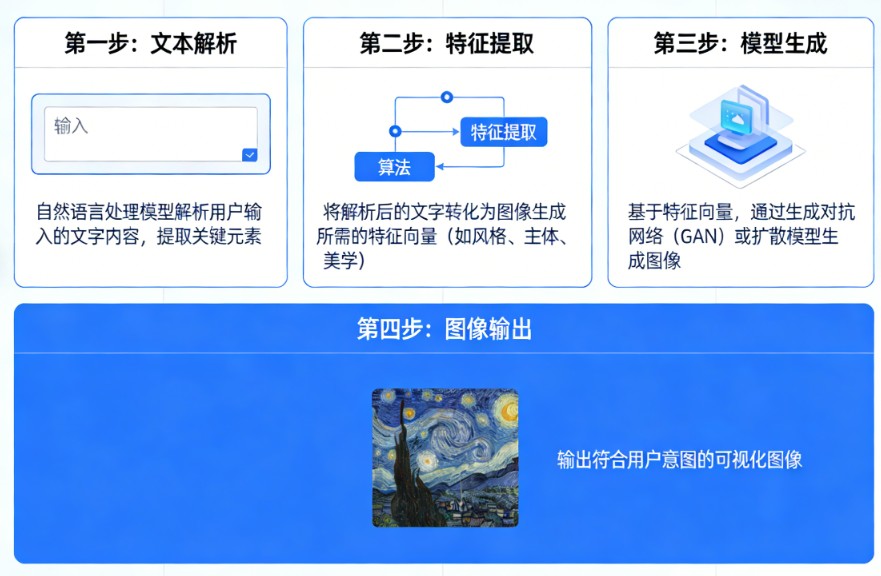
基座模型(Foundation Model),也常被称为基础模型,是人工智能领域的一个核心概念。你可以把它理解为一个“通才”学生,它通过在海量、多样的数据上进行大规模预训练,从而掌握了广泛的知识和强大的通用能力。
这个模型本身并不直接解决某个具体问题,而是作为一个强大的“底座”或“起点”,可以被高效地适配(例如通过微调)到各种各样的下游任务中。
为什么叫“基座”?
“基座”这个词非常形象,它强调了这类模型的两个核心特性:
- 基础支撑作用:它就像建筑物的地基,为上层各种具体应用(如智能客服、代码生成、医疗诊断等)提供坚实的能力支撑。开发者无需从零开始训练,可以直接在基座模型的基础上进行二次开发,大大降低了成本和门槛。
- 可迁移与适配性:基座模型具备强大的可迁移能力。它学到的通用知识和能力,可以被灵活地“迁移”并“适配”到不同领域和任务中,无论是写文章、做翻译,还是进行逻辑推理。
基座模型 vs. 微调模型
理解基座模型最好的方式,就是将它与经过微调的模型(如ChatGPT)进行对比。
一个普遍的观点认为,基座模型在很大程度上决定了微调模型的能力上限。微调过程更像是“激发”或“引导”出基座模型已经具备的潜力,而不是赋予它全新的能力。
基座模型vs行业大模型
随着技术的发展,基座模型也衍生出了更细分的概念,特别是与“行业大模型”的区别。
- 基座模型 (Foundation Model):通常指在通用数据上训练的“通才”模型,如GPT-4、LLaMA。它能力广泛,但在特定专业领域的深度可能不足。
- 行业大模型 (Industry-Specific Model):是在通用基座模型的基础上,使用特定行业(如法律、医学、金融)的高质量专业数据进一步训练或微调而成的“专才”模型。
一个生动的比喻:
- 通用基座模型 就像一个读了高中、知识全面的毕业生,但还没上过大学。
- 行业大模型 则像是这个毕业生又去读了医学或法律专业,成为了某个领域的专家。
例如,Med-Go就是一个医学基座模型,它通过精选数千本权威医学著作进行训练,旨在为医学AI的二次开发提供一个高质量的“地基”,避免通用模型在医学场景下“精准度差”的问题。同样,法信法律基座大模型也是利用海量的法律文献、案例数据进行预训练,为司法、执法等场景提供专业支持。
基座模型的广泛应用
基座模型的概念早已超越了自然语言处理,成为驱动多个前沿领域的核心技术:
- 具身智能 (Embodied AI):如智元机器人发布的“智元启元大模型”,就是一个通用具身基座模型。它能让机器人通过海量数据学习,获得革命性的学习能力,并能快速适应新任务、部署到不同的机器人本体上。
- 自动驾驶:小鹏汽车正在研发的“小鹏世界基座模型”,以720亿参数的超大规模,结合海量驾驶数据进行多模态训练,旨在实现超越人类水平的自动驾驶能力。
- 科学研究:在机器联觉等前沿科研领域,研究人员也提出利用通用基座模型和领域专用基座模型,来解决复杂系统设计中的泛化性和通用性难题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...