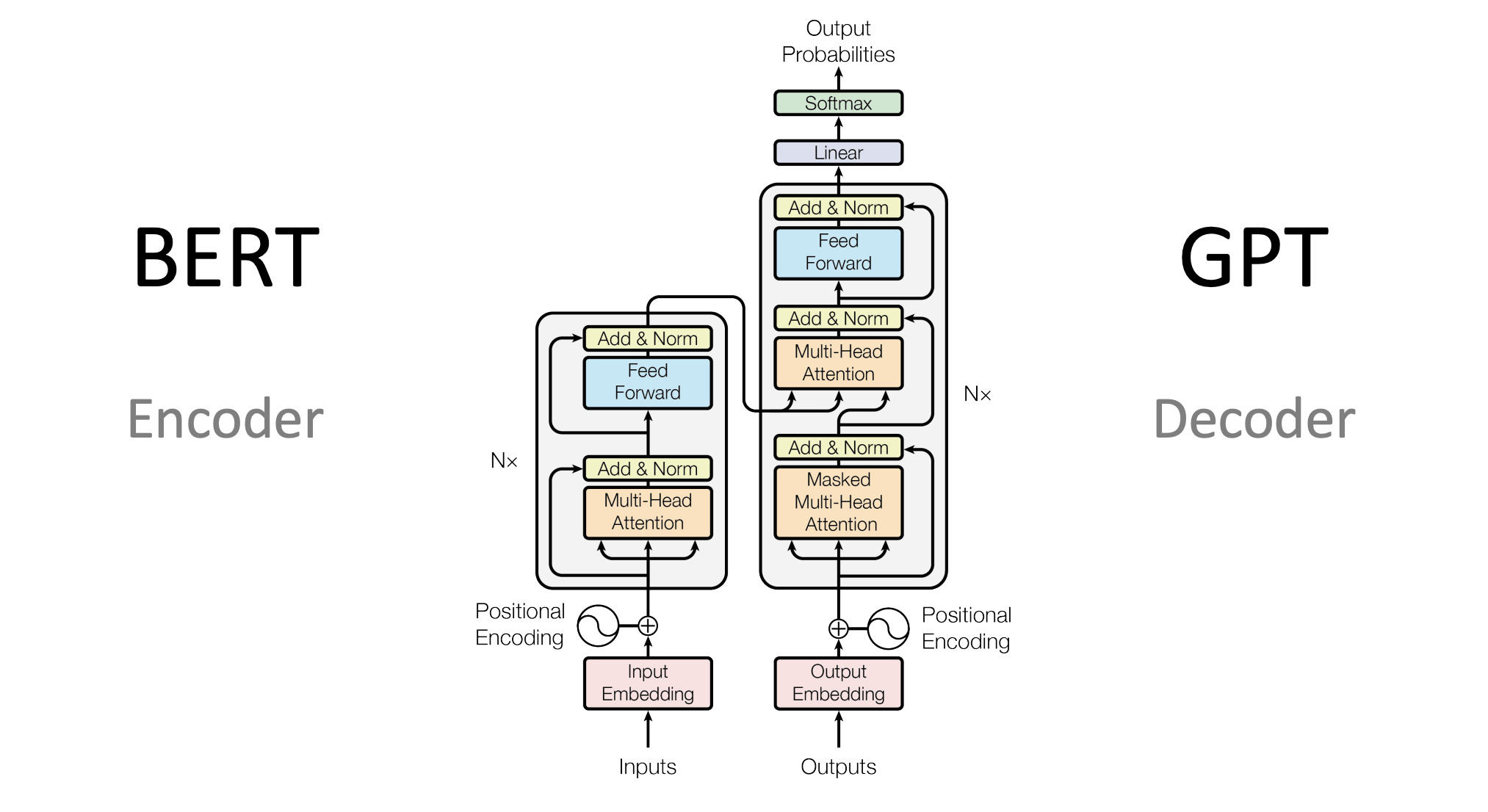
通用大模型(General-Purpose Large Model),你可以把它理解为人工智能界的“通才”或“全能型选手”。
它是指那些在海量、多源的数据(如整个互联网的文本、书籍、代码、图像等)上进行训练,拥有庞大参数量(通常在百亿甚至万亿级别)的AI模型。
它的核心特点是“广度优先”:它不局限于某一个特定领域,而是具备了跨领域的知识储备和逻辑推理能力,能够“举一反三”,灵活应对各种从未见过的任务。
核心形象:从“专才”到“通才”
为了让你更直观地理解,我们可以把它和“垂直大模型”做一个对比:
表格
| 维度 | 通用大模型 | 垂直/行业大模型 |
|---|---|---|
| 角色定位 | “博学的通才”(像一位知识渊博的本科生) | “资深的专家”(像一位专科医生或律师) |
| 训练数据 | 海量通用数据(全网文本、书籍、百科、代码等) | 通用数据 + 大量特定行业数据(如病历、法律条文、工业日志) |
| 能力特点 | 泛化能力强:什么都能聊,什么都能写,适应性强 | 专业度高:在特定领域(如金融风控、药物研发)极其精准 |
| 典型代表 | ChatGPT, DeepSeek, 文心一言, 通义千问 | 盘古矿山大模型, 神农农业大模型, 医疗大模型 |
通用大模型的三大核心能力
通用大模型之所以被称为“通用”,是因为它打破了传统AI“一个模型只能干一件事”的限制:
- 跨任务处理(一模型多用途):
你不需要为翻译、写作、写代码分别训练三个模型。同一个通用大模型,上一秒可以帮你翻译英文,下一秒可以帮你写Python代码,再下一秒可以帮你润色周报。 - 强大的逻辑推理:
它不仅能检索知识,还能进行复杂的思维链推理。比如你问它一道复杂的数学题,它能一步步拆解并算出答案;或者你给它一个逻辑谜题,它能分析出因果关系。 - 多模态交互(进阶能力):
新一代的通用大模型(如GPT-4o, Gemini)不仅能处理文字,还能“看懂”图片(分析图表)、“听懂”声音,甚至进行实时视频对话,实现了跨模态的通用能力。
技术原理:它是怎么练成的?
通用大模型的构建通常遵循“预训练 + 微调”的范式:
- 第一阶段:海量预训练(通识教育)
让模型“阅读”互联网上几乎所有的公开数据。这个阶段,模型学会了语言的语法、世界的常识、基本的逻辑和编程规则。这赋予了它强大的基础底座能力。 - 第二阶段:指令微调与对齐(职业培训)
通过人类反馈强化学习等技术,教模型如何听懂人类的指令,如何像一个助手一样回答问题,而不是胡乱预测下一个字。
为什么它很重要?
通用大模型被视为人工智能的“基础设施”或“底座”(有时被称为L0级模型)。
- 对于开发者:它是创新的起点。开发者不需要从头训练一个AI,而是可以直接调用通用大模型的API,或者在它的基础上进行“微调”,低成本地开发出医疗、法律、金融等各行各业的专业应用。
- 对于普通人:它是万能的数字助手。无论是写文案、查资料、做计划,还是编程辅助,它都能提供即时的帮助。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...