
- 决策树就像一位专家,他根据自己的经验做判断,但可能因为个人偏见或知识盲区而犯错。
- 随机森林则像一个专家委员会,它汇集了众多专家的意见,通过投票来做出最终决策,结果通常更可靠、更稳定。
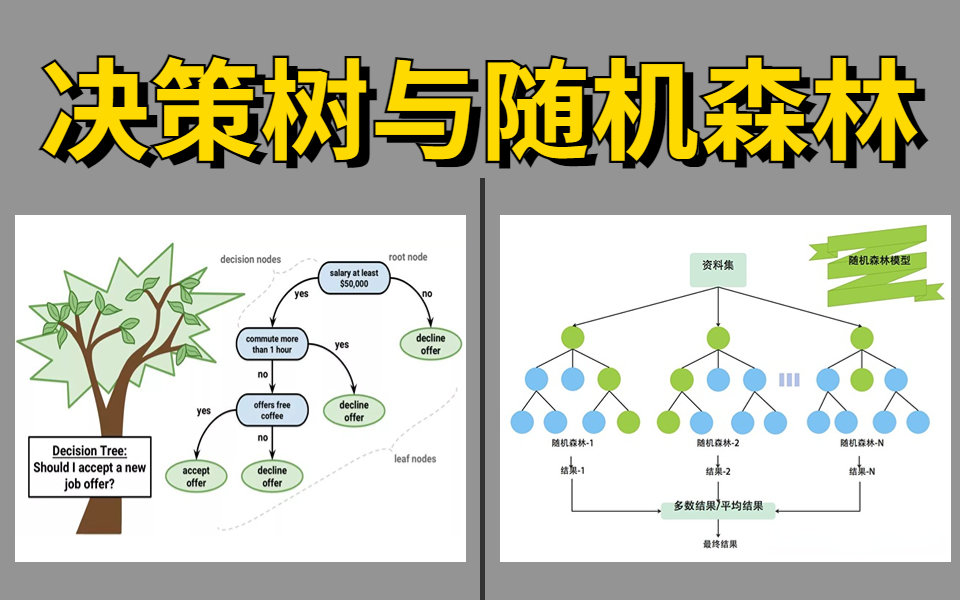
什么是决策树?
决策树是一种直观易懂的算法,它通过一系列“是/否”问题来对数据进行分类或预测。它像一棵倒置的树,从根节点开始,根据特征不断向下分裂,直到叶子节点得出最终结论。
- 优点:
- 可解释性强:决策过程清晰透明,可以画出树状图,让人一目了然地理解其判断逻辑。
- 使用简单:对数据预处理要求不高,无需标准化,能处理数值和类别型数据。
- 缺点:
- 容易过拟合:单棵决策树容易过度学习训练数据中的细节和噪声,导致在未见过的数据上表现不佳。
- 不稳定:训练数据的微小变化可能导致生成一棵完全不同的树。
什么是随机森林?
随机森林是一种“集成学习”方法,它通过构建并组合多个决策树(即一片“森林”)来提升整体性能。它的核心思想是“三个臭皮匠,顶个诸葛亮”。
其工作原理包含两个关键的“随机”步骤,以保证每棵树的多样性:
- 样本随机性 (Bootstrap抽样):从原始数据集中有放回地随机抽取多个样本子集,每个子集用来训练一棵独立的决策树。
- 特征随机性:在构建每棵树的每个节点时,算法不会考虑所有特征,而是随机选择一个特征子集来寻找最优分裂点。
在预测时,随机森林会让所有树独立进行预测,然后通过投票(分类任务)或取平均值(回归任务)来确定最终结果。
- 优点:
- 准确率高:通过集成多棵树的预测,通常比单棵决策树更准确。
- 抗过拟合:双重随机性机制有效降低了过拟合风险,泛化能力更强。
- 稳定性好:对数据中的噪声和异常值不敏感。
- 缺点:
- 可解释性差:成百上千棵树的集合更像一个“黑盒”,难以直观解释其决策过程。
- 训练速度慢:构建大量决策树需要更多的计算资源和时间。
核心区别对比
表格
| 特性 | 决策树 | 随机森林 |
|---|---|---|
| 模型结构 | 单一的树结构 | 多棵树的集合(森林) |
| 过拟合风险 | 高 | 低 |
| 预测精度 | 较低 | 较高 |
| 可解释性 | 强,决策路径清晰可见 | 弱,整体决策过程复杂 |
| 训练速度 | 快 | 慢(取决于树的数量) |
| 稳定性 | 差,对数据变化敏感 | 好,鲁棒性强 |
概括与选择建议
- 选择决策树:当你需要模型具有极强的可解释性,或者在数据量较小、需要快速验证想法时。例如,在医疗诊断或金融风控中,需要清晰地解释“为什么拒绝这笔贷款”。
- 选择随机森林:当你追求更高的预测精度和稳定性,且可以牺牲一部分可解释性时。它通常是工业界解决分类和回归问题的首选“开箱即用”算法。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...