
混合专家模型(Mixture of Experts, MoE)是一种巧妙的神经网络架构,其核心思想是“分工协作,按需激活”。
它旨在解决传统大模型“越大越慢、越贵”的难题。与传统模型在处理任何任务时都调动全部“脑力”(参数)不同,MoE模型更像一个高效的专家团队,能够根据具体任务,只派遣最合适的几位专家来处理,从而在保证强大能力的同时,极大地提升了效率。
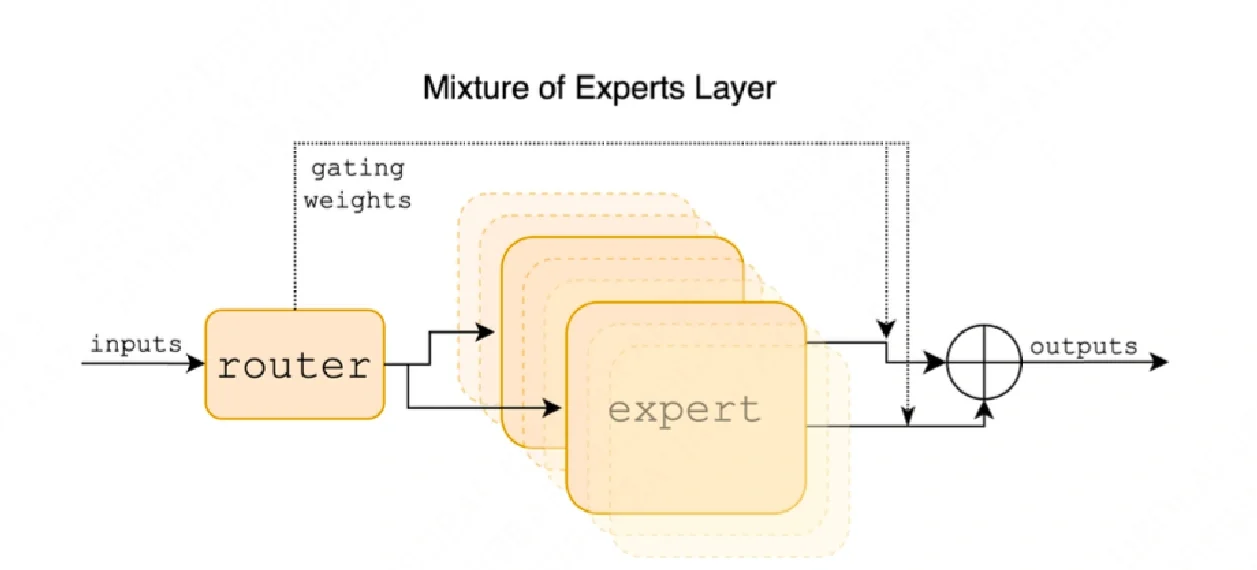
核心工作原理
MoE模型主要由三个核心部分组成,它们协同工作,形成一个高效的“会诊”流程:
- 专家网络(Experts)
它们是模型中的“ specialists”,是多个独立的、较小的神经网络。每个专家在处理特定类型的任务上有所专长,例如有的擅长代码生成,有的擅长文学创作,有的则精通逻辑推理。这些专长是在模型训练过程中自动形成的。 - 门控网络(Gating Network)
它扮演着“智能调度员”或“路由器”的角色。当模型接收到一个输入任务时,门控网络会首先分析这个任务,然后为每个专家计算一个“适配分数”,判断哪位或哪几位专家最适合处理这个任务。 - 结果整合
门控网络会根据分数,选择最相关的几位专家(通常是Top-K个,例如K=2)来“激活”。被选中的专家会并行处理任务,它们的输出结果最终会根据门控网络给出的分数进行加权求和,形成模型的最终输出。
关键机制:稀疏激活
这是MoE模型高效的核心所在。
- 传统稠密模型:就像一个“全能选手”,无论问题难易,每次都需要调动全部知识和技能(即激活所有参数)来应对。
- MoE稀疏模型:就像一个“专家团队”,面对问题时,只派遣最相关的几位专家(即只激活一小部分参数)来处理。
这种“稀疏激活”机制使得MoE模型能够拥有一个非常庞大的总参数量(即“专家”团队规模可以很大,模型“知识容量”高),但在实际处理每个任务时,计算成本却只相当于一个很小规模的模型。这完美地平衡了模型的能力与效率。
主要优势与应用
- 效率极高:大幅降低了训练和推理(使用模型)时的计算成本和速度,让运行万亿级参数的超大模型成为可能。
- 能力强大:由于总参数量可以做得非常大,模型能学习到的知识和模式也更多,整体性能更强。
- 专业性强:通过分工,不同专家可以在特定领域(如医疗、法律、编程)达到更专业的水平。
目前,MoE架构已被广泛应用于众多前沿大模型中,例如Mixtral 8x7B、DeepSeek-V2,以及据报道的GPT-4等,成为突破大模型性能瓶颈的关键技术之一。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...