
FIPO是阿里巴巴通义实验室(Qwen Team)最新发布的大模型强化学习算法。
它的全称是Future-KL Influenced Policy Optimization(未来KL散度影响策略优化)。这项技术主要解决的是大模型在“长推理”过程中容易变笨、逻辑混乱或推理停滞的问题。
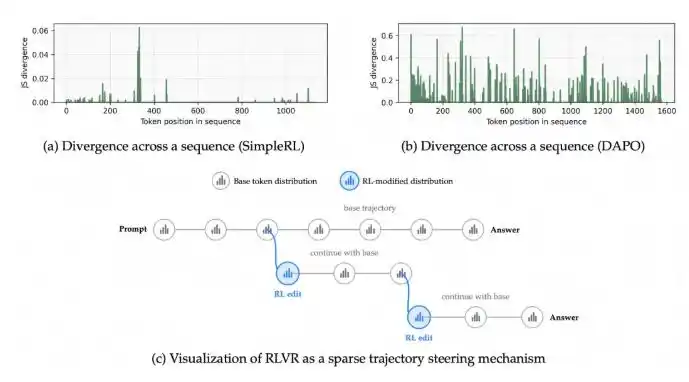
1. 它是做什么的?
FIPO是一种用于后训练(Post-training)阶段的强化学习算法。
- 解决的问题:传统的强化学习(如 GRPO)在给模型“发奖金”时比较粗糙,只要最终答案对了,就把奖励平均分给推理过程中的每一步。这导致模型分不清哪些步骤是关键逻辑,哪些是废话,甚至会出现“自我误导”(Oops Moment)——即算出正确答案后,又自己把自己带偏。
- 核心创新:FIPO 引入了 Future-KL 机制。它能计算出每一个 Token(词元)对后续推理轨迹的影响力。
- 如果某个步骤对后续的正确推理有正向影响,就给予高权重奖励。
- 如果某个步骤导致了后续的跑偏,就进行抑制。
- 简单说,它实现了Token 级别的精准信用分配,让模型知道哪一步是“神来之笔”,哪一步是“画蛇添足”。
2. 核心能力与数据表现
根据通义实验室在Qwen2.5-32B-Base 模型上的测试结果,FIPO 展现了惊人的效果:
表格
| 指标 | 传统算法 (如 DAPO/GRPO) | FIPO 算法 | 提升效果 |
|---|---|---|---|
| 平均推理长度 | 约 4,000 Tokens | > 10,000 Tokens | 推理深度大幅提升,能处理更复杂的难题 |
| 数学准确率 | 50.0% (AIME 2024) | 58.0% | 在纯强化学习设置下超越 o1-mini 等同规模模型 |
| 关键发现 | 难以识别关键逻辑点 | 识别“稀疏但关键”Token | 仅调整约 2% 的关键 Token 即可恢复模型性能 |
3. 为什么它很重要?
- 打破“推理长度停滞”:以前模型想变聪明,往往需要堆砌更长的推理链,但很容易在中间“迷路”。FIPO让模型能维持更长、更稳定的逻辑链条。
- 开源贡献:通义团队已经开源了相关的论文、代码和模型。这意味着开发者可以利用FIPO算法,在不依赖海量长推理数据的情况下,训练出具备深度思考能力的模型。
- 减少“自我误导”:统计显示,模型出现“顿悟时刻”(Aha Moment)的概率仅约 1%,而出现“自我误导”(Oops Moment)的概率约 3%。FIPO 通过精准奖励机制,有效降低了这种自我否定的情况。
FIPO的项目地址
- GitHub仓库:https://github.com/qwenpilot/FIPO
- arXiv技术论文:https://arxiv.org/pdf/2603.19835
FIPO的同类竞品对比
| 对比维度 | FIPO | DAPO | GRPO |
|---|---|---|---|
| 核心机制 | Future-KL自举估计 | 非对称裁剪+动态采样 | 组相对优势+KL惩罚 |
| 信用分配 | Token级精准(识别2%关键Token) | 轨迹级平均(所有Token同等奖励) | 轨迹级平均(所有Token同等奖励) |
| 冷启动数据 | 不需要长CoT数据 | 不需要长CoT数据 | 不需要长CoT数据 |
| 推理长度 | 10k+ Token(持续增长) | ~4k Token(停滞瓶颈) | ~4k Token(停滞瓶颈) |
| AIME 2024(32B) | 58%(峰值) | 50% | ~47% |
| vs o1-mini | 超越(56%) | 未超越 | 未超越 |
| 优势估计方式 | Future-KL影响力权重 | 统一组优势 | 统一组优势 |
| 训练稳定性 | 三重防护(防梯度爆炸) | 标准动态采样 | 易出现熵崩溃 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...