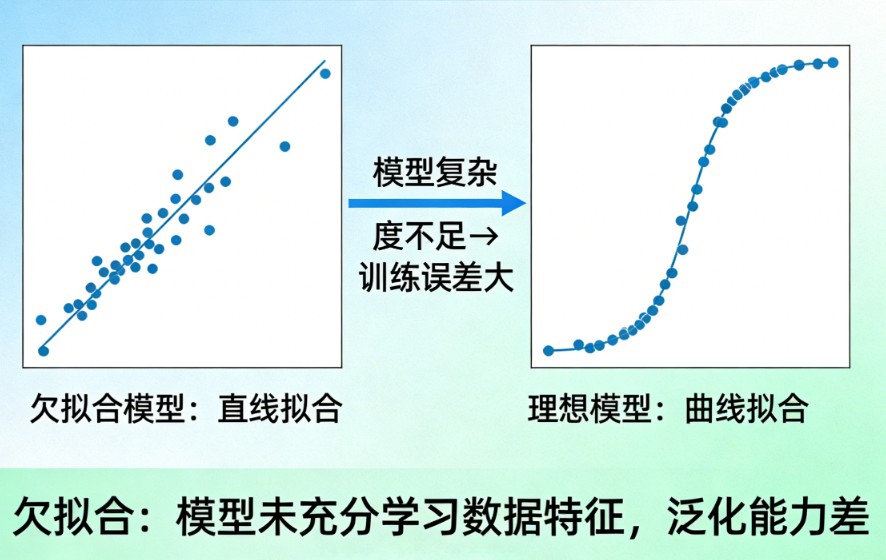
在机器学习中,欠拟合(Underfitting) 指的是一个模型过于简单,以至于无法捕捉到数据中蕴含的复杂模式和规律。
通俗地讲,欠拟合就是模型“学得太少”或“没学会”。它就像一个学生只看了课本的目录就去参加考试,无论是面对做过的练习题(训练数据)还是全新的考题(测试数据),成绩都会很不理想。
核心表现
欠拟合最典型的特征是模型在训练集和测试集上的表现都很差。
- 训练准确率低:模型无法很好地拟合它已经“见过”的训练数据。
- 测试准确率低:模型也无法对新的、未见过的数据做出准确预测。
- 高偏差 (High Bias):模型对数据的真实关系做出了过于简化的假设。
- 低方差 (Low Variance):模型对数据中的微小变化不敏感。
主要原因
导致欠拟合的常见原因包括:
- 模型复杂度过低:选择的模型太简单,例如用线性模型去拟合本质上是非线性的数据关系。
- 特征不足:输入模型的特征太少或质量不高,无法提供足够的信息让模型进行学习。
- 训练不充分:模型的训练时间太短或迭代次数不足,导致它还没找到最优解就停止了学习。
- 正则化过强:为了防止过拟合而引入的正则化技术(如L1/L2正则化),如果强度设置过高,会过度限制模型的学习能力,反而导致欠拟合。
解决思路
解决欠拟合的核心思路是提升模型的学习能力,使其能够更好地理解数据:
- 增加模型复杂度:尝试使用更复杂的模型,例如从线性回归切换到决策树或神经网络。
- 进行特征工程:挖掘并添加更多有信息量的特征,或对现有特征进行变换(如创建多项式特征)。
- 延长训练时间:增加训练的轮数(Epochs)或迭代次数,让模型有足够的时间收敛。
- 减弱正则化:适当降低正则化参数的强度,给予模型更大的学习空间。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...