多头自注意力机制(Multi-Head Self-Attention)是现代人工智能领域的基石之一,它是Transformer架构的核心组件,也是让 ChatGPT、BERT 等大模型能够真正“理解”语言的关键所在。
简单来说,如果把处理一句话比作“阅读理解”,单头注意力就像是你只用一支荧光笔在书上划重点,只能关注一种线索;而多头自注意力则像是让你带上8个不同颜色的荧光笔,同时从语法、指代、情感等不同角度去标记重点,最后综合这些信息来理解整句话。
核心原理:为什么要“多头”?
在多头机制出现之前,模型通常使用“单头自注意力”。它虽然能捕捉上下文关系,但视角单一。比如处理句子“The animal didn’t cross the street because it was too tired”时,单头机制可能很难同时兼顾“animal”和“it”的指代关系,以及“because”引导的因果关系。
多头自注意力机制通过并行计算多个“头(Head)”,让模型能够同时关注不同位置、不同子空间的信息:
- 头1:可能专注于语法结构(如主谓关系)。
- 头2:可能专注于指代消解(如“it”指代“animal”)。
- 头3:可能专注于情感色彩(如“tired”表达的状态)。
这种机制极大地丰富了模型的表达能力,使其能捕捉到长距离的上下文依赖。
工作流程:Q、K、V 是如何运作的?
多头自注意力的计算过程虽然数学公式看起来复杂,但逻辑非常清晰。它基于三个核心向量:查询(Query)、键(Key)、值(Value)。
你可以把这个过程想象成图书馆找书:
- Query (Q):是你手中的搜索条(你想找什么)。
- Key (K):是书架上每本书的标签(书的内容特征)。
- Value (V):是书的实际内容(你最终要获取的信息)。
具体计算步骤如下:
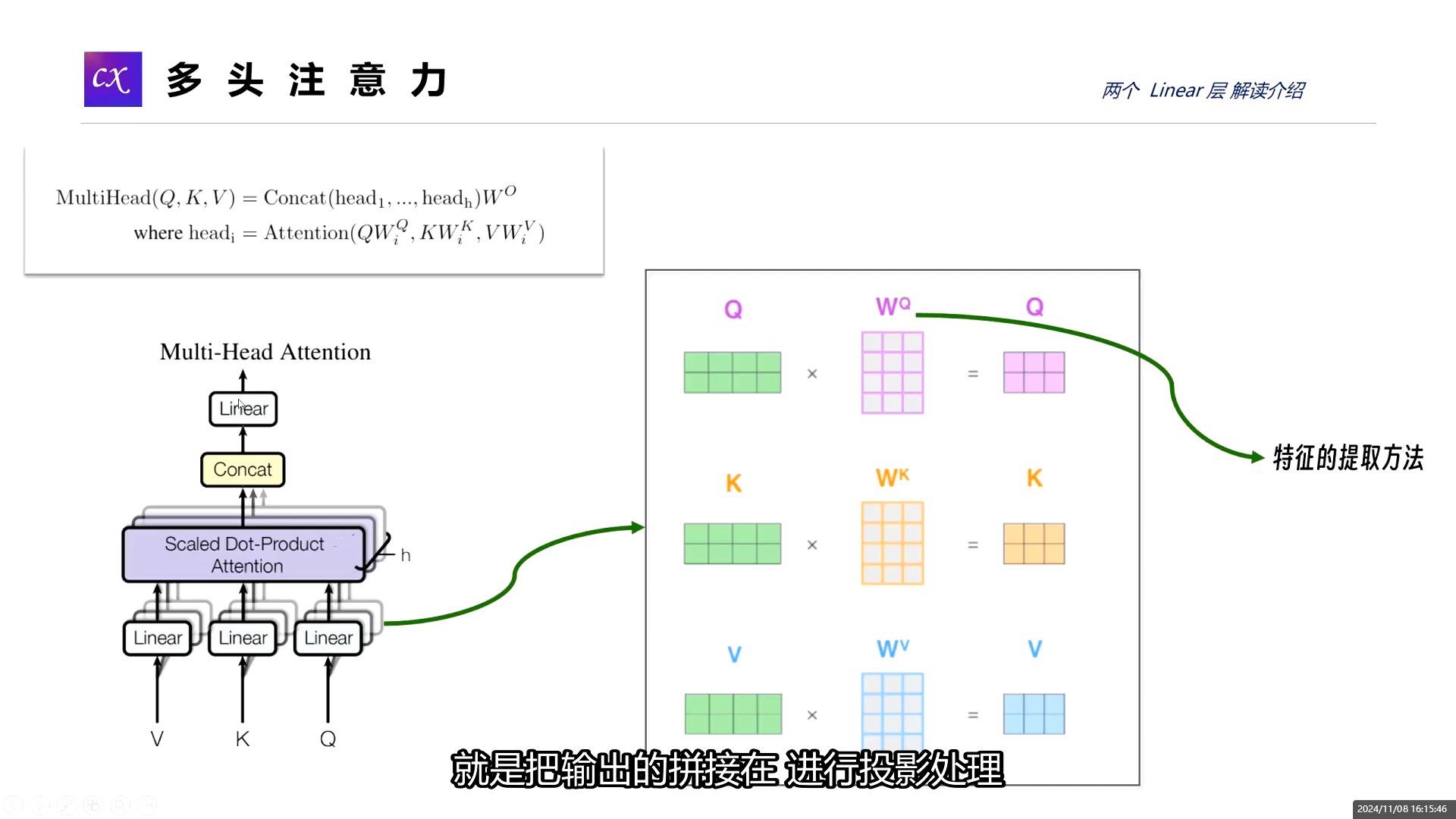
- 线性投影(生成 Q, K, V)
输入向量(比如一个词的词向量)会经过三个不同的权重矩阵变换,生成对应的 Q、K、V 向量。 - 切分多头
将 Q、K、V 切分成多个“头”。例如,如果模型维度是 512,有 8 个头,那么每个头就处理 64 维的信息。 - 并行计算注意力
每个头独立计算注意力分数。公式核心是计算 Q 和 K 的相似度(点积),然后通过 Softmax 归一化得到权重,最后用权重对 V 进行加权求和。- 公式:
Attention(Q, K, V) = softmax(QKᵀ / √dₖ) V
- 公式:
- 拼接与融合
将所有头的输出拼接起来,再通过一个线性层进行融合,得到最终的输出结果。
直观案例:一句话的“多视角”解读
假设输入句子是:“I love artificial intelligence”。
在多头自注意力机制下,模型会这样处理:
表格
| 注意力头 | 关注焦点 | 捕捉到的关系 |
|---|---|---|
| 头 1 (语法头) | 关注词性搭配 | 识别出 “love” 是动词,”I” 是主语。 |
| 头 2 (语义头) | 关注修饰关系 | 识别出 “artificial” 是用来修饰 “intelligence” 的。 |
| 头 3 (关联头) | 关注整体语境 | 识别出 “I” 和 “intelligence” 之间的潜在联系(我是智能的使用者)。 |
通过这种方式,模型生成的每一个词的表示,都融合了来自不同角度的丰富信息。
最新演进:从 MHA 到 MLA
随着大模型越来越强,传统的多头自注意力机制(MHA)也面临挑战,主要是显存占用高和推理速度慢(因为要存储巨大的 KV 缓存)。
为了解决这个问题,业界提出了创新的改进版本,例如DeepSeek提出的多头潜在注意力(Multi-Head Latent Attention, MLA):
- 核心改进:将键(K)和值(V)投影到低维的“潜在空间”,进行压缩。
- 效果:在 DeepSeek V2/V3 等模型中,MLA 将 KV 缓存大小压缩至传统 MHA 的 1/4 至 1/8,显著提升了推理速度,同时保持了模型性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...