
监督学习的任务就是学习一个模型,应用这个模型,对给定的输入预测相应的输出。这个模型一般为决策函数:Y=f(X) 或 条件概率分布:P(Y|X)。
监督学习的学习方法可以分为生成方法(generative approach)和判别方法(discriminative approach)。所学到的模型分别叫生成模型和判别模型。
生成方法
定义
由数据学习联合概率分布P(X,Y), 然后由P(Y|X)=求出概率分布P(Y|X)。该方法表示了给定输入X产生输出Y的生成关系。
典型模型
朴素贝叶斯方法、隐马尔可夫模型
特点
生成方法可以还原出联合概率分P(X,Y),而判别方法不能;生成方法的学习收敛速度更快,当样本容量增加的时候,学到的模型可以更快的收敛于真实模型;当存在隐变量时,仍可以利用生成方法学习,此时判别方法不能用。
注释
当我们找不到引起某一现象的原因的时候,我们就把这个在起作用,但是,无法确定的因素,叫“隐变量”
判别方法
定义
由数据直接学习决策函数Y=f(X)或条件概率分布P(Y|X)作为预测模型,即判别模型。判别方法关心的是对于给定的输入X,应该预测什么样的输出Y。
典型模型
k近邻法、感知机、决策树、逻辑斯谛回归模型、最大熵模型、支持向量机、提升方法、条件随机场
特点
判别方法直接学习的是决策函数Y=f(X)或条件概率分布P(Y|X),直接面对预测,往往学习准确率更高;由于直接学习P(Y|X)或f(X),可以对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习问题。
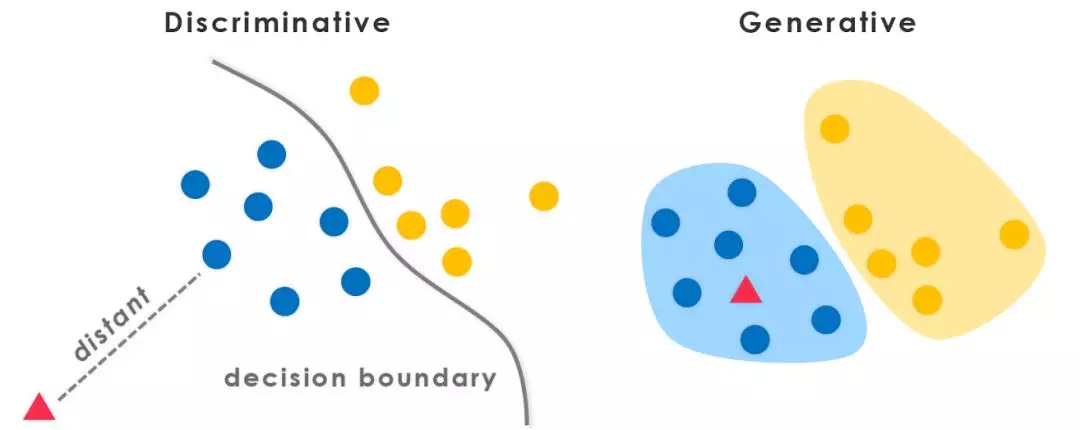
这里给你一份清晰、好记、不绕弯的版本,直接对比生成式模型 vs 判别式模型。
生成式模型 vs 判别式模型(核心区别)
1. 一句话区分
- 生成式模型:学习数据是怎么来的,试图 “造出” 数据。
- 判别式模型:学习数据之间怎么区分,只负责 “判断”。
2. 直观例子
给你一堆猫和狗的图片:
- 生成式:先学会猫长啥样、狗长啥样,能画出新的猫 / 狗。
- 判别式:只学怎么分清猫和狗,不会画图,只会分类。
3. 数学本质
- 生成式模型:建模 联合概率 P (X,Y)
会学习整个数据分布。
- 判别式模型:建模 条件概率 P (Y|X)
给定 X,直接判断 Y。
4. 典型模型
生成式模型
- 朴素贝叶斯
- 隐马尔可夫模型 HMM
- 高斯混合模型 GMM
- GAN、VAE、大语言模型(GPT 类)
判别式模型
- 逻辑回归
- 决策树、随机森林
- SVM
- 神经网络分类器
- BERT 等分类 / 理解模型
5. 优缺点对比
生成式模型
✅ 优点:
- 能生成新数据(文本、图像、语音)
- 数据少的时候也能学
- 可处理缺失数据、异常点
❌ 缺点:
- 计算量大
- 分类精度通常不如判别式
判别式模型
✅ 优点:
- 分类 / 预测更准
- 简单、高效、任务导向
❌ 缺点:
- 不能生成新样本
- 依赖大量标注数据
6. 最简单总结
- 想创造内容、生成数据 → 生成式模型
- 想分类、识别、预测、判断 → 判别式模型
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...