
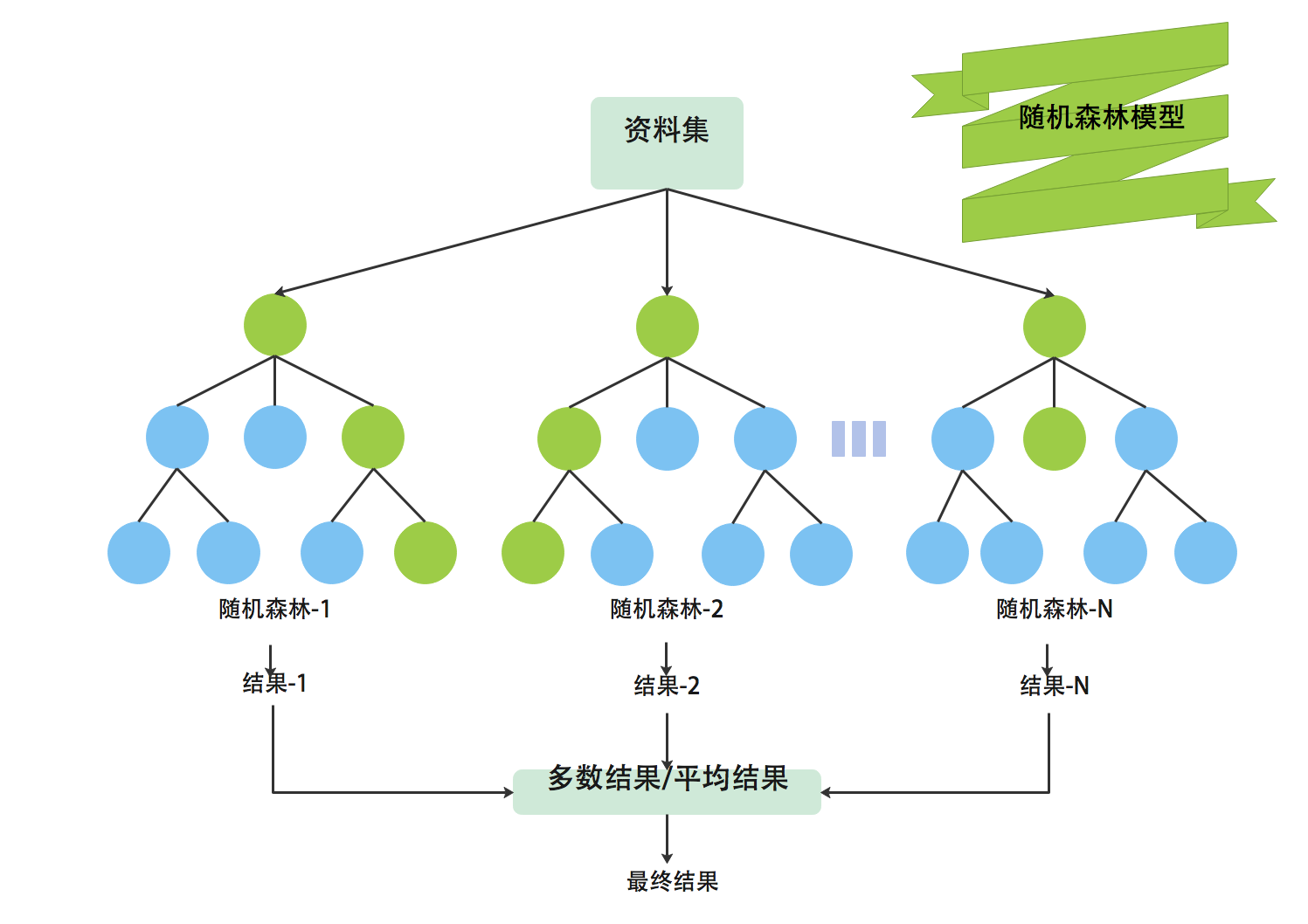
随机森林(Random Forest)是机器学习领域中一种强大且应用广泛的集成学习算法。你可以把它想象成一个由众多专家(决策树)组成的“智囊团”,通过集体决策来得出更可靠、更准确的结论。
它之所以广受欢迎,是因为它不仅能处理分类和回归等多种任务,还具备出色的抗过拟合能力和良好的可解释性。
核心思想:集思广益
随机森林的核心思想非常直观:“三个臭皮匠,顶个诸葛亮”。
单个决策树虽然易于理解,但容易“钻牛角尖”(即过拟合),过度记忆训练数据中的噪声和细节,导致在新数据上表现不佳。
随机森林通过构建大量各不相同的决策树,并让它们共同投票或取平均值,有效平滑了单棵树的片面性和不稳定性,从而得到一个泛化能力更强的模型。
工作原理:双重随机性
随机森林的“随机”二字,体现在构建每棵决策树时引入的两种随机性,这保证了树与树之间的差异性和独立性。
- 样本随机性 (Bootstrap抽样)
在训练每一棵树之前,算法会从原始训练数据集中进行有放回的随机抽样。这意味着每棵树都是在略有不同的数据子集上进行训练的,有些样本可能被多次抽到,而有些则一次都没被抽到(这些未被抽到的样本被称为“袋外数据”,可用于模型评估)。 - 特征随机性 (随机特征选择)
在决策树的每个节点进行分裂时,算法不会考虑所有特征,而是随机选择一个特征子集来寻找最优分裂点。这进一步增加了树的多样性,防止模型过度依赖某几个强特征。
预测方式:投票与平均
当模型训练完成,需要对新的数据进行预测时,随机森林会根据任务类型采取不同的策略:
- 分类任务 (如:判断邮件是否为垃圾邮件)
让森林里的每一棵树都对样本进行预测,然后统计所有树的预测结果,最终结果由多数投票决定。 - 回归任务 (如:预测房价)
让每一棵树都输出一个预测值,最终的预测结果是所有树预测值的平均值。
优缺点分析
随机森林作为一种经典算法,其优势非常明显,但也存在一些局限性。
优点
- 准确率高:通过集成多棵树的预测,通常能获得比单棵决策树更高的精度。
- 抗过拟合:双重随机性机制使其对数据中的噪声不敏感,泛化能力出色。
- 可评估特征重要性:能够量化每个特征对预测结果的贡献度,帮助理解数据和进行特征选择。
- 鲁棒性强:对异常值和缺失值不敏感,能处理高维数据。
缺点
- 模型复杂,可解释性较差:相比于单棵决策树清晰的判断路径,由成百上千棵树组成的森林更像一个“黑盒”,难以直观解释。
- 训练和预测速度较慢:构建大量决策树需要更多的计算资源和时间。
- 可能过拟合噪声:在某些噪声非常大的数据集上,如果树的深度不受限制,仍然可能出现过拟合。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...