
多层神经网络(Multi-Layer Neural Network),也常被称为深度神经网络(DNN)或多层感知机(MLP),是深度学习中最基础且核心的模型。
简单来说,它是一种受人脑结构启发而设计的计算模型,通过在输入层和输出层之间增加一个或多个“隐藏层”,从而具备了学习和解决极其复杂问题的能力。
为什么需要“多层”?
要理解多层神经网络的价值,首先要看它的“前身”——单层感知机。单层感知机结构简单,但它有一个致命弱点:只能解决线性可分问题。
- 线性可分:想象在一张纸上画着红、蓝两种颜色的点,如果你能用一根直线就把所有红点和蓝点完全分开,这就是线性可分。
- 非线性问题:但现实世界的问题往往复杂得多。例如经典的“异或(XOR)”问题,就无法用一根直线将两类数据分开。
多层神经网络的诞生,正是为了突破这一限制。通过引入隐藏层和非线性激活函数,它拥有了拟合复杂非线性关系的能力,从而能够处理现实世界中绝大多数复杂的任务。
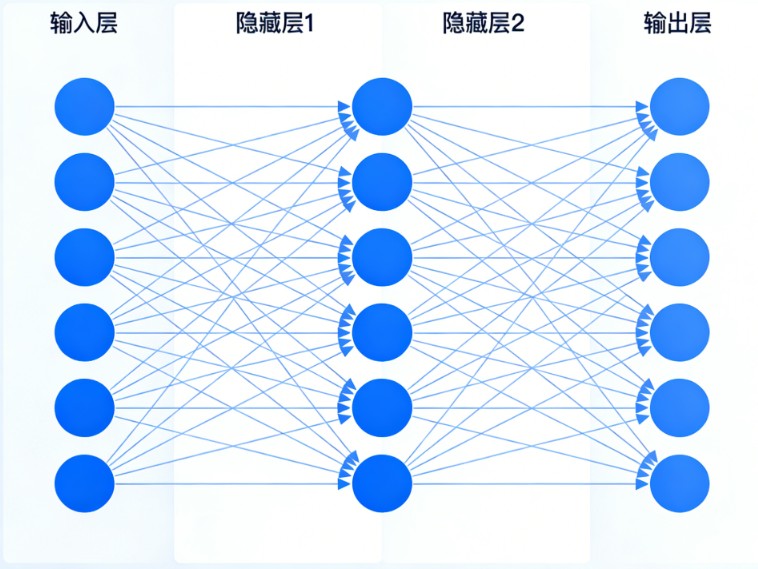
核心结构:三层架构
多层神经网络的结构清晰,通常由以下三层堆叠而成:
- 输入层 (Input Layer)
- 网络的“感官”,负责接收原始数据。例如,在图像识别任务中,输入层接收的就是图像的像素值。
- 隐藏层 (Hidden Layers)
- 网络的“大脑”,位于输入层和输出层之间,可以有一层或多层。
- 这是网络的核心,负责特征提取和抽象。每一层都会对上一层传递来的信息进行加工和转换。
- 逐层抽象:浅层隐藏层可能学习到边缘、颜色等基础特征;更深层的隐藏层则能将这些基础特征组合成更复杂的概念,如形状、纹理,甚至是物体的局部(如眼睛、车轮)。
- 输出层 (Output Layer)
- 网络的“决策者”,负责输出最终结果。
- 根据任务不同,输出也不同。例如,在分类任务中,它会输出属于各个类别的概率;在回归任务中,则直接输出一个预测数值。
工作原理:思考与学习
多层神经网络的工作过程可以分为两个核心阶段:
1. 前向传播 (Forward Propagation) – “思考”
这是网络进行推理或预测的过程。
- 数据从输入层进入,逐层向后传递。
- 在每一层,数据都会与预设的权重(Weights)和偏置(Bias)进行线性计算,然后通过一个激活函数(Activation Function)进行非线性变换。
- 这个过程一直持续到输出层,最终得到网络的预测结果。
2. 反向传播 (Backpropagation) – “学习”
这是网络通过训练来优化自身、提升准确度的过程。
- 计算误差:将网络前向传播得到的预测结果与真实答案进行比较,计算出误差(或称损失)。
- 反向传递:将这个误差从输出层开始,沿着网络连接反向传播回输入层。
- 调整参数:在反向传播的过程中,利用链式法则计算每个权重和偏置对总误差的贡献(即梯度),然后使用优化算法(如梯度下降)来微调这些参数,目标是让下一次的预测误差更小。
通过成千上万次的“前向预测-反向学习”循环,网络内部的数百万甚至数十亿个参数被不断调整,最终学会如何准确地完成任务。
主要优势与应用
多层神经网络的强大之处在于:
- 自动特征学习:无需人工手动设计和提取特征,网络能自己从原始数据中学习到最有效的特征表示。
- 强大的表达能力:理论上,一个足够大的多层神经网络可以逼近任何复杂的连续函数。
这些特性使其成为现代人工智能应用的基石,广泛应用于:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...