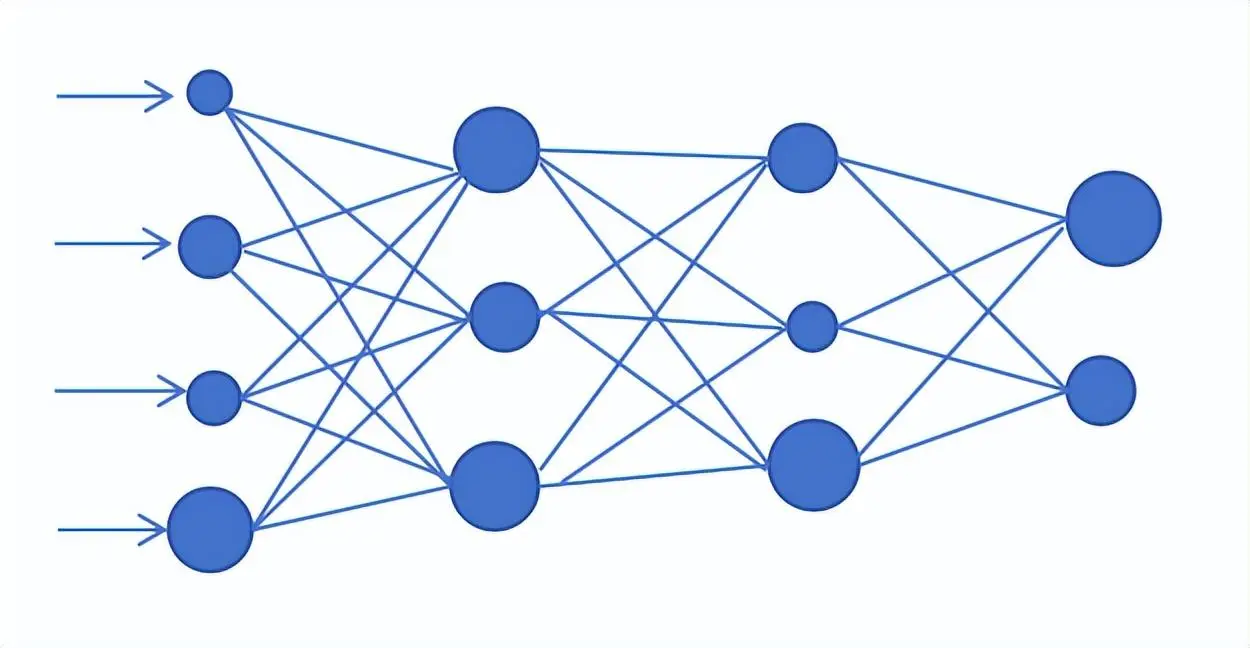
AI训练的原理,本质上是让计算机通过数据“学习”规律,而不是像传统软件那样由程序员编写明确的规则。这个过程的核心是优化,即让模型在海量数据中不断调整自身,直到它能出色地完成特定任务。
我们可以从两个层面来理解这个原理:宏观的学习范式和微观的优化过程。
🧠 宏观层面:三种核心学习范式
根据任务和数据的不同,AI训练主要有三种学习方式,它们决定了模型如何从数据中学习。
- 监督学习 (Supervised Learning)
这就像学生在有标准答案的练习册上学习。我们给模型提供大量带有“标签”的数据,也就是“问题”和对应的“正确答案”。模型通过学习这些数据,目标是找到从输入到输出的映射规律,从而能够对新的、未见过的“问题”给出正确的“答案”。- 例如:给模型看成千上万张标有“猫”或“狗”的图片,让它学会区分新的图片是猫还是狗。
- 无监督学习 (Unsupervised Learning)
这就像给学生一堆没有分类的积木,让他自己发现其中的规律。我们给模型提供大量没有标签的数据,让它自己去发现数据内在的结构、模式或分组。- 例如:给模型看大量用户的购物记录,让它自动将用户分成不同的群体(如“价格敏感型”、“品质追求型”)。
- 强化学习 (Reinforcement Learning)
这就像训练宠物或教孩子走路,通过“奖惩”机制来学习。模型(被称为“智能体”)通过与环境互动来完成任务,做对了就给予“奖励”,做错了就给予“惩罚”。模型的目标是学会一套策略,以在未来的互动中获得最大的累积奖励。- 例如:训练 AI 玩围棋游戏,赢了就给予正反馈,输了就给予负反馈,让它自己摸索出获胜的策略。
⚙️ 微观层面:模型是如何“学习”的?
无论是哪种学习范式,模型的学习过程都遵循一个核心的迭代循环,其本质是一个数学优化问题。
- 数据输入与预测
模型接收一批训练数据。数据首先经过模型的内部结构(如神经网络)进行计算,这个过程被称为前向传播。计算后,模型会给出一个预测结果。 - 计算误差 (Loss)
将模型的预测结果与真实结果(在监督学习中)或预设目标进行比较,计算出一个“误差值”或“损失值”(Loss)。这个值衡量了模型当前预测的“糟糕”程度。 - 反向传播与参数更新
这是学习的关键一步。系统会根据计算出的误差,通过一个名为反向传播的算法,将误差从输出端反向传递回模型的每一层。在这个过程中,算法会计算出模型内部每个参数(可以理解为“旋钮”)应该如何调整,才能让下一次的误差变小。然后,所有参数都会被同步更新。 - 迭代循环
上述过程会周而复始地进行。模型在成千上万批数据上重复“预测 → 计算误差 → 更新参数”这个过程。每一次迭代,模型的参数都变得更优一点,预测的误差都更小一点。
最终,当模型的误差降低到可接受的范围,或者性能不再显著提升时,训练过程就结束了。这时,模型内部的参数就被“固化”下来,形成一个训练好的模型,可以用于推理。
总而言之,AI训练的原理就是通过设定一个学习目标(如最小化误差),然后利用数据和强大的计算能力,通过迭代优化的方式,自动地、大规模地调整模型内部的参数,使其最终具备解决复杂问题的能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...