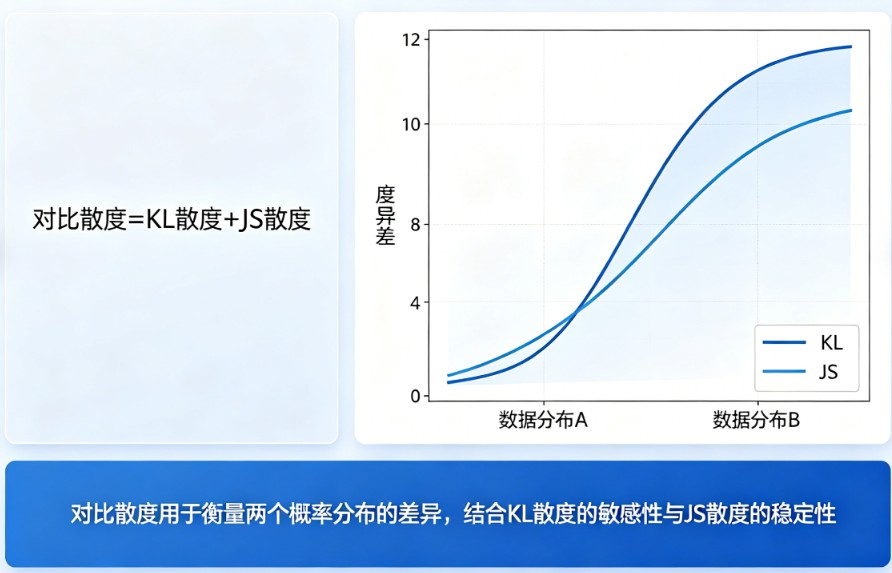
对比散度(Contrastive Divergence,简称CD)是深度学习领域中一种非常巧妙的算法,由著名科学家杰弗里·辛顿(Geoffrey Hinton)在2002年提出。它的核心作用是高效地训练一种名为“受限玻尔兹曼机”(RBM)的神经网络。
你可以把它理解为一个让AI模型“知行合一”的快速学习方法。
核心思想:像人一样“学习”与“思考”
对比散度的思想非常直观,辛顿本人曾用“清醒”和“睡眠”来比喻。
- 清醒阶段(学习):模型“睁眼看世界”。给它输入真实的数据(比如一张图片),让它根据这些数据进行内部调整,学习数据的特征。
- 睡眠阶段(思考/重构):模型“闭眼做梦想”。让它脱离真实数据,根据自己的理解去“幻想”或“重构”出一个数据。
- 对比差异:算法的核心就是对比“清醒时看到的数据”和“睡眠时幻想出的数据”之间的差异(散度)。通过不断调整模型参数来缩小这个差异,模型就能越来越接近真实数据的分布。
这个过程正如孔子所言“学而不思则罔,思而不学则殆”,CD算法正是将“学习”(正相)和“思考”(负相)结合起来,驱动模型不断进步。
为什么需要它?解决一个核心难题
在CD算法出现之前,训练RBM这类模型非常困难。
- 理论上的障碍:训练RBM的目标是最大化数据的似然概率,但计算过程中会遇到一个名为“配分函数”(Partition Function)的项。计算这个项需要对所有可能的状态求和,这在计算上是几乎不可能完成的任务,复杂度极高。
- CD的解决方案:CD算法并没有去硬算这个复杂的配分函数,而是采用了一种聪明的近似方法。它通过一种名为“吉布斯采样”(Gibbs Sampling)的技术,从真实数据出发,只进行少数几步(通常是一步,即CD-1)采样,就能得到一个对梯度的良好估计。
这种方法极大地降低了计算成本,使得训练RBM从“理论上可行但实际中太慢”变成了“实际中高效可用”,从而引爆了RBM和后续深度信念网络(DBN)的研究热潮。
算法流程:CD-1
最常用的CD算法是CD-1,即只进行一次吉布斯采样。其流程非常简洁:
- 正相 (Positive Phase):将一个真实的训练样本
v₀输入到可见层,计算出隐藏层h₀的激活概率并进行采样。这代表了模型对真实数据的“看法”。 - 重构 (Reconstruction):用隐藏层
h₀的状态去重构可见层,得到一个新的“幻想”样本v₁。 - 负相 (Negative Phase):再用这个“幻想”样本
v₁去计算新的隐藏层h₁的激活概率。这代表了模型当前“幻想”出的数据。 - 更新权重:对比正相和负相中神经元激活的关联性,并据此更新网络的权重。更新规则大致是:权重更新 ∝ (正相关联性 – 负相关联性)。
通过这种方式,模型被“推”向真实数据分布,同时被“拉”离它自己产生的错误幻想,从而不断优化。
历史地位与影响
尽管现在深度学习的主流是Transformer等架构,但对比散度在AI发展史上扮演了至关重要的角色:
- 深度学习的催化剂:CD算法使得高效训练RBM成为可能,而多个RBM可以堆叠起来形成深度信念网络(DBN)。这种“逐层预训练”的方法在2006年开启了深度学习的复兴时代,解决了深层网络难以训练的问题。
- 生成式模型的先驱:CD算法的思想——通过对比真实数据和模型生成数据的差异来进行学习——深刻影响了后来的生成式模型,如生成对抗网络(GAN)。
总而言之,对比散度是一个为解决特定难题而生的、充满智慧的算法,它不仅让受限玻尔兹曼机变得可用,更是推动整个深度学习领域向前发展的关键引擎之一。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...