
IndexCache是什么?
IndexCache 是大模型稀疏注意力推理专属加速优化技术,专为解决稀疏注意力(如 DSA、MQA 稀疏变体)多层重复索引计算冗余问题设计。核心逻辑:缓存关键 Token 索引、跨层复用、砍掉无效算力消耗,不改动模型权重、不牺牲推理质量,低成本提升长文本推理速度、降低显存占用。
二、研发背景
- 稀疏注意力痛点:长上下文推理时,每层都需独立计算 Top-K 重要 Token 索引,相邻层索引重合度高达 70%-100%,大量算力空耗
- 传统优化局限:蒸馏、量化易损精度;张量并行部署成本高、适配门槛高;单纯 KV 缓存无法优化索引计算冗余
- 刚需场景倒逼:30B + 大模型、128K 超长上下文、高并发推理场景,延迟高、算力贵、吞吐量低亟需轻量优化方案
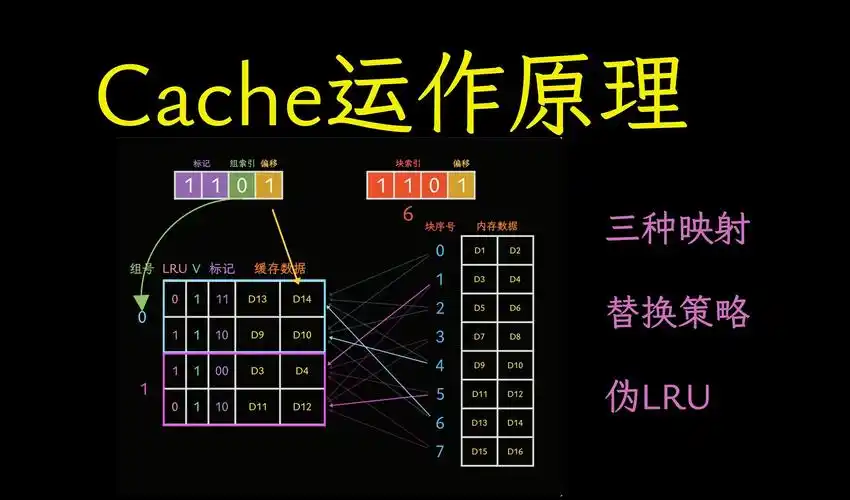
三、核心工作原理
1、核心前提
大模型 Transformer 相邻网络层,对输入文本的注意力权重分布高度相似,筛选出的 Top-K 关键 Token 索引几乎一致,无需每层重新精准计算
2、分层架构设计
将模型所有网络层分为两类,精准平衡精度与速度:
- Full 完整层:保留原生索引计算器,正常精准筛选 Top-K Token 索引,计算完成后全局缓存索引结果,负责兜底精度
- Shared 共享层:直接禁用原生索引计算器,跳过冗余算力运算,直接读取复用最近 Full 层缓存好的索引数据
3、动态缓存更新机制
默认按固定间隔穿插 Full 层(如每 4 层设 1 个 Full 层),实时刷新缓存索引;文本语义突变时自动快速更新,避免索引过时错位,兼顾复用效率与语义适配性
四、关键技术优势
- 极致降算力:直接移除约 75% 冗余索引计算,不压缩、不剪枝,无损基础推理逻辑
- 推理双加速:30B 实测模型,预填充速度提升 1.82 倍,解码生成速度提升 1.48 倍
- 精度几乎零损耗:仅极端超长乱序文本微小波动,常规对话、论文、代码场景完全无感
- 轻量易部署:无模型重构、无额外插件依赖,原生推理引擎即可接入,适配主流框架
- 适配超长上下文:128K/256K 长文本优势拉满,大幅降低显存频繁读写开销
五、适用场景与落地限制
✅ 优先适配场景
- 30B-70B 中大型稀疏注意力大模型
- 超长上下文生成:万字论文续写、长文档摘要、小说连载
- 高并发在线推理:AI 客服、批量内容生成、企业私有部署 API
❌ 适配局限
- 稠密注意力模型(GPT 基础版)无效,仅适配稀疏变体架构
- 极短文本(百字内)加速感知微弱,性价比不突出
- 频繁语义跳变碎文本,需调高 Full 层占比,加速幅度轻微下降
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...