
扩散模型(Diffusion Models)是目前人工智能领域,特别是生成式AI(AIGC)中最核心、最主流的算法架构之一。
简单来说,它的核心用途是:从随机噪声中“变”出高质量的数据(如图片、音频、视频、3D模型等)。
目前它最著名的应用就是文生图(如Midjourney, Stable Diffusion, DALL-E 3),但它的能力远不止于此。
1. 核心原理:像“倒放”的破坏过程
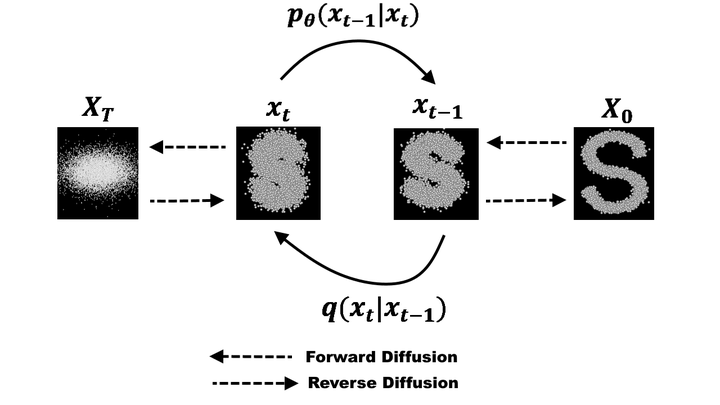
扩散模型的灵感来源于物理学中的热力学扩散过程。你可以把它想象成两个相反的过程:
- 前向过程(加噪/破坏):
想象一张清晰的照片,我们不断地往上面撒“噪点”(随机干扰)。随着噪点越来越多,照片逐渐变得模糊,最后完全变成一团毫无意义的随机雪花点(高斯噪声)。这个过程是固定的、可计算的。 - 反向过程(去噪/生成):
这是扩散模型真正工作的地方。我们要训练一个神经网络,让它学会“倒放”上述过程。- 给模型看一团随机噪声。
- 模型预测:“这团噪声里可能隐藏着什么?如果我去掉一点点噪点,它应该长什么样?”
- 模型执行去噪,得到稍微清晰一点的图像。
- 重复这个步骤几十次甚至上千次,直到噪声完全消失,一张清晰、逼真的图像就诞生了。
关键点:在生成过程中,我们会给模型一个条件(比如一段文字描述“一只猫”),模型就会朝着“猫”的方向去去除噪声,最终生成一只猫的图片。
2. 主要用途与应用场景
虽然扩散模型最初是为了生成图像而爆发的,但现在它的应用范围非常广:
A. 图像生成与编辑(最成熟的应用)
- 文生图:输入文字,生成逼真或艺术风格的图片(Stable Diffusion, Midjourney, DALL-E 3)。
- 图生图:根据一张草图生成成品图,或者改变原图的风格(如把照片变成油画)。
- 图像修复(Inpainting):擦除图片中不需要的物体(如路人),并自动补全背景,效果比传统修图软件自然得多。
- 超分辨率:将模糊的小图放大并补充细节,使其变清晰。
B. 视频生成
- 文生视频:根据文字描述生成一段短视频(如Sora, Runway Gen-2, Pika)。原理是将扩散过程扩展到时间维度,保证帧与帧之间的连贯性。
- 视频插帧/修复:让低帧率视频变流畅,或修复老电影。
C. 音频与音乐生成
- 语音合成:生成极具情感的人类语音(部分先进TTS系统开始采用扩散模型)。
- 音乐创作:根据风格描述生成完整的音乐片段(如MusicLM, AudioLDM)。
- 音效设计:生成特定的环境音(如“雨声”、“脚步声”)。
D. 3D内容与科学领域
- 3D 模型生成:直接从文本或单张图片生成3D物体模型,用于游戏和虚拟现实。
- 药物研发:在生物领域,扩散模型被用来生成新的蛋白质结构或分子结构,加速新药发现。
3. 为什么扩散模型这么火?
在扩散模型流行之前,主流是GAN(生成对抗网络)。扩散模型之所以能取代GAN成为霸主,主要有以下优势:
- 训练更稳定:GAN的训练非常困难,容易出现模式崩溃(生成的图都长得一样)或训练不收敛。扩散模型的训练过程相对平稳,更容易成功。
- 生成质量更高:扩散模型生成的图像细节更丰富,纹理更真实,尤其是在高分辨率图像上表现优异。
- 多样性更好:它能覆盖数据分布的更多部分,生成的图片种类更丰富,不容易重复。
- 可控性强:更容易通过提示词(Prompt)或其他条件(如边缘图、深度图)来精确控制生成结果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...