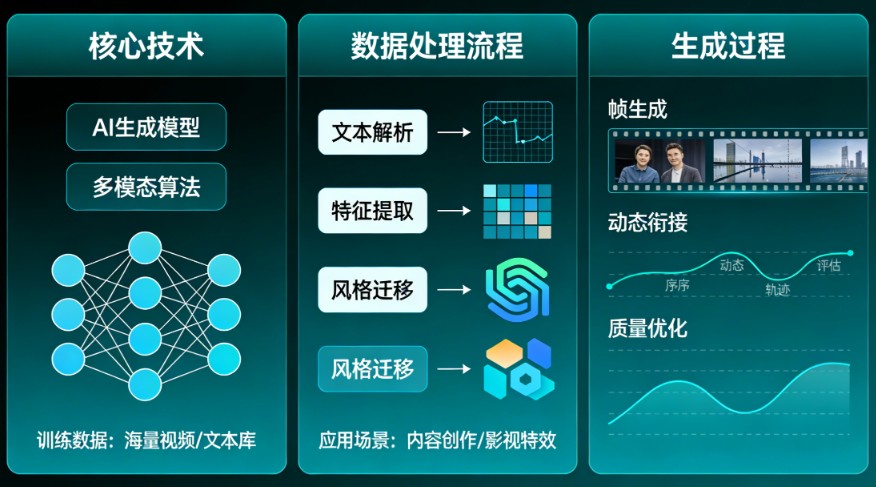
1. 核心工作原理
- 理解文字:模型首先分析你输入的文字(例如:“一只穿着宇航服的猫在月球上打篮球,背景是蓝色的地球”),理解其中的主体、动作、环境和风格。
- 时空生成:与“文生图”只生成一张静态图片不同,文生视频模型需要同时处理空间(画面长什么样)和时间(画面如何随时间变化)。它需要预测第一帧是什么样子,第二帧物体移动到了哪里,光影如何变化,并确保几十帧甚至上千帧画面连贯流畅,不出现闪烁或变形。
- 输出视频:最终合成一段符合描述的动态视频文件(如MP4)。
2. 它能做什么?
文生视频正在彻底改变视频内容的生产方式:
- 影视制作:
- 概念预演:导演可以快速生成电影分镜或概念片,无需搭建昂贵实景。
- 特效生成:直接生成爆炸、魔法、科幻场景等难以实拍的画面。
- 空镜头补充:快速生成风景、城市全景等过场镜头。
- 广告营销:
- 商家可以低成本生成大量不同风格的广告素材,进行A/B测试。
- 为产品定制专属的创意短视频。
- 社交媒体与自媒体:
- 博主无需拍摄设备,仅凭创意文案即可制作高质量的科普、故事类视频。
- 将小说、新闻文章直接转化为短视频。
- 教育与培训:
- 将抽象的历史事件、科学原理(如“细胞分裂过程”)直观地演示出来。
- 游戏开发:
- 动态生成游戏过场动画或实时生成的背景环境。
3. 代表性模型
这一领域发展极快,目前全球和中国都有顶尖模型:
- 国际代表:
- Sora (OpenAI):以超长时长(可达1分钟以上)和极高的物理模拟真实感著称。
- Runway Gen-3 / Gen-4:在专业视频编辑和控制性方面表现优异。
- Pika:擅长动画风格和特定动作控制。
- 中国代表:
- 可灵 (Kling):快手推出,以高清晰度、长时长和对中文语境的理解见长。
- 即梦 (Dreamina):字节跳动旗下,生成效果细腻,生态整合度高。
- Vidu:清华团队孵化,强调生成速度和一致性。
4. 与“文生图”的区别
5. 当前面临的挑战
虽然进步巨大,但目前的文生视频技术仍有一些局限:
- 物理逻辑错误:有时会出现反重力、物体穿模、人物肢体扭曲等不符合物理规律的现象。
- 时长限制:虽然能生成更长的视频,但保持长时间剧情逻辑连贯依然很难。
- 可控性:精确控制摄像机的运镜(如“缓慢推近”、“环绕拍摄”)或特定角色的复杂动作,仍需进一步打磨。
- 版权与伦理:生成的视频可能涉及肖像权侵权,或被用于制作虚假新闻(Deepfake)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...