
人类反馈强化学习(RLHF, Reinforcement Learning from Human Feedback)是一种将人类的主观偏好和价值观融入AI训练过程的技术,旨在让AI的行为和输出更符合人类的期望,变得更加“有用、无害、诚实”。
如果把训练AI比作培养一个学生,那么:
- 传统预训练:相当于让学生博览群书,学习海量的知识和语言规则。
- RLHF:则相当于请一位导师,根据学生的回答进行打分和点评,告诉他哪个答案更好、哪个更糟糕,从而引导学生形成正确的价值观和表达习惯。
为什么需要RLHF?
在RLHF出现之前,大型语言模型(LLM)主要通过预测下一个词来学习。这种方式虽然能让模型生成语法通顺的句子,但也存在明显问题:
- 目标不一致:模型的目标是“预测准确”,而不是“对人类有帮助”。
- 输出不可控:模型可能会生成有害、偏颇或不符合人类常识的内容。
- 难以定义“好坏”:像“这个回答是否友好”、“是否幽默”这类主观标准,很难用精确的数学公式来定义。
RLHF的核心作用就是解决这些问题,它通过引入人类反馈作为“奖励信号”,来指导模型优化其行为,使其与人类意图对齐(Alignment)。
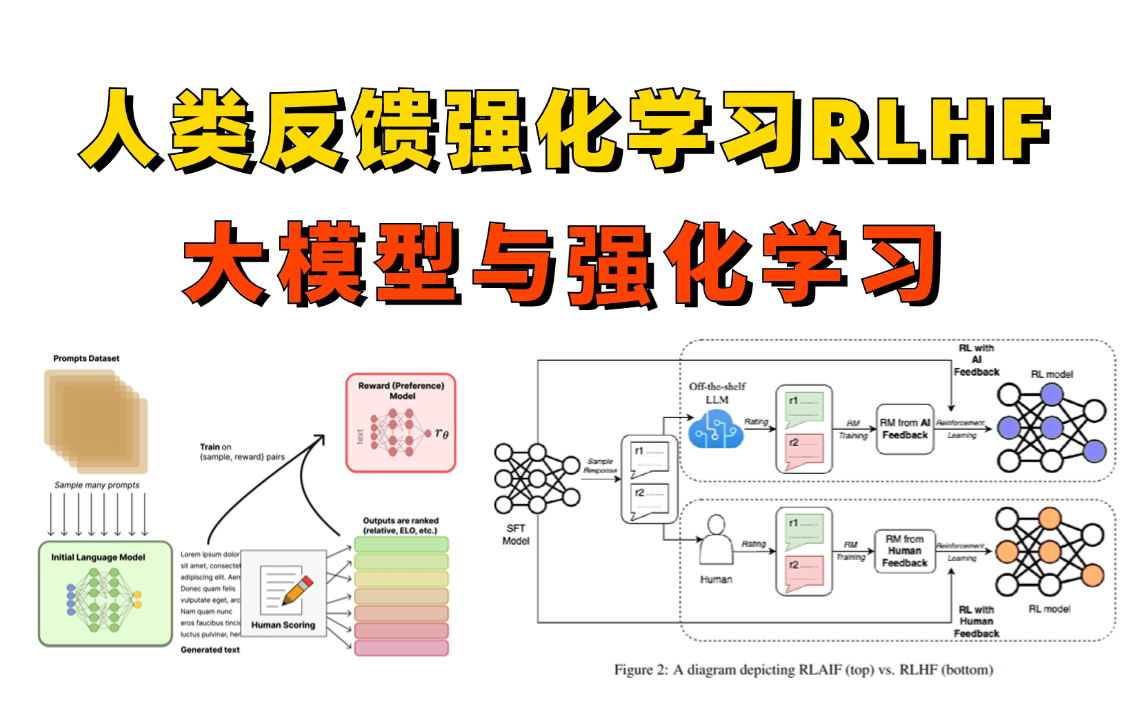
RLHF是如何工作的?
RLHF的训练流程通常分为三个关键阶段:
- 监督微调 (Supervised Fine-Tuning, SFT)
- 目标:教会模型基础的指令遵循能力。
- 过程:准备一批高质量的“问题-理想答案”示例数据,让模型学习如何模仿这些优质回答。经过这一步,模型从一个只会续写的“知识库”,变成了一个能初步理解并回应指令的“对话者”。
- 奖励模型训练 (Reward Model Training, RM)
- 目标:训练一个能评判答案好坏的“裁判”。
- 过程:让SFT模型对同一个问题生成多个不同的回答。然后,由人类标注员对这些回答进行排序(例如,A比B好,B比C好)。利用这些人类偏好数据,训练一个独立的“奖励模型”。这个模型学会了根据人类的标准,给任何回答打一个分数,分数越高代表越符合人类偏好。
- 强化学习优化 (Reinforcement Learning Optimization)
- 目标:让模型学会最大化“裁判”的打分。
- 过程:使用强化学习算法(如PPO)来微调SFT模型。在这个阶段,模型会尝试生成回答,然后由上一步训练好的“奖励模型”进行打分。模型的目标就是通过不断调整自己的参数,使得自己生成的回答能获得尽可能高的分数。最终,模型就学会了如何产出更符合人类偏好的内容。
RLHF带来的改变
RLHF是ChatGPT等现代对话式AI能力飞跃的关键技术。通过对比可以清晰地看到它的作用:
表格
| 模型阶段 | 典型代表 | 特点 | 是否使用RLHF |
|---|---|---|---|
| 预训练模型 | GPT-3 | 知识渊博但难以控制,输出可能偏离指令,甚至产生有害内容。 | ❌ |
| 对齐后模型 | ChatGPT (GPT-3.5) | 能更好地理解人类意图,回答更有帮助、更安全、更符合对话格式。 | ✅ |
挑战与未来
尽管RLHF效果显著,但它也面临一些挑战:
- 成本高昂:收集高质量的人类偏好数据非常耗时耗力。
- 主观偏差:人类标注员的个人偏好和价值观会直接影响模型的对齐方向,可能引入新的偏见。
- 训练不稳定:强化学习过程本身比较复杂,可能导致模型性能下降或出现“灾难性遗忘”。
为了应对这些挑战,业界也在探索更高效的方法,例如直接偏好优化(DPO),它绕过了训练奖励模型的复杂步骤,直接利用人类偏好数据来优化模型,简化了流程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...