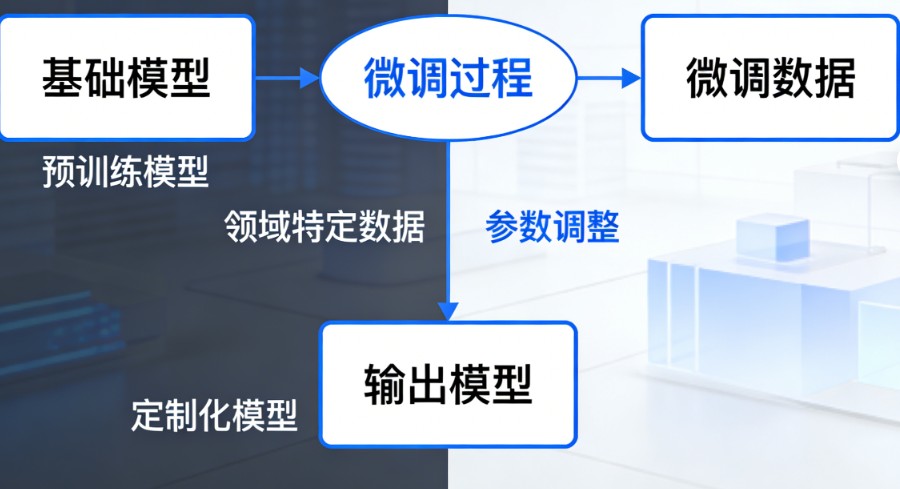
微调模型(Fine-tuning),通俗点说,就是给一位“博学的通才”进行“职业技能特训”。
在人工智能领域,我们通常先有一个在海量数据上训练好的基座模型(Base Model),它读过互联网上的书、文章、代码,什么都懂一点,但可能不懂你特定行业的“行话”,或者不懂怎么按照你的格式写报告。
微调就是拿你手头特定的、高质量的数据(比如医疗病历、法律合同、公司客服记录),在这个基座模型的基础上,再训练一小段时间。这样,模型既保留了原本的知识,又学会了你的特定任务,变成了该领域的“专家”。
为什么要微调?
- 省钱省力:从头训练一个大模型需要几百万美元和数月时间;微调只需要少量数据和几小时(甚至几分钟),成本极低。
- 更懂行:通用模型可能不知道你们公司的缩写是什么意思,微调后它就懂了。
- 格式规范:可以让模型学会输出特定的JSON格式、特定的说话语气等。
微调模型常用的方法
随着模型越来越大(几百亿甚至上万亿参数),全量微调变得越来越难。因此,目前主流的方法主要分为全量微调和参数高效微调两大类。
1. 全参数微调
这是最传统、最“硬核”的方法。
- 原理:不保留任何“冻结”参数,把模型里所有的权重都拿出来,根据你的数据进行更新。
- 优点:理论上效果最好,模型能最彻底地适应新任务。
- 缺点:极贵、极慢。需要昂贵的显卡集群,显存占用巨大,且容易导致模型“灾难性遗忘”(学会了新知识,忘了旧知识)。
- 适用场景:拥有海量特定领域数据(如10万条以上),且计算资源非常充足。
2. 参数高效微调
这是目前大模型时代最主流的选择。核心思想是:“锁住大部分模型,只训练一小部分新增的参数”。
- LoRA —— 目前的“版本之子”
- 原理:想象在原本庞大的模型旁边,并联了一组很小的“旁路”矩阵。训练时,大模型不动,只训练这个小的旁路。
- 优点:显存占用极低(普通消费级显卡也能跑),训练速度极快,且可以像“插拔U盘”一样,给同一个基座模型挂载不同的LoRA来实现不同功能。
- 地位:目前应用最广泛的微调方法。
- QLoRA —— 极致压缩版
- 原理:在LoRA的基础上,先把大模型“压缩”(量化)成4-bit精度,再挂载LoRA进行训练。
- 优点:让在单张普通显卡上微调超大模型(如650亿参数的模型)成为可能。
- Adapter Tuning —— 嵌入式
- 原理:在模型的层与层之间,插入一个个小的“适配器”模块,只训练这些模块。
- 优点:模块化好管理。
- 缺点:推理速度会比LoRA稍慢(因为增加了网络深度)。
- P-Tuning / Prefix Tuning —— 提示词优化
- 原理:不改变模型参数,而是学习一段“虚拟的提示词”加在输入前面,引导模型输出想要的结果。
- 优点:参数量极小。
方法对比总结表
表格
| 方法 | 训练参数量 | 显存需求 | 训练速度 | 效果上限 | 推荐场景 |
|---|---|---|---|---|---|
| 全参数微调 | 100% | 极高 | 慢 | 最高 | 数据量极大、追求极致性能、资源充足 |
| LoRA | 1% – 10% | 低 | 快 | 高 | 绝大多数场景的首选,兼顾效果与成本 |
| QLoRA | < 1% | 极低 | 较快 | 中高 | 显存受限(如单卡4090/3090),想跑大模型 |
| P-Tuning | < 0.1% | 极低 | 极快 | 中 | 任务简单,仅需改变模型行为模式 |
补充:指令微调
除了上述技术手段,还有一个概念叫指令微调。这更多是指数据层面的策略。
- 它使用的是“指令-回答”格式的数据(例如:“请把这句话翻译成英文” -> “…”)。
- 目的是让模型学会听懂人话,能够遵循指令,而不仅仅是做填空题。现在的ChatGPT等对话模型,都是在基座模型上经过了指令微调(以及后续的RLHF人类反馈强化学习)。
一句话建议:如果你是初学者或企业开发者,首选 LoRA 方法,它在成本、速度和效果之间取得了最好的平衡。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...