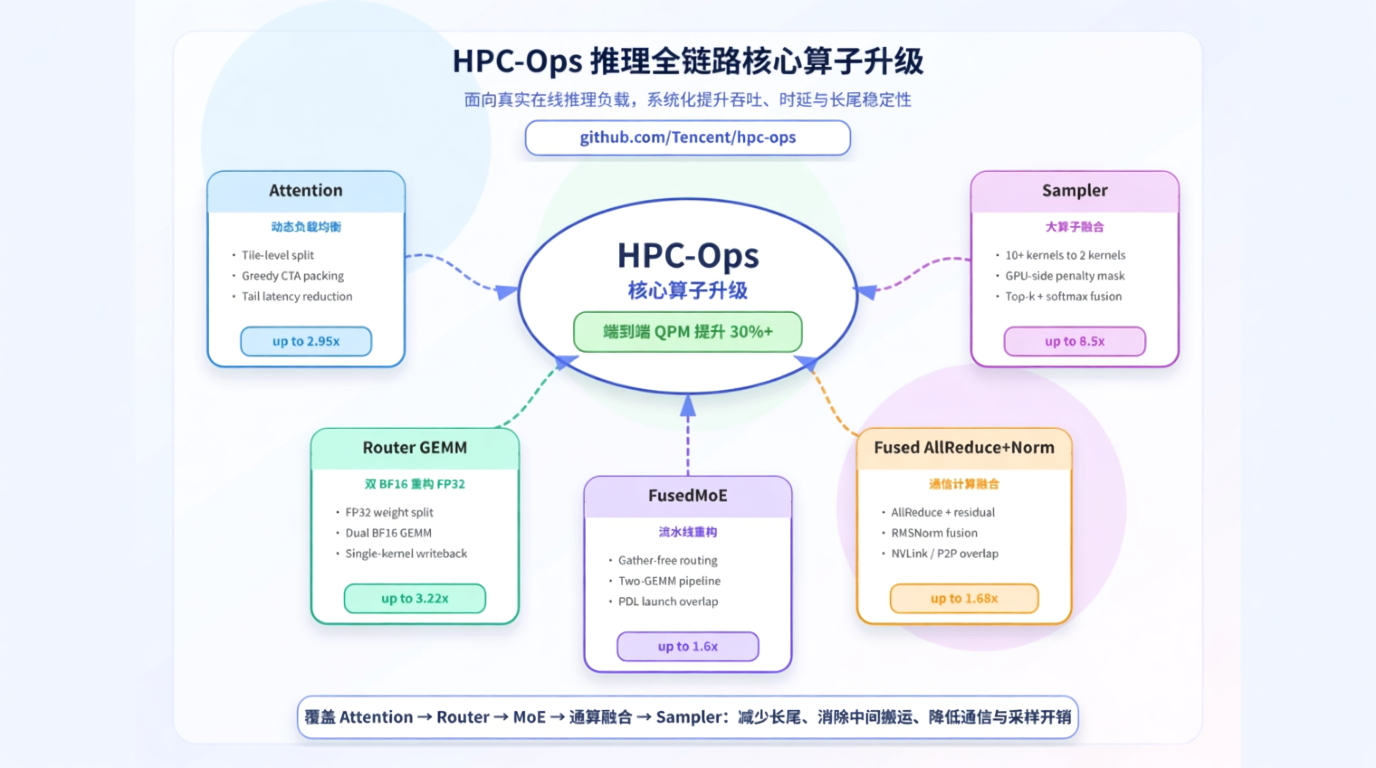
HPC-Ops – 腾讯混元开源的工业级大模型推理核心算子库HPC-Ops是腾讯混元AI Infra团队开源的工业级高性能大语言模型(LLM)推理核心算子库,专为解决真实业务场景中的推理性能瓶颈而设计。通过微架构级优化与动态调度技术,显著提升大模型推理吞吐量...AI最新项目2周前0310
Tuanjie Cowork – Unity中国专为游戏开发者打造的AI编程智能体Tuanjie Cowork是Unity中国专为游戏开发者打造的AI编程智能体,深度集成Unity与团结引擎生态,核心能力在于直接读取完整项目上下文(包括场景结构、资源管线、编辑器状态等引擎特有数据...AI最新项目2周前0320
Hojo-ASR-V1 – Hojo开源的语音识别(ASR)模型Hojo-ASR-V1是初创团队Hojo开源的语音识别(ASR)模型,采用Whisper特征提取器+Conformer适配层+Qwen3-4B语言模型的混合架构,在LibriSpeech Clean等...AI最新项目2周前0330
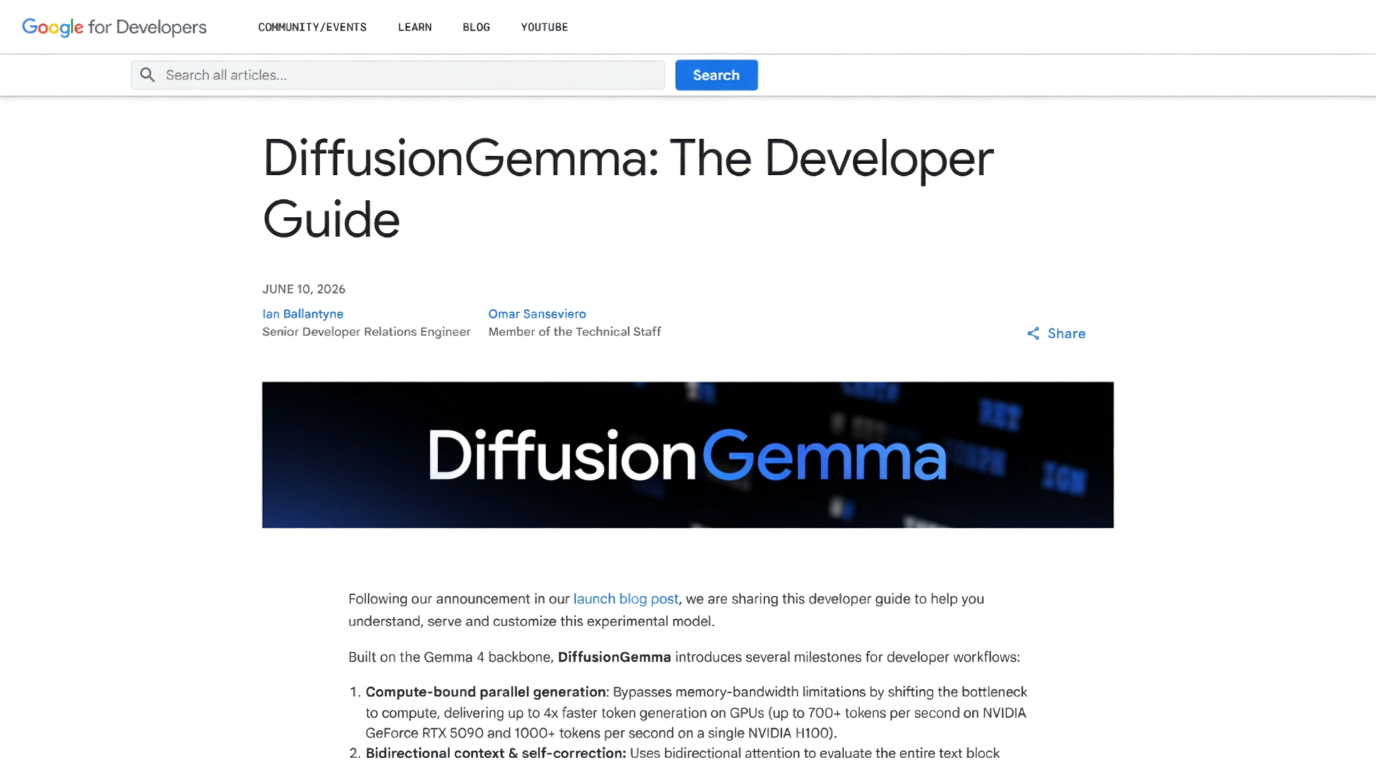
DiffusionGemma – 谷歌发布的实验性开源文本扩散模型DiffusionGemma是谷歌发布的实验性开源文本扩散模型,基于Gemma 4架构构建,通过并行生成机制将本地推理速度提升至传统自回归模型的4倍。 它并非替代标准Gemma 4的生产模型,而是专为...AI最新项目2周前0330
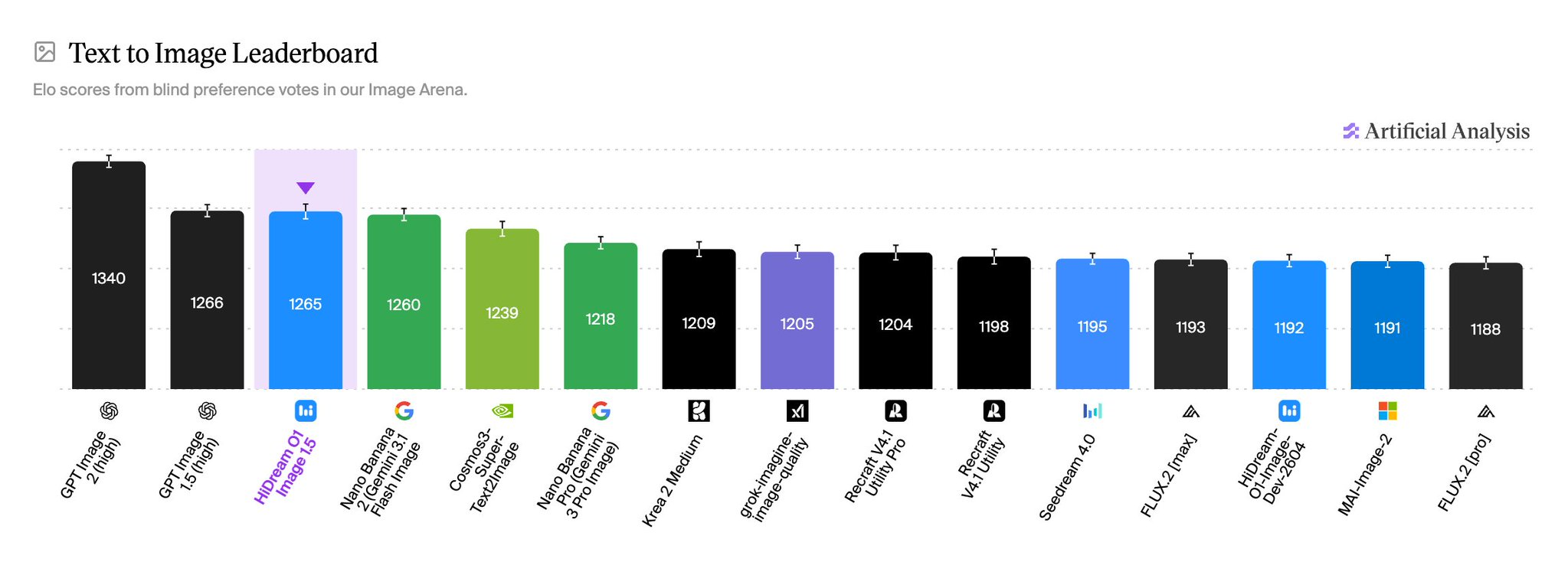
HiDream-O1-Image-1.5 – 智象未来推出的商用版图像生成模型HiDream-O1-Image-1.5智象未来推出的商用版图像生成模型,在Artificial Analysis全球文生图榜单中评分1265ELO,位列中国第一、全球第二(仅次于OpenAI),采用...AI最新项目2周前0360
MiMo-V2.5-ASR – 小米开源的语音识别模型MiMo-V2.5-ASR是小米开源的语音识别模型,作为全链路语音交互系统的听觉基座,复杂真实场景下的高鲁棒性语音转写。它无需预设语种标签即可精准处理中英混说、方言交织、强噪音干扰等环境,在多人会议...AI最新项目2周前0380
MiMoCode V0.1.0 – 小米开源的终端原生AI编程助手MiMoCode V0.1.0是小米开源的终端原生AI编程助手,专为解决长周期编程任务中的信息丢失问题而设计,其核心突破在于通过独立Agent架构实现“越用越懂项目”的持续记忆能力,而非仅依赖模型自身...AI最新项目2周前0390
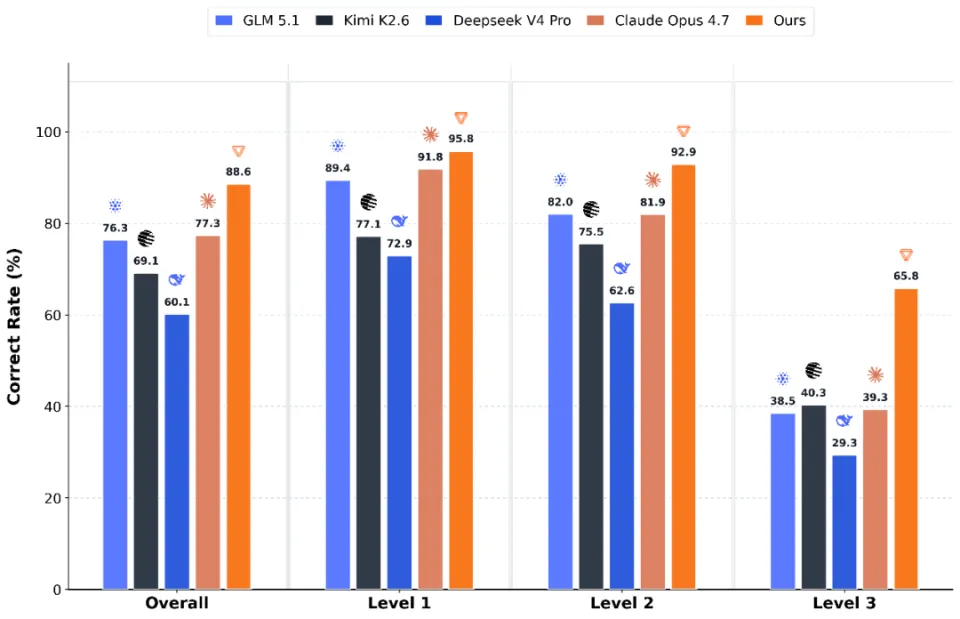
Claude Opus 4.7 – Anthropic推出的旗舰级大语言模型Claude Opus 4.7是Anthropic推出的旗舰级大语言模型,作为当时公开可用的最强代码与多模态模型,将AI从“对话助手”升级为“可自主执行复杂任务的智能体”。Claude Opus 4...AI最新项目2周前0300
MusaCoder – 摩尔线程推出的国产GPU全栈训练的代码大模型MusaCoder是摩尔线程推出的全球首个基于国产全功能GPU全栈训练的代码大模型,专为自动生成高性能GPU底层算子(CUDA/MUSA原生Kernel代码) 而设计,其完整训练与验证流程均在国产MT...AI最新项目2周前0320
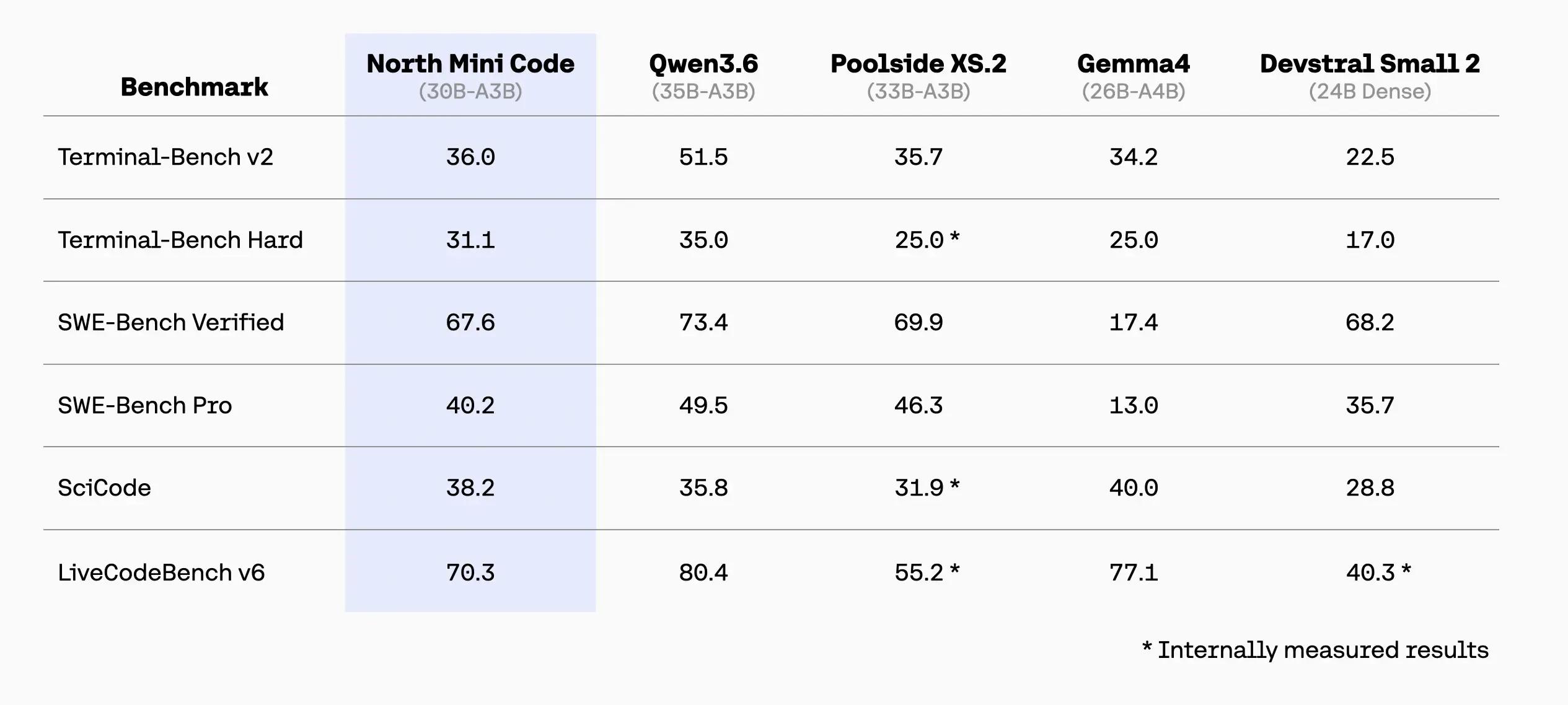
North Mini Code – Cohere公司推出的开源智能体编程大模型North Mini Code是Cohere公司推出的开源智能体编程大模型,核心定位为高吞吐、低延迟的代码智能体底座,采用30B总参数量但仅激活3B参数的稀疏混合专家(MoE)架构,专为本地化部署与企...AI最新项目2周前0270
Khala – 中央音乐学院与清华大学联合研发的音乐生成大模型Khala是中央音乐学院与清华大学联合研发的统一声学Token空间音乐生成大模型,解决AI音乐生成中结构连贯性与音质保真度的矛盾,通过构建跨模态对齐的声学表征体系,实现从深层音乐语义到高质量音频的端到...AI最新项目2周前0330
Gemini 3.5 Live Translate – 谷歌发布的实时语音互译音频模型Gemini 3.5 Live Translate是谷歌发布的实时语音互译音频模型,通过流式处理实现仅数秒延迟的连续语音翻译,同时保留说话者的原始语调、语速和情感特征,使跨语言对话接近真人同传体验。 ...AI最新项目2周前0360
MiMo-V2.5-Pro-UltraSpeed – 小米推出的超高速推理模式Xiaomi MiMo-V2.5-Pro-UltraSpeed是小米与TileRT团队联合推出的MiMo-V2.5-Pro模型的超高速推理模式,首次在通用GPU上实现万亿参数模型1000tokens...AI最新项目2天前0380
Claude Fable 5 – 首款面向公众开放的Mythos级大语言模型Claude Fable 5是Anthropic发布的首款面向公众开放的Mythos级大语言模型,与Claude Mythos 5共享同一底层架构,但通过安全机制限制高风险领域能力,使其成为目前公开可...AI最新项目2周前0450
新程Alpha – 明日新程公司推出的全球首个端侧认知模型新程Alpha是明日新程(Nextie)公司推出的全球首个端侧认知模型,参数量仅4B(40亿),通过将“知识记忆”与“思考能力”解耦,专注于泛化推理和抽象决策,在群体智能任务中表现等效于GPT-5.4...AI最新项目2周前0390
字节跳动ai产品有哪些字节跳动已构建覆盖对话交互、内容生成、编程开发、智能体应用四大核心场景的AI产品矩阵,以豆包大模型为技术底座,通过C端应用验证商业化路径,同时向B端企业服务和垂直领域深度渗透。目前主要产品线聚焦于降低...AI知识探索库2周前0440
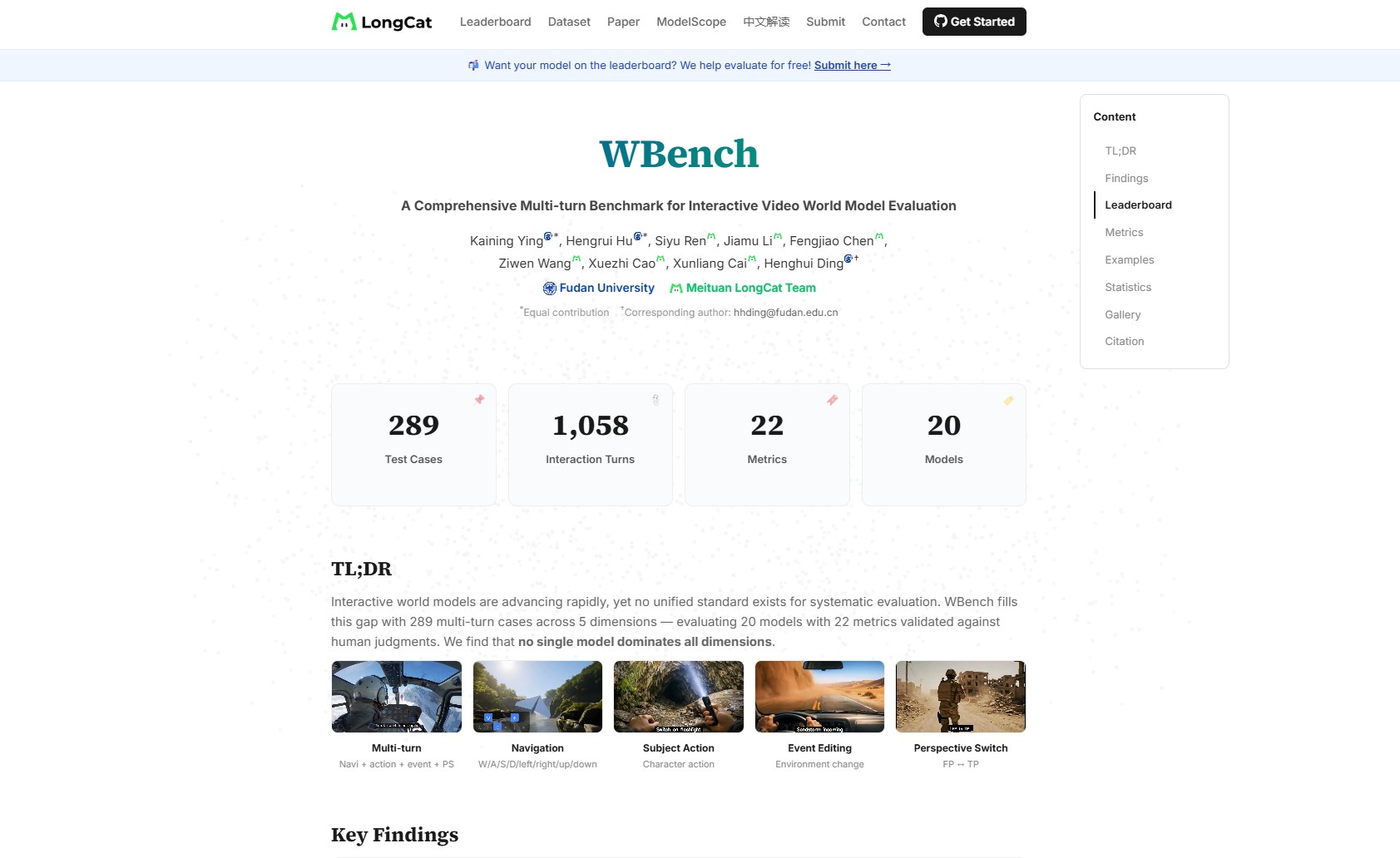
WBench – 首个面向交互式视频世界模型的系统性多轮评测基准WBench是美团LongCat团队与复旦大学联合发布的首个面向交互式视频世界模型的系统性多轮评测基准,首次实现对世界模型在连续交互、多维度能力上的统一量化评估,而非仅关注单次生成的视频质量。当前研究...AI最新项目2周前0360
SciDraw AI – 基于自然语言描述生成科研级科学插图的平台SciDraw AI是一个基于自然语言描述生成科研级科学插图的AI平台,通过AI技术将传统需数小时的手工绘图流程压缩至几分钟,无需专业设计基础即可快速生成符合期刊投稿标准的矢量图表,尤其适合跨学科科研...AI最新项目2周前0410
BigSet – TinyFish开源的多智能体协同网络抓工具BigSet是TinyFish团队开源的多智能体协同网络抓取与数据集构建工具,通过集成搜索、抓取、推理和验证的自动化流程,支持用户用自然语言指令实时生成结构化高质量数据集。将传统数据采集从手动操作升级...AI最新项目2周前0340
VitaBench 2.0 – LongCat推出的新一代大模型智能体评测基准VitaBench 2.0是美团LongCat团队联合多所高校推出的新一代大模型智能体评测基准,专注于评估智能体在长期、多轮次真实生活场景交互中的综合能力。 与早期版本相比,将评测维度从单次任务扩展至...AI最新项目2周前0340
库克最后一场WWDC:AI Siri登场 具体说啥了?2026苹果全球开发者大会(WWDC)今日正式开幕,全新一代Siri在现场正式亮相。本次大会上,苹果官宣与谷歌达成深度合作,将Gemini大模型融入Apple Intelligence体系,并搭建全新...AI资讯2周前0670
当我把今年高考语文作文题喂给AI 结构满分但缺真情实感2026年高考语文考试落幕,多家人工智能大模型“同题写作”引发热议。今年全国一卷以“词语理解的变化”为切入点,上海卷则聚焦“科技改造世界与人类想象力变化”,这些紧扣时代脉搏的思辨性命题,不仅考验着12...AI资讯2周前0640
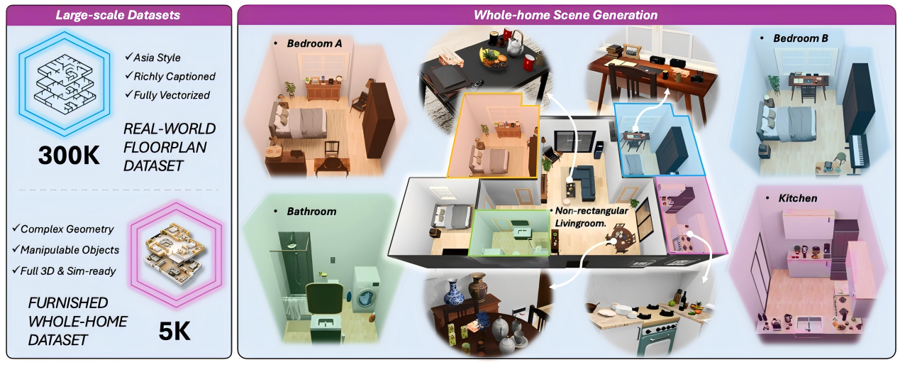
Kairos-HomeWorld – 大晓机器人发布的全屋三维可交互世界模型Kairos-HomeWorld是大晓机器人联合香港中文大学多媒体实验室、深圳河套学院发布的全球首个全屋三维可交互世界模型,仅需一句文本指令即可生成结构连贯、物理合理且支持物体级交互的完整中国家庭3D...AI最新项目2周前0370
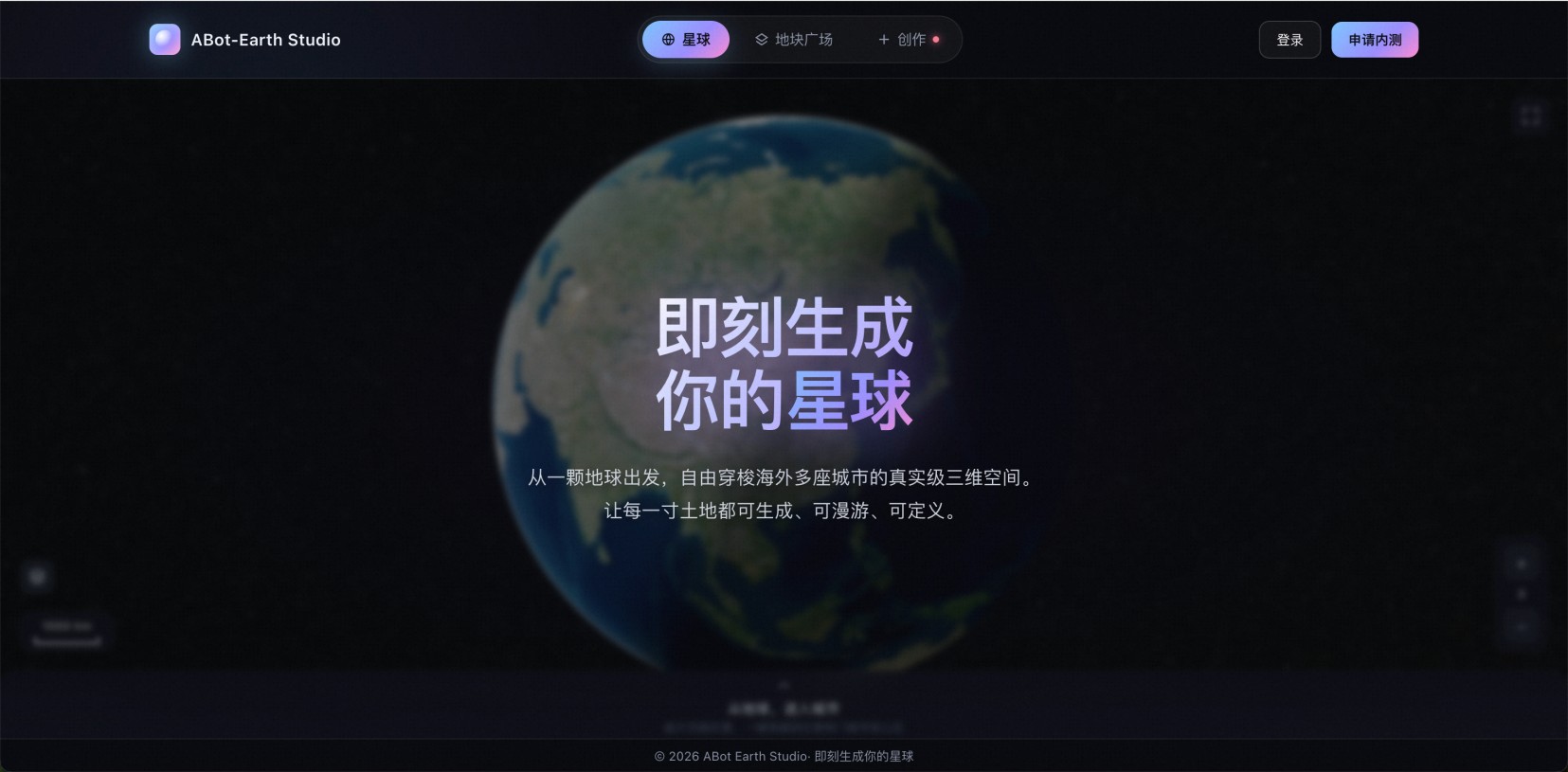
ABot-Earth0.5 – 高德地图发布全球首个3D原生城市世界模型ABot-Earth0.5是高德地图发布的全球首个3D原生城市世界模型,仅需单张卫星图像或文字描述,即可在10分钟内通过消费级GPU生成公里级可编辑3D城市场景。该模型将3D制图成本降至传统方式的百分...AI最新项目2周前0390
CopilotKit – 开源的前端智能体(Agent)应用开发框架CopilotKit是一个开源的前端智能体(Agent)应用开发框架,核心目标是让开发者能像搭积木一样快速构建深度集成AI能力的应用,而非仅添加一个聊天窗口。 通过 AG-UI 协议实现智能体与用户界...AI最新项目2周前0440
deepseek v4 flash – 深度求索发布的轻量化高效版大模型DeepSeek-V4-Flash是深度求索发布的轻量化高效版大模型,作为V4系列的“快速模式”版本,专为高频日常任务设计,在保持接近Pro版推理能力的同时,将响应速度和调用成本压缩至极致。以1/10...AI最新项目2周前0620
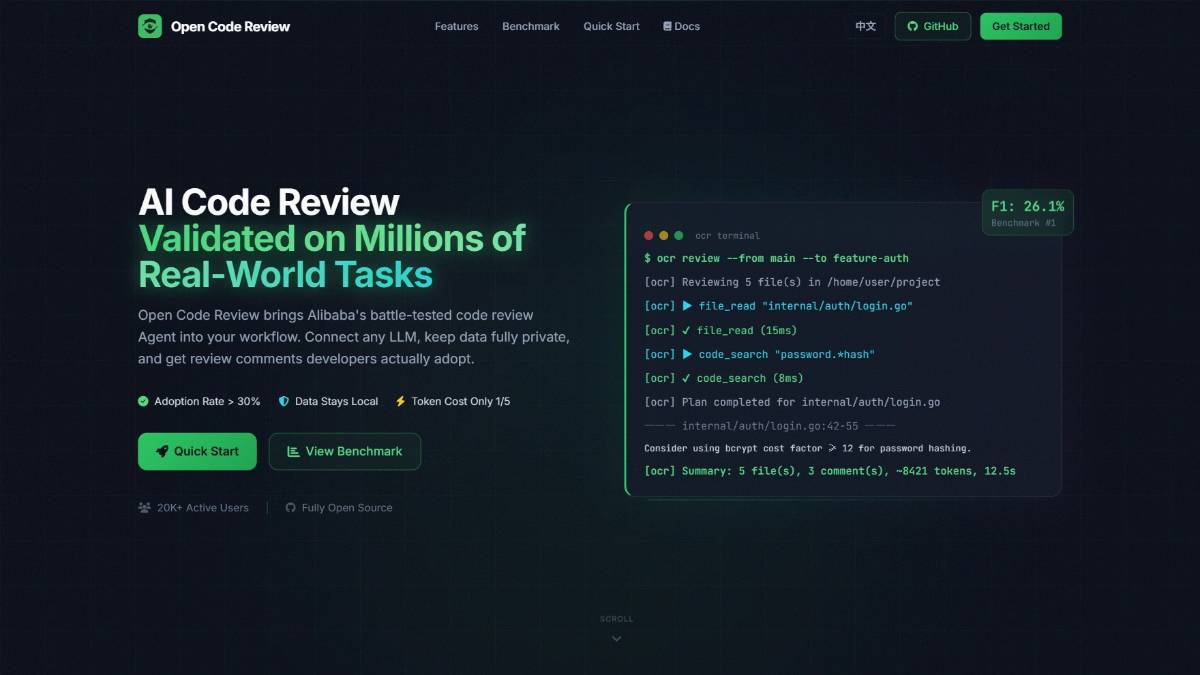
Open Code Review – 阿里巴巴开源的AI驱动代码审查工具Open Code Review是阿里巴巴开源的AI驱动代码审查工具,专为解决通用AI代理在代码审查中的覆盖不完整、位置漂移、质量不稳定等核心痛点而设计。将确定性工程与AI代理动态结合,既通过严格规则...AI最新项目2周前0500
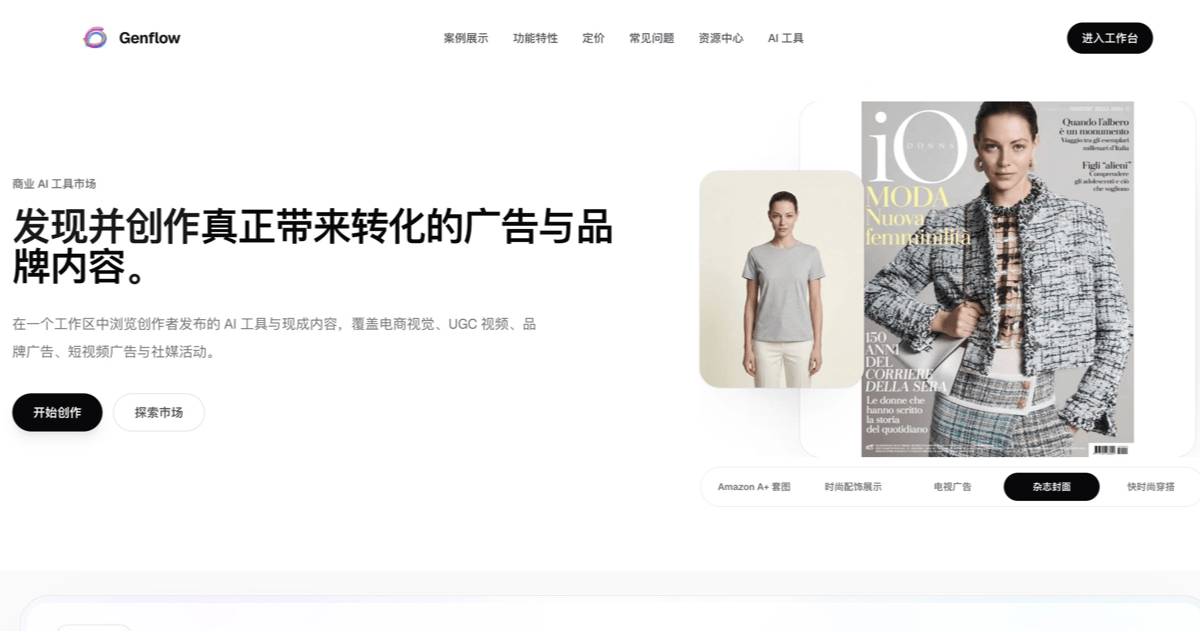
GenflowAI – 多模态AI创意工作空间GenflowAI是面向创作者、电商与营销团队的多模态AI创意工作空间,主打无代码自动化工作流。聚合 GPT、Gemini、Seedance 2.0等顶尖模型,单一画布内完成文本、图像、视频、音频的生...AI最新项目2周前0390
PlanningBench – 腾讯混元等联合开源规划能力评测与训练框架PlanningBench是由中国人民大学高瓴人工智能学院与腾讯混元联合开发的开源大模型规划能力评测与训练框架,核心目标是系统化评估和提升AI模型在多约束、多步骤决策任务中的全局规划能力。 其突破性在...AI最新项目2周前0450
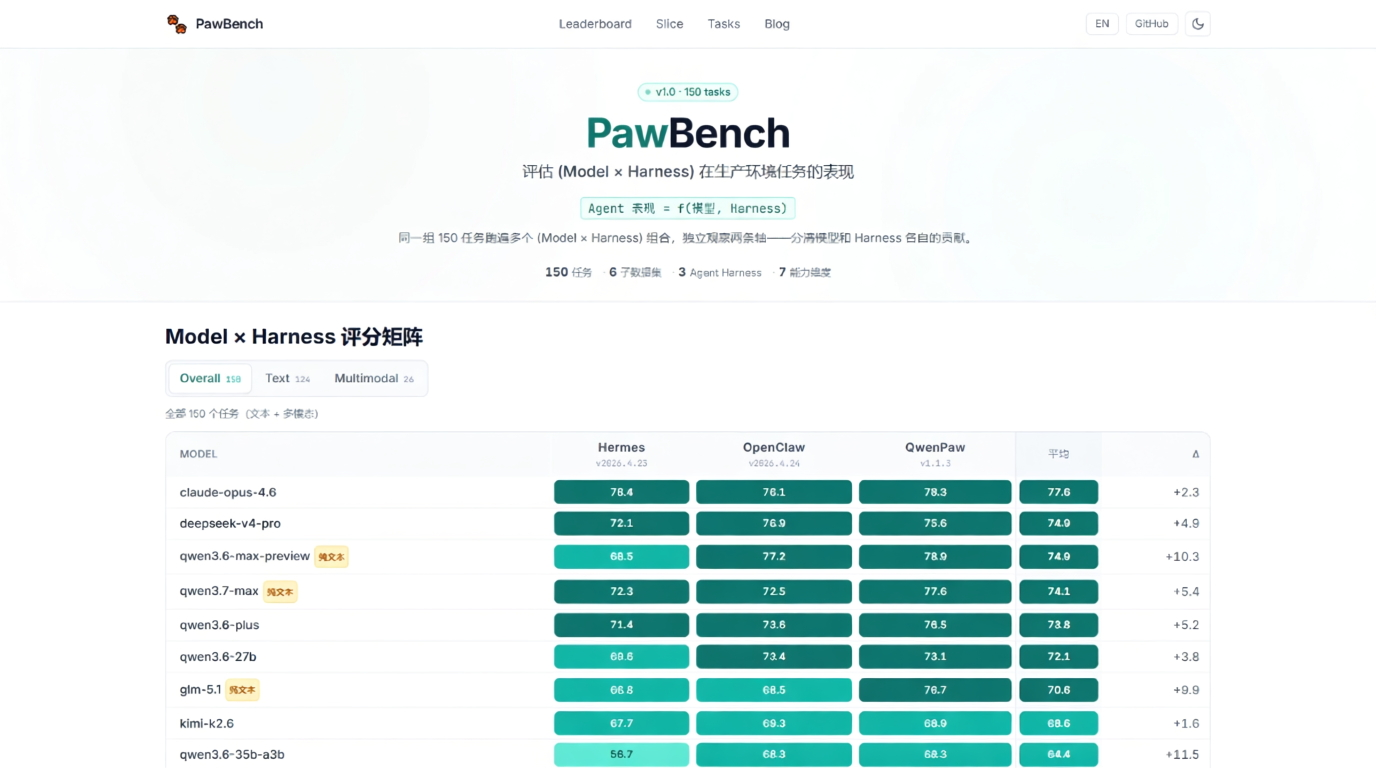
PawBench – 通义实验室推出的开源通用智能体评测基准PawBench是通义实验室于2026年6月推出的开源通用智能体评测基准,核心突破在于首次将底座模型、运行框架(Harness)与任务场景纳入同一交叉评测体系,而非仅对模型能力排名。 通过系统性拆解智...AI最新项目3周前0620