
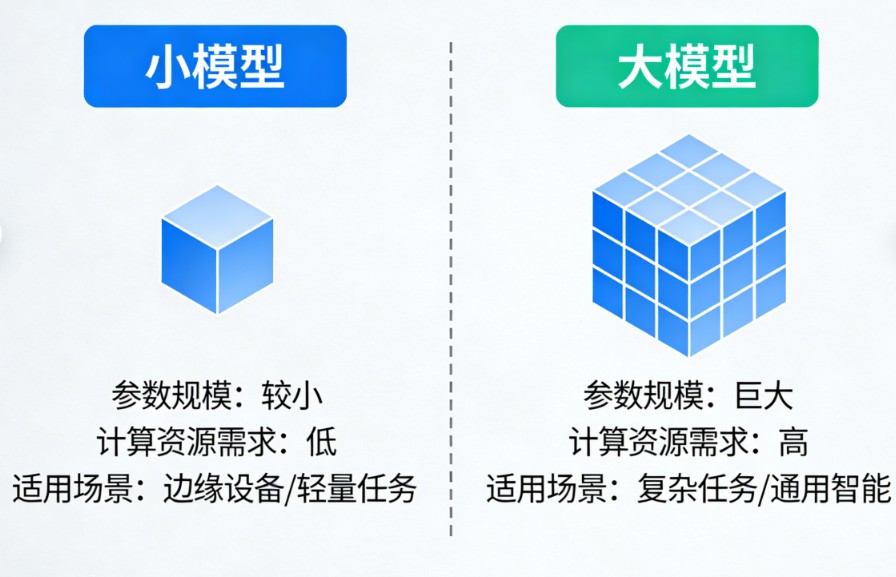
“小模型”与“大模型”的区别,可以从两个层面来理解:一是它们通常所指的技术范畴不同,二是在参数量级上的相对差异。
简单来说,“大模型”通常特指基于Transformer架构的生成式AI模型,而“小模型”则是一个更宽泛的概念,既可以指参数量较小的同类模型,也可以指代传统的机器学习模型。
核心差异对比
表格
| 维度 | 小模型 (Small Models) | 大模型 (Large Models) |
|---|---|---|
| 核心能力 | 专用性强。擅长解决特定、定义清晰的任务,如图像分类、垃圾邮件识别。 | 通用性强。具备强大的泛化能力,能处理多种复杂任务,如写作、翻译、代码生成。 |
| 训练数据 | 通常使用特定任务的标注数据,数据量相对较小。 | 在海量的、多样化的互联网文本、图像等数据上进行训练。 |
| 技术架构 | 架构多样,可以是简单的逻辑回归、决策树,也可以是CNN、RNN等传统深度学习网络。 | 主要基于Transformer架构,拥有数十亿甚至万亿级的参数。 |
| 部署成本 | 低。对算力和存储要求不高,易于在边缘设备(如手机)上部署和运行。 | 高。需要昂贵的GPU集群进行训练和推理,部署和维护成本高昂。 |
大模型:全能型选手
大模型(Large Language Models, LLMs)是近年来人工智能领域的突破性进展。它们通过在海量数据上进行预训练,学会了理解和生成人类语言、图像等内容。
- 优势:具备强大的“涌现能力”,能够完成训练时未明确指定的复杂任务,泛化性极强。
- 劣势:训练和推理成本极高,且由于知识过于宽泛,在特定专业领域的深度可能不足,有时会产生“幻觉”(即生成看似合理但不准确的内容)。
- 代表:GPT-4、文心一言、通义千问等。
小模型:领域专家或传统方案
“小模型”这个概念包含两层含义:
两者关系:并非对立,而是协同
大模型和小模型并非相互取代的关系,而是协同发展的。
- 大模型赋能小模型:可以利用大模型的强大能力来生成高质量的标注数据,用于训练更精准、更高效的小模型。
- 小模型补充大模型:在对实时性、成本敏感或专业性要求极高的场景中,专门优化后的小模型往往比通用大模型更具优势。例如,在工业质检中,一个专门训练的小模型可以毫秒级速度检测产品缺陷,而通用大模型则难以胜任。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...