognition,自动语音识别)是一种将人类的口语语音自动转换为书面文字的计算机技术。
如果说TTS(文本转语音)是让机器“开口说话”,那么ASR就是让机器“听懂人话”。它是人机交互(HCI)中至关重要的入口技术,广泛应用于智能助手、会议记录、字幕生成等场景。
核心工作原理
现代ASR系统通常基于深度学习模型,其处理流程大致分为以下几个阶段:
- 信号处理与特征提取:
- 系统首先接收音频信号,进行降噪、回声消除等预处理。
- 然后将声波转换为计算机可处理的数字特征(如梅尔频率倒谱系数 MFCCs 或梅尔频谱图),提取声音的频率、能量等关键信息。
- 声学模型 (Acoustic Model):
- 这是ASR的核心组件之一。它的作用是建立“声音特征”与“发音单元”(如音素、音节)之间的映射关系。
- 例如,它学习识别出某段波形对应的是拼音中的“b”还是“p”,或者是英语中的“cat”还是“bat”。
- 现代主流技术使用深度神经网络 (DNN)、卷积神经网络 (CNN) 或 Transformer 架构来处理这一任务。
- 语言模型 (Language Model):
- 声学模型只能猜出“听起来像什么”,但往往会有歧义(例如“公式”和“公事”发音相同)。
- 语言模型利用大量的文本数据训练,根据上下文概率来判断哪个词更合理。它会告诉系统:“在‘解决数学___’这个语境下,‘公式’比‘公事’的概率大得多”。
- 解码器 (Decoder):
- 综合声学模型和语言模型的输出,搜索出概率最高的词序列,最终生成完整的文本句子。
主要应用场景
- 智能语音助手:Siri、小爱同学、Google Assistant 等理解用户指令的基础。
- 实时字幕与翻译:视频会议(如Zoom、腾讯会议)的实时字幕生成,以及语音翻译软件。
- 语音输入法:微信、搜狗输入法中的“按住说话转文字”功能。
- 客服与质检:自动记录客服电话内容,并分析服务质量或提取关键信息。
- 医疗与法律记录:医生口述病历、律师口述文书的自动转录,大幅提高效率。
- 智能家居控制:通过语音命令控制灯光、空调等设备。
技术挑战与发展趋势
尽管现在的ASR技术在安静环境下准确率极高(甚至超过人类),但仍面临一些挑战:
- 噪音环境:在嘈杂的街道或多人同时说话(鸡尾酒会效应)时,识别率会下降。
- 口音与方言:对重口音、方言或混合语言(Code-switching)的识别仍需优化。
- 专业术语:在医疗、法律等垂直领域,通用模型可能无法准确识别生僻的专业词汇。
当前趋势:
目前的顶尖ASR系统(如OpenAI的Whisper、谷歌的Universal Speech Model)正朝着端到端 (End-to-End) 方向发展,即用一个巨大的神经网络直接完成从音频到文字的转换,不再需要繁琐的分模块处理。同时,大语言模型 (LLM) 的引入也极大地增强了语言模型的理解能力,使得识别结果更符合逻辑和语境。
目前的顶尖ASR系统(如OpenAI的Whisper、谷歌的Universal Speech Model)正朝着端到端 (End-to-End) 方向发展,即用一个巨大的神经网络直接完成从音频到文字的转换,不再需要繁琐的分模块处理。同时,大语言模型 (LLM) 的引入也极大地增强了语言模型的理解能力,使得识别结果更符合逻辑和语境。
ASR 与 TTS 的关系
它们通常是互补的:
- ASR:语音 → 文字(输入)
- NLP (自然语言处理):文字 → 理解/生成回复(处理)
- TTS:文字 → 语音(输出)
这三者结合,就构成了一个完整的智能语音对话系统。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...