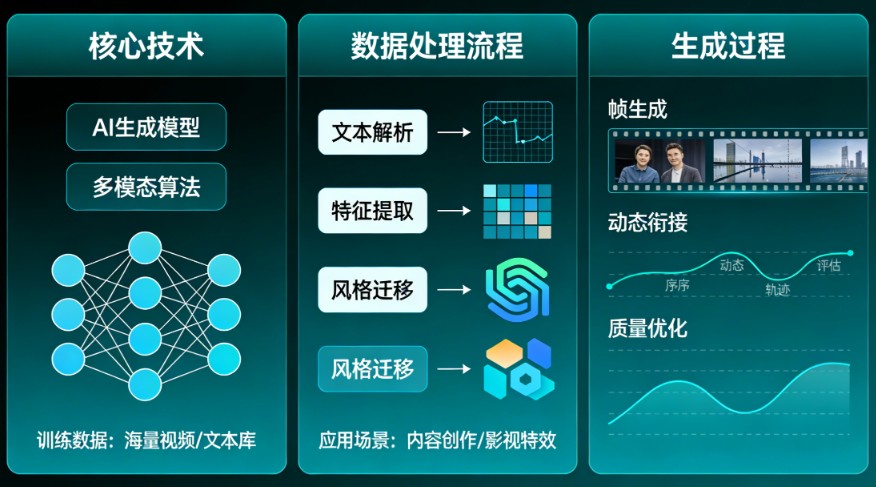
多模态人工智能模型(Multimodal AI)是一种能够同时处理和关联多种不同类型数据的人工智能系统。这里的“模态”(Modality)指的就是数据的形式,比如文本、图像、音频、视频、传感器信号等。
你可以把它想象成一位拥有“眼、耳、口”等多种感官,并能将这些感官信息融会贯通的“智能体”。它不再局限于处理单一信息,而是像人类一样,通过整合视觉、听觉、语言等多种线索来更全面、更深刻地理解世界。
核心工作原理
多模态AI模型的工作流程通常包含三个关键步骤,旨在将不同形式的信息“翻译”并融合在一起:
- 输入与编码 (Input & Encoding)
模型首先接收来自不同模态的原始数据(如一张图片和一段文字描述)。然后,通过专门的编码器(如处理图像的CNN或处理文本的Transformer),将每种数据转换成计算机能够处理的统一数学表示,即“嵌入向量”(Embedding Vector)。 - 融合与对齐 (Fusion & Alignment)
这是多模态AI的核心。模型会将不同模态的嵌入向量映射到一个共享的语义空间中,并学习它们之间的关联关系。例如,它会将“苹果”这个词的向量与一张苹果图片的向量在空间中拉近,从而实现“图文对齐”。 - 推理与输出 (Reasoning & Output)
在融合了对齐后的多模态信息后,模型可以进行综合推理,并根据任务需求生成最终结果。这个结果可以是文本(如图片描述)、图像(如根据文字生成图片)、分类标签或决策指令等。
主要能力与应用
多模态AI的能力主要围绕“跨模态理解”和“跨模态生成”两大核心构建,并已广泛应用于多个领域。
跨模态理解
指模型能够理解不同模态信息之间的关系,并进行联合推理。
- 视觉问答:给模型一张图片,并用自然语言提问(如“图中的狗在做什么?”),模型能结合图像内容给出准确回答。
- 医疗诊断:整合患者的医学影像(如CT扫描)、电子病历文本和基因组学数据,为医生提供更全面、精准的诊断建议。
- 自动驾驶:融合摄像头、激光雷达、毫米波雷达等多种传感器的数据,构建对周围环境的立体感知,从而做出安全的驾驶决策。
跨模态生成
指模型能够根据一种模态的信息,创造出另一种模态的内容。
- 文生图/视频:根据一段文字描述(如“一只在月球上弹吉他的猫”),生成与之匹配的图像或视频。
- AI内容创作:生成角色、场景、风格高度一致的多集短视频内容。
- 智能助手:接收用户的语音指令和手机屏幕截图,直接分析并给出操作建议。
技术前沿:原生多模态
当前,多模态AI的一个重要发展方向是“原生多模态”(Native Multimodal)。
与早期将不同模态的模型简单拼接的方式不同,原生多模态模型从底层架构设计之初,就将图像、语音、文本等多种模态统一建模,嵌入同一个共享的向量空间。这使得模型能够更自然、更高效地实现跨模态对齐和理解,无需经过“文本中转”,代表了多模态技术演进的更高级形态。例如,谷歌的Gemini和商汤科技发布的NEO架构,都是原生多模态的代表。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...