K-Means(K均值)算法是一种经典的无监督学习算法,主要用于数据聚类分析。它的核心思想非常直观,可以概括为“物以类聚,人以群分”,目标是将数据自动划分成K个内部相似、彼此不同的“簇”(Cluster)。
核心思想与目标
K-Means算法旨在将n个数据点划分为K个簇,使得每个数据点都属于离它最近的簇中心(即质心,Centroid)所代表的簇。
算法的优化目标是最小化簇内平方误差和(SSE, Sum of Squared Errors)。简单来说,就是让同一个簇内的所有数据点都尽可能地靠近该簇的中心,从而使每个簇都足够紧凑。
其数学表达式为:
SSE = Σ (从i=1到K) Σ (x∈Ci) ||x - μi||²K:预先设定的簇的数量。Ci:第i个簇。x:簇Ci中的一个数据点。μi:簇Ci的质心(即该簇所有点的均值向量)。
算法工作流程
K-Means算法通过迭代的方式不断优化聚类结果,直到收敛。其工作流程可以分为以下四个步骤:
- 初始化 (Initialization)
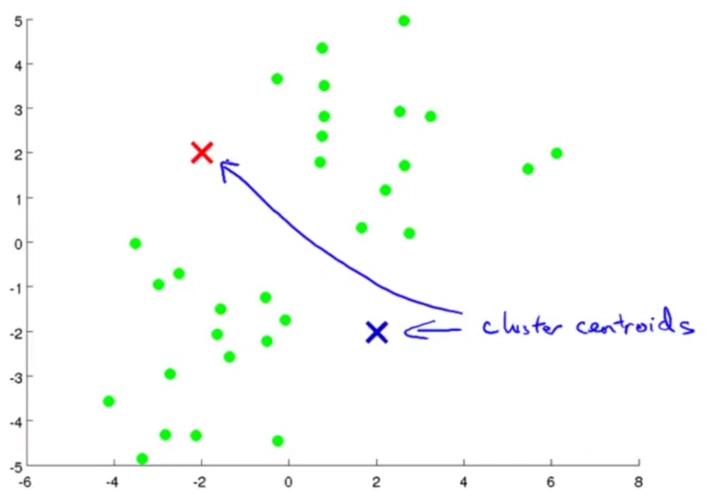
首先,需要指定要划分的簇的数量K。然后,从数据集中随机选择K个数据点作为初始的质心。 - 分配 (Assignment)
计算每个数据点到这K个质心的距离(通常使用欧氏距离),然后将每个数据点分配给距离它最近的那个质心所代表的簇。 - 更新 (Update)
当所有数据点都完成分配后,重新计算每个簇的质心。新的质心就是该簇内所有数据点在各个维度上的平均值。 - 迭代与收敛 (Iterate & Converge)
重复执行“分配”和“更新”这两个步骤。每一次迭代都会使质心的位置发生移动,并让簇内的数据点更加紧凑。当质心的位置不再发生显著变化,或者达到预设的最大迭代次数时,算法停止,聚类完成。
优缺点分析
K-Means算法因其简单高效而广受欢迎,但也存在一些固有的局限性。
优点
- 原理简单,易于理解和实现。
- 计算效率高,时间复杂度约为 O(nkt),其中n是样本数,k是簇数,t是迭代次数,因此适合处理大规模数据集。
- 当数据的簇结构是凸形(如球形)且大小相近时,聚类效果非常好。
缺点
- 需要预先指定K值:K值的选择对结果影响很大,但通常很难事先确定最优的K值,需要借助肘部法则、轮廓系数等方法来辅助判断。
- 对初始质心敏感:随机初始化可能导致算法收敛到局部最优解,而非全局最优解。多次运行或使用K-means++等优化初始化方法可以缓解此问题。
- 对异常值敏感:由于质心是簇内所有点的均值,少数远离主体的异常值会显著拉偏质心的位置,影响聚类效果。
- 不适合非凸形状的簇:K-Means倾向于找到球形簇,对于环形、月牙形等复杂形状的簇,聚类效果不佳。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...