K近邻算法(KNN)和K均值聚类(K-Means)虽然名字里都有一个“K”,但它们是两个目的、原理和应用场景都截然不同的算法。
核心区别对比
表格
| 特性 | K近邻算法 (KNN) | K均值聚类 (K-Means) |
|---|---|---|
| 算法类型 | 监督学习 | 无监督学习 |
| 任务目标 | 分类(主要)、回归 | 聚类 |
| 数据要求 | 需要已标注的训练数据 | 只需要未标注的特征数据 |
| “K”的含义 | 预测时参考的最近邻居的数量 | 预先指定的聚类簇的数量 |
| 工作原理 | “近朱者赤,近墨者黑” | “物以类聚,人以群分” |
| 学习模式 | 惰性学习,没有显式训练过程 | 急切学习,需要通过迭代训练找到聚类中心 |
深入理解
K近邻算法 (KNN) – “看邻居”
KNN 的核心思想非常直观:要判断一个未知样本的类别,就看它周围最近的K个“邻居”大多属于哪个类别。
- 比喻:“近朱者赤,近墨者黑”。你想知道一个人是什么样的人,就去看看他关系最好的K个朋友是什么样的人。
- 工作流程:
- 你有一堆已经贴好标签的数据(例如,已知一些点是“猫”还是“狗”)。
- 来了一个新的未知数据点。
- 计算这个新点到所有已知点的距离。
- 找出距离最近的K个点(邻居)。
- 分类任务:看这K个邻居中,哪种标签最多,就把新点归为哪一类(多数投票)。
- 回归任务:取这K个邻居目标值的平均值作为新点的预测值。
- 关键点:KNN没有“训练”阶段,它只是把所有训练数据“记住”。计算都发生在预测阶段,因此它也被称为“惰性学习器”。
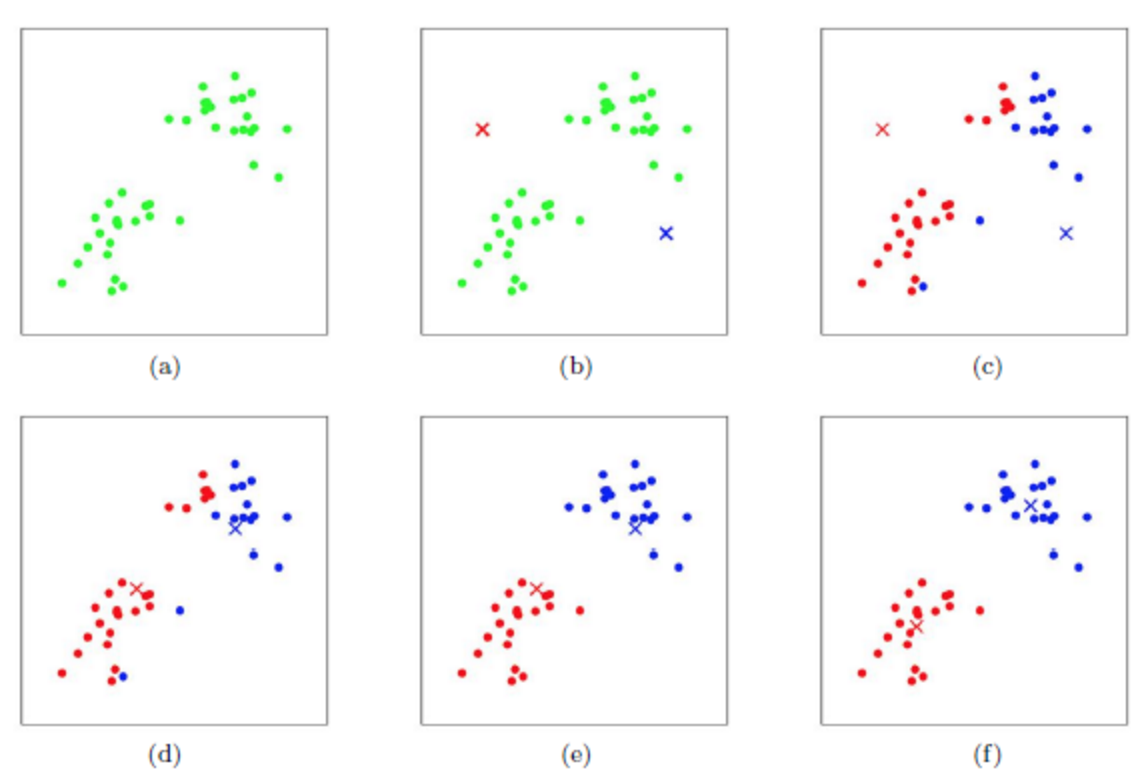
K均值聚类 (K-Means) – “分小组”
K-Means 的目标是在没有标签的情况下,自动将数据划分成K个内部相似、彼此不同的“簇”(Cluster)。
- 比喻:老师让一个班的学生自动分成K个小组,要求是同一个小组里的人要尽量彼此靠近。
- 工作流程:
- 首先,你告诉算法要分成K个组。
- 算法随机选择K个点作为初始的“聚类中心”(质心)。
- 分配:计算每个数据点到K个中心的距离,把它分配给最近的那个中心所在的簇。
- 更新:重新计算每个簇所有点的平均值,将这个平均值作为新的聚类中心。
- 重复“分配”和“更新”步骤,直到聚类中心不再变化或达到最大迭代次数。
- 关键点:K-Means有一个明确的“训练”过程,即通过迭代来找到最优的K个聚类中心。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...