
TurboQuant是谷歌研究院(Google Research)于 2026年3月发布的、面向高维向量的无训练、近无损、极低比特向量量化算法,核心用于大语言模型(LLM)的KV缓存压缩与向量数据库检索。
它通过PolarQuant + QJL双阶段数学框架,将传统 16/32bit 向量压到 2–4bit 级别,几乎零精度损失、零额外量化常数开销,并显著提速推理。
一、算法定位与背景
- 解决痛点:LLM 长上下文推理时,KV 缓存(Key-Value Cache) 占用显存爆炸(上下文越长、并发越高越严重)。
- 传统量化缺陷:
- 需要预训练 / 校准数据集、依赖数据分布
- 必须存储缩放因子 / 零点等全精度量化常数(每值额外 1–2bit 开销)
- 低比特下内积(注意力分数)偏差大、精度雪崩
- TurboQuant 定位:
- 数据无关(data-oblivious):无需训练、无需校准集、即插即用
- 近理论最优:失真率接近香农下界(仅差常数因子 ≈2.7)
- 主用于:LLM KV 缓存压缩、向量检索(ANN)
二、核心原理:PolarQuant + QJL 两阶段压缩
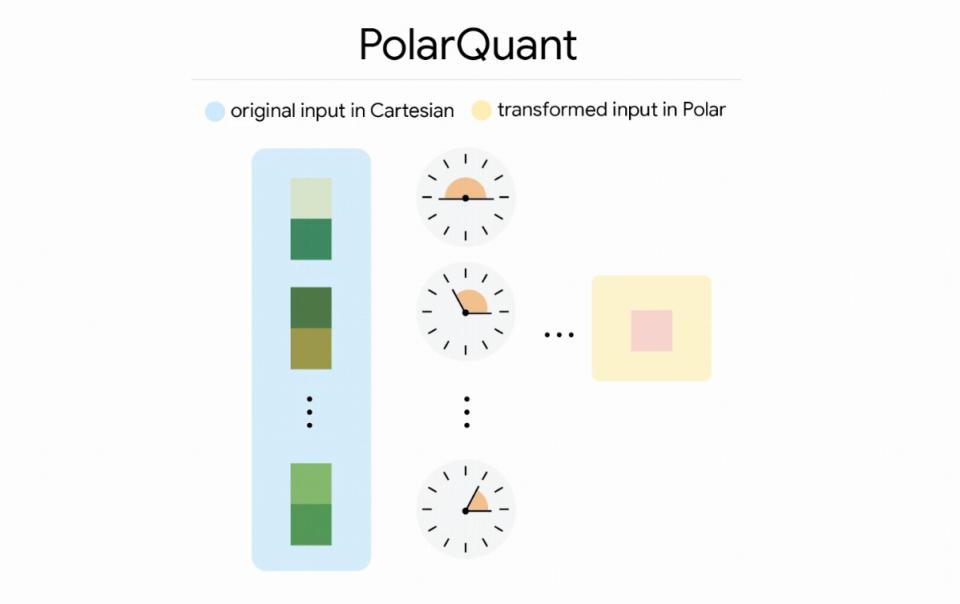
1. 第一阶段:PolarQuant(主压缩,MSE 最优)
目标:用极坐标消除归一化开销,实现高效主压缩。
- 随机正交旋转(白化)
- 对高维向量做 Haar 分布随机正交旋转
- 数学效果:旋转后坐标分布趋近 Beta / 高斯、分量近似独立
- 工程效果:能量均匀分布,标量量化接近最优
- 极坐标转换(PolarQuant)
- 把笛卡尔坐标 (x₁,x₂,…,x_d) → 分组转为 (半径 r, 角度 θ)
- 半径 r:向量模长(表征强度)
- 角度 θ:方向 / 语义(高维下角度分布高度集中、范围已知)
- 无归一化标量量化
- 角度 θ 范围固定 → 无需存储缩放 / 零点
- 直接对角度做均匀标量量化(Lloyd-Max)
- 核心突破:彻底消除传统量化的 1–2bit / 值额外开销
2. 第二阶段:QJL(1bit 残差校正,内积无偏)
问题:PolarQuant 低比特下会引入内积系统性偏差(注意力分数不准)。
方案:Quantized Johnson-Lindenstrauss(QJL)
- 提取 PolarQuant 后的残差向量
- 对残差做 JL 降维 + 1bit 量化(仅存 ±1 符号)
- 用无偏内积估计器:
- 用高精度查询向量 Q 与 压缩键向量 K 混合计算
- 数学上保证:整体内积估计无偏、零额外内存开销
最终效果:
- 主信息:PolarQuant(2–3bit)
- 残差校正:QJL(1bit)
- 总比特:≈3bit / 向量
三、核心特点
- 完全无训练、数据无关
- 无需校准集、无需微调、无需代码书学习
- 即插即用,在线实时量化
- 零额外量化常数开销
- 不存缩放、零点、范围参数
- 每比特都用于有效信息,压缩效率最大化
- 内积无偏 + 近无损精度
- 数学保证内积估计无偏
- 长上下文 “大海捞针” 等基准 零精度损失
- GPU 友好、高并行
- 全向量 / 矩阵运算,无串行搜索
- 极适合 CUDA/TPU 加速
- 理论最优性
- 失真率逼近信息论下界(差小常数 ≈2.7)
- 全比特宽度、全维度下近最优
四、核心功能与性能
- KV 缓存压缩
- 16/32bit → 3bit 级别
- 压缩比 ≥6×(内存占用降至 1/6)
- 推理速度
- H100 GPU:4bit TurboQuant 比 32bit 快 4–8×
- 精度
- 长上下文、对话、阅读理解等:零损失
- 适用场景
- LLM 长上下文推理(128K+/1M tokens)
- 高并发 LLM 服务
- 向量数据库 / 检索(ANN)压缩
- 多模态特征(图像 / 音频嵌入)量化
五、相比传统量化:核心优势
表格
| 特性 | 传统向量量化(PQ/FP8) | TurboQuant |
|---|---|---|
| 训练 / 校准 | 需要(数据依赖) | 无需(数据无关) |
| 额外开销 | 1–2bit / 值(存缩放 / 零点) | 0bit(无归一化参数) |
| 最低比特 | 4–8bit(再低精度崩) | 2–3bit(仍无损) |
| 内积偏差 | 有(系统偏差) | 数学无偏 |
| GPU 并行 | 差(多查表 / 搜索) | 极佳(纯向量运算) |
| LLM KV 效果 | 压缩有限、易掉点 | 6× 压缩、8× 加速、零损 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...