
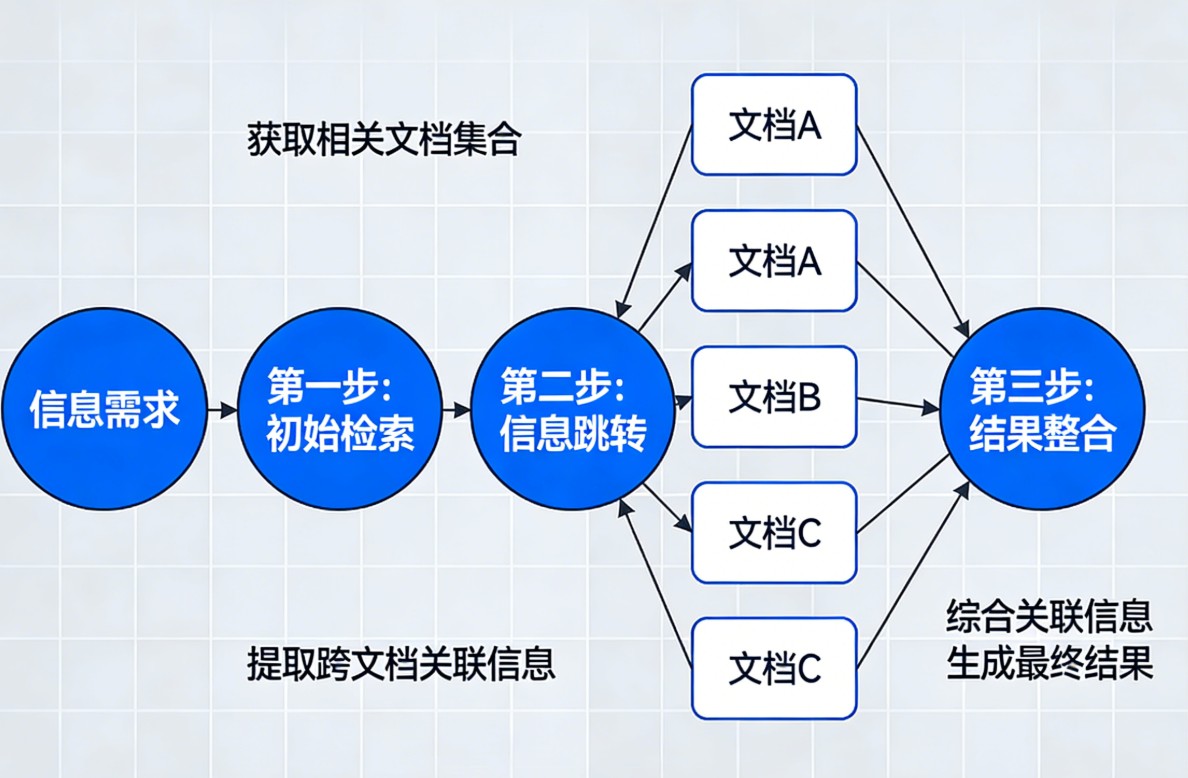
多跳检索(Multi-hop Retrieval)是一种高级的检索增强生成(RAG)技术,旨在解决那些无法通过单次查询直接回答的复杂问题。
如果说普通的检索是“查字典”(一步到位),那么多跳检索就是“侦探破案”(顺藤摸瓜)。它要求系统像人类思考一样,将复杂问题拆解成多个子问题,通过多次“跳跃”检索不同的信息源,最终将碎片化的线索拼凑出完整答案。
🔍 核心区别:单跳vs多跳
为了直观理解,我们可以通过一个对比表格来看两者的差异:
表格
| 特性 | 单跳检索 (Single-hop) | 多跳检索 (Multi-hop) |
|---|---|---|
| 类比 | 查字典:直接查找定义 | 侦探破案:寻找线索,串联逻辑 |
| 问题类型 | 简单事实题(如“iPhone 15何时发布?”) | 复杂推理题(如“iPhone 15芯片供应商的创始人是谁?”) |
| 信息源 | 单个文档或片段即可满足 | 需综合2个及以上分散的文档 |
| 核心逻辑 | 关键词匹配 + 直接定位 | 拆解问题 + 迭代检索 + 逻辑推理 |
⚙️ 它是如何工作的?
多跳检索通常采用迭代式(Iterative)的策略,模拟人类的推理过程。
举个例子:
假设用户问:“发明iPhone的公司,其现任CEO是谁?”
系统无法在一个文档里直接找到这句话,它会进行以下“跳跃”:
假设用户问:“发明iPhone的公司,其现任CEO是谁?”
系统无法在一个文档里直接找到这句话,它会进行以下“跳跃”:
- 第一跳(寻找桥梁实体):
- 系统分析:“发明iPhone的公司”是谁?
- 检索结果:苹果公司 (Apple Inc.)
- 第二跳(基于新线索追问):
- 系统利用第一跳的结果,生成新查询:“苹果公司现任CEO是谁?”
- 检索结果:蒂姆·库克 (Tim Cook)
- 最终合成:
- 系统整合两步的信息,生成最终答案:“发明iPhone的公司是苹果公司,其现任CEO是蒂姆·库克。”
🛠️ 主流实现技术
为了实现这种“会思考”的检索,目前主要有以下几种技术路径:
- 迭代检索 (Iterative Retrieval)
这是最核心的方法。系统通过大模型(LLM)分析上一轮的检索结果,判断信息是否足够。如果不足,LLM会自动生成一个新的“子查询(Sub-query)”进行下一轮检索,直到找到答案或达到最大跳数(通常为2-3跳)。 - 图检索增强生成 (GraphRAG)
利用知识图谱将非结构化文档转化为“实体-关系”网络。- 原理: 在图谱中,“张三”连接“技术部”,“技术部”连接“李四(负责人)”。
- 优势: 系统可以直接在图上进行路径遍历(如查找2跳邻居),比纯文本检索更精准,且推理路径可解释。
- 强化学习辅助 (如LeReT)
利用强化学习训练模型,让它学会“如何更好地提问”。系统会根据检索到的结果质量给予奖励或惩罚,从而不断优化查询生成的策略,减少无效检索和幻觉。
🚧 面临的挑战
尽管多跳检索功能强大,但在实际落地中也面临一些难点:
- 错误传播: 如果第一跳检索错了(例如把“苹果公司”识别错),后续所有的推理都会偏离方向,导致最终答案错误。
- 计算开销: 多次检索意味着多次调用大模型和向量数据库,这会显著增加响应时间和成本。
- 循环死锁: 模型可能会陷入死循环,反复生成相同的无效查询(例如一直问“张三属于哪个部门”却得不到新信息),因此需要设置停止机制。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...