VLM(Vision-Language Model,视觉语言模型)是一种能同时“看懂”图像并理解语言的多模态人工智能模型。你可以把它想象成一位既拥有敏锐观察力,又具备强大语言理解和推理能力的“智能助手”。 它不仅能识别图像中的物体,更能理解图像的整体含义、上下文关系,并用自然语言进行描述、回答关于图像的问题,甚至进行逻辑推理。

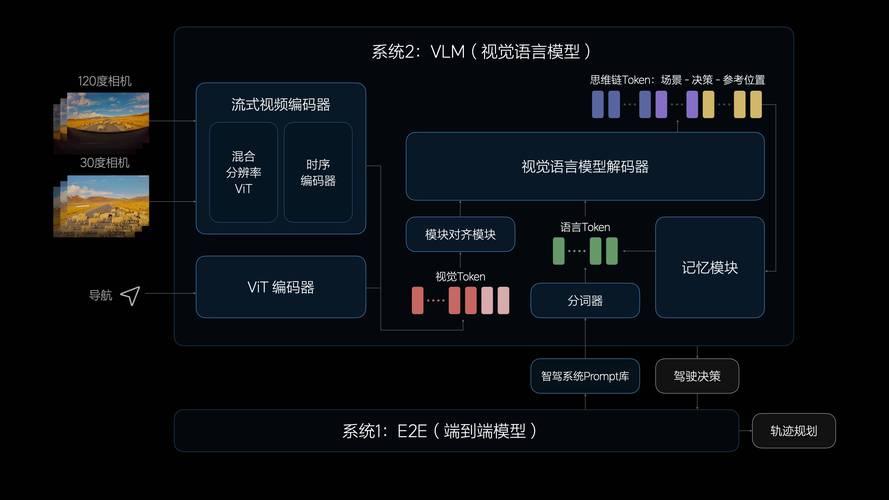
VLM是如何工作的?
VLM的架构通常由三个核心部分组成,协同工作以连接视觉与语言:
- 视觉编码器 (Visual Encoder):负责“看”。它通常是一个强大的图像识别模型(如CLIP),用来提取图像中的关键特征和信息。
- 投影器 (Projector):负责“翻译”。它将视觉编码器提取的图像特征,转换成语言模型能够理解的“语言”(即视觉标记 tokens)。
- 大语言模型 (LLM):负责“思考”和“表达”。它接收经过“翻译”的图像信息和用户的文本指令,进行深度理解和推理,最终生成文本回答。
通过这种方式,VLM打破了传统计算机视觉模型只能完成特定任务(如分类、检测)的局限,能够根据开放式的文本指令,灵活地处理各种视觉任务。
VLM的实际应用
VLM技术正迅速从实验室走向实际应用,尤其在自动驾驶、机器人等领域展现出巨大潜力。
- 智能驾驶:在汽车的智能驾驶系统中,VLM扮演着“副驾专家”的角色。例如,理想汽车和小米汽车都已将VLM技术应用于其自动驾驶方案中,用于识别复杂的交通标志(如潮汐车道)、理解路面施工场景,并为车辆的决策提供逻辑推理支持。高德地图也推出了基于Traffic VLM的功能,能提供更超视距的路况推理和动态车道提醒。
- 机器人技术:VLM是赋予机器人理解物理世界能力的关键。
- 英伟达 (NVIDIA) 发布了开源的Cosmos Reason2模型,它能让机器人像人类一样观察、理解环境,并通过“思维链”(CoT)进行推理,从而规划并执行复杂的动作。
- 中科视语 发布的 PhysVLM 模型,则更进一步,它不仅能让机器人“看懂”环境,还能理解自身的物理限制(如机械臂的活动范围),从而做出既“看得懂”又“做得到”的可靠决策。
总而言之,VLM通过融合视觉感知与语言智能,正在成为连接数字世界与物理世界的重要桥梁。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...