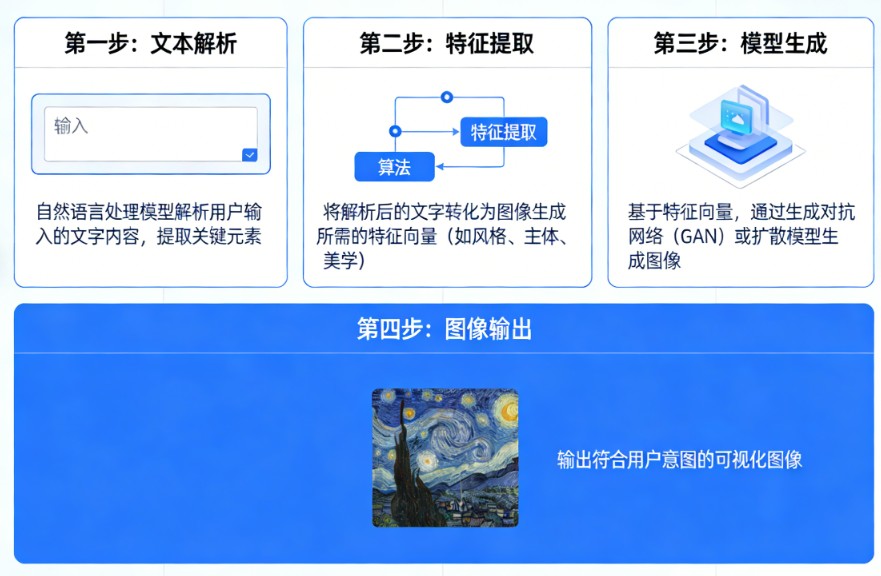

核心原理
文生图系统通常基于深度学习模型,尤其是扩散模型(Diffusion Models)或生成对抗网络(GANs)。其工作流程大致如下:
- 生成图像:
基于这个语义向量,图像生成模型(如Stable Diffusion、DALL·E、Midjourney等)从随机噪声开始,逐步“去噪”并优化像素,最终生成一张与文字描述高度匹配的图像。 - 风格控制(可选):
用户还可以在提示词中指定艺术风格,如“水彩画”、“赛博朋克”、“梵高风格”、“3D 渲染”等,AI 会据此调整画面的表现形式。
典型应用场景
- 创意设计:快速生成概念图、海报、插画灵感。
- 游戏/影视制作:生成角色设定、场景草图、道具参考。
- 广告营销:定制化视觉内容,如产品展示图。
- 教育科普:将抽象概念可视化(如“黑洞吸积盘”、“细胞分裂过程”)。
- 个人娱乐:创作幻想生物、梦境场景、AI艺术作品。
使用示例
如果你输入:
“一只戴着墨镜的柴犬,坐在复古咖啡馆里喝拿铁,窗外下着雨,电影《爱在黎明破晓前》风格,胶片摄影”
AI就可能生成一张充满文艺氛围、细节丰富的图像。
注意事项
- 提示词质量决定结果:描述越具体、关键词越清晰(主体+动作+环境+风格+光照等),生成效果越好。
- 存在局限性:AI可能误解复杂逻辑(如左右手混淆)、文字渲染错误(图像中出现乱码文字)、或生成不符合物理规律的画面。
- 版权与伦理:生成内容的版权归属、是否模仿特定艺术家风格等问题仍在讨论中。
如今,文生图已成为AIGC(人工智能生成内容)领域最热门的应用之一,让普通人也能轻松实现“所想即所见”的视觉创作。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...