
支持向量机(Support Vector Machine,简称 SVM)是机器学习中一种强大且经典的监督学习算法,主要用于分类和回归分析。它的核心思想非常直观:寻找一个最优的决策边界,来尽可能清晰地将不同类别的数据分开。
你可以把它想象成在两种不同颜色的豆子之间,寻找一条最宽阔的“护城河”,以确保未来出现新的豆子时,能准确无误地判断它属于哪一类。
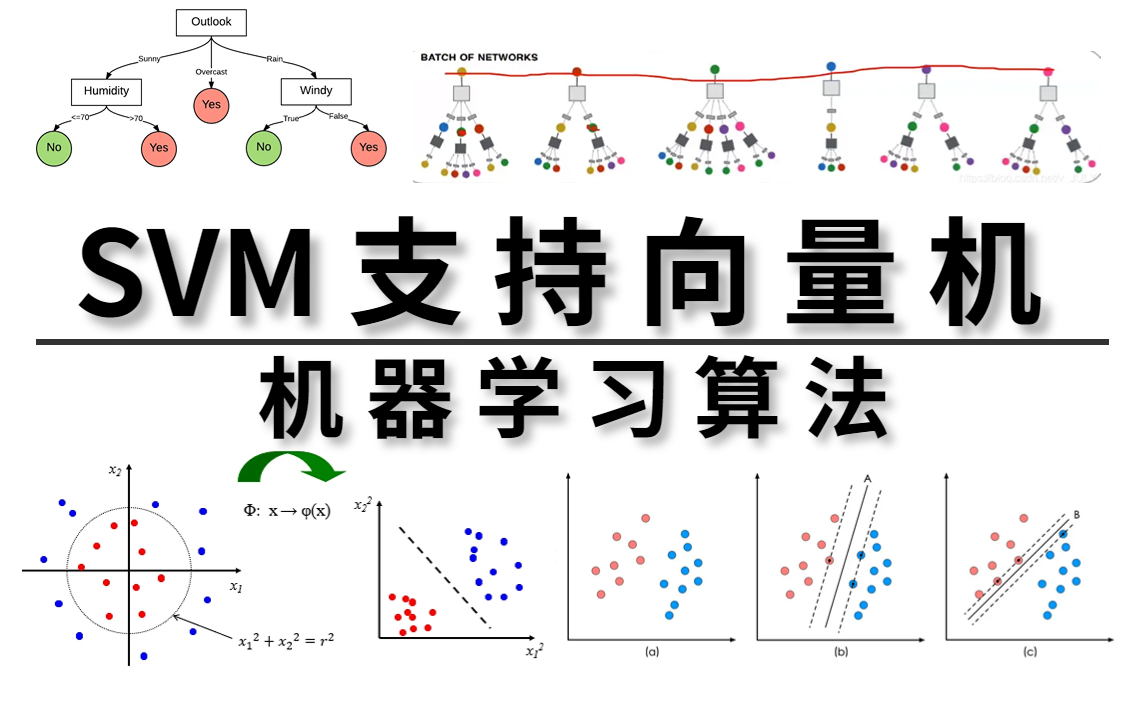
核心思想:最大化间隔
SVM的基本原理可以分解为以下几个关键概念:
- 超平面 (Hyperplane)
这是 SVM 找到的决策边界。- 在二维空间中,它是一条直线。
- 在三维空间中,它是一个平面。
- 在更高维度的空间中,它被称为超平面。
它的任务是将不同类别的数据点划分到两侧。
- 支持向量 (Support Vectors)
这是SVM算法名称的由来,也是最关键的部分。支持向量是距离超平面最近的那些数据点。- 它们就像“护城河”两岸最前线的“哨兵”。
- 最终的超平面位置完全由这些支持向量决定。移除其他非支持向量的数据点,不会影响超平面的位置;但一旦移动或删除支持向量,超平面就会发生改变。
- 间隔 (Margin)
间隔是超平面与支持向量之间的垂直距离。SVM的目标就是找到一个超平面,使得这个间隔(也就是“护城河”的宽度)最大化。- 为什么最大化间隔很重要? 间隔越大,分类器的“容错空间”就越大,对未知数据的泛化能力就越强,越不容易因为数据中的微小噪声而产生误判。
处理复杂数据:核技巧
现实世界中的数据往往不是那么简单,无法用一条直线或一个平面清晰地分开(即非线性可分)。SVM 通过一个非常巧妙的“核技巧”来解决这个问题。
- 核心思想:将原本在低维空间中纠缠不清的数据,映射到一个更高维度的空间。
- 神奇效果:在高维空间中,这些数据可能就变得线性可分了。这就好比在二维平面上,一个圆圈里的点和圆圈外的点无法用直线分开;但如果把它们投射到三维空间,形成一个圆锥体,就可以用一个平面轻松切开。
- 核函数:这个映射过程是通过一个数学函数——核函数——来高效完成的,它避免了直接在高维空间进行复杂计算的麻烦。常见的核函数包括:
- 线性核:用于线性可分的数据。
- 径向基函数核 (RBF):最常用的核函数,能处理复杂的非线性关系。
- 多项式核:用于捕捉特征间的多项式关系。
优点与局限性
优点
- 高维空间表现优异:即使特征数量远大于样本数量,SVM也能表现出色,非常适合文本分类、生物信息学等领域。
- 强大的泛化能力:通过最大化间隔,SVM能有效防止过拟合,对未见过的数据有很好的预测能力。
- 内存高效:模型的预测只依赖于少数支持向量,而非全部训练数据,因此在预测阶段非常高效。
局限性
- 计算复杂度高:训练SVM涉及求解一个复杂的二次规划问题,当数据量非常大时,训练速度会很慢。
- 对参数敏感:SVM的性能高度依赖于对核函数和正则化参数(如C和gamma)的选择,参数调优需要一定的经验和技巧。
- 可解释性较差:尤其是使用非线性核函数时,SVM更像一个“黑盒”模型,难以直观解释其决策过程。
概括
总而言之,支持向量机是一种通过寻找最大间隔超平面来进行分类的算法。它利用“支持向量”来确定边界,并借助“核技巧”巧妙地处理非线性问题,使其成为处理高维、小样本数据的强大工具。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...