
大模型编码器(Encoder) 是大语言模型(尤其是基于Transformer架构的模型)中的核心组件,它的角色可以比喻为人类的“感官与理解中枢”。
简单来说,它的作用是将人类可读的原始数据(文字、图片、声音)“翻译”并“压缩”成计算机能深度理解的高维语义向量。
以下从核心作用和工作原理两个维度为您详细拆解:
一、大模型编码器的核心作用
编码器的根本任务是“理解”。它不负责生成新内容,而是负责把输入内容“吃透”,提取出深层含义。
1. 语义向量化 (Semantic Embedding)
- 功能:将离散的符号(如单词“苹果”)转化为连续的数学向量(如一串浮点数
[0.23, -0.45, ..., 0.99])。 - 意义:在这个向量空间中,意思相近的词(如“猫”和“猫咪”)距离很近,意思相反的词(如“好”和“坏”)距离很远。这使得计算机可以通过计算数学距离来理解语义。
2. 上下文关联 (Contextualization) —— 最关键的作用
- 功能:解决一词多义问题。
- 例子:
- 句子 A:“我在打球。” → 编码器生成的“打”的向量,包含“运动”的语义。
- 句子 B:“我在打车。” → 编码器生成的“打”的向量,包含“乘坐/叫车”的语义。
- 机制:编码器会让每个词“看到”句子里的其他所有词,从而根据上下文动态调整自己的含义表示。
3. 长距离依赖捕捉
- 功能:理解句子开头和结尾的逻辑关系,即使它们相隔很远。
- 例子:“虽然今天下着暴雨,但是我还是去跑步了。”
- 编码器能捕捉到“虽然”和“但是”之间的转折逻辑,明白重点在“去跑步”,而不是“下暴雨”。
4. 多模态对齐 (在多模态模型中)
- 功能:将图片和文字映射到同一个语义空间。
- 例子:CLIP 模型的编码器可以将一张“猫的照片”和文字“一只可爱的猫”编码成非常相似的向量,从而实现“以图搜文”。
二、大模型编码器的工作原理
现代大模型编码器主要基于Transformer架构。其工作流程可以分为五个关键步骤:
第 1 步:分词与嵌入 (Tokenization & Embedding)
- 输入:原始文本(例如:“你好世界”)。
- 动作:
- 切分:将文本切成最小的单元(Token),如
["你", "好", "世", "界"]。 - 查表:每个 Token 都有一个固定的编号(ID)。模型通过查找“词嵌入表”,将 ID 转换为初始向量。
- 位置编码:因为 Transformer 是并行处理的,不知道顺序。所以会给每个向量加上一个位置向量,告诉模型“你”是第 1 个,“好”是第 2 个。
- 切分:将文本切成最小的单元(Token),如
- 输出:一组带有位置信息的初始向量序列。
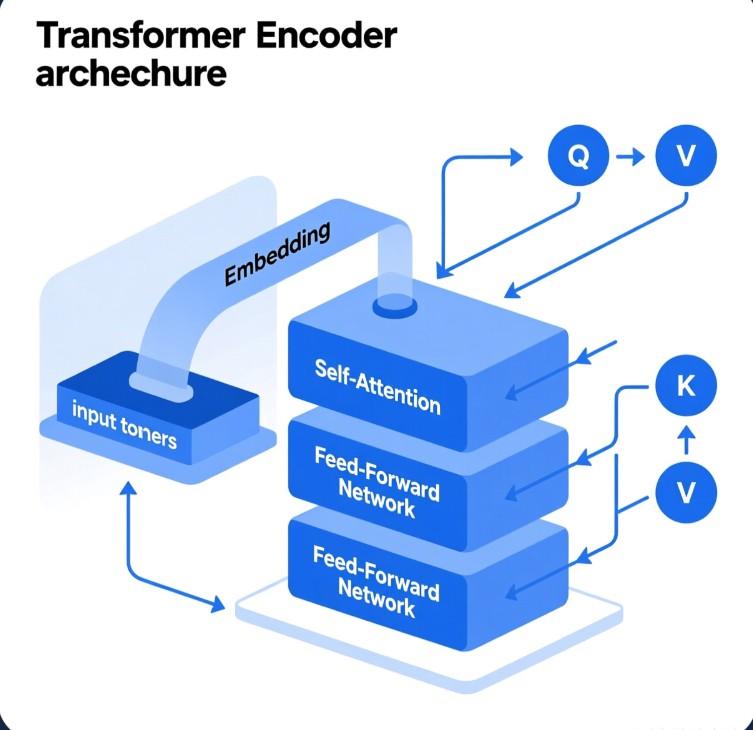
第 2 步:自注意力机制 (Self-Attention) —— 核心引擎
这是编码器最神奇的地方。它让序列中的每一个词都能“关注”到序列中的其他所有词。
- 三个关键向量:对于每个词,模型会计算三个向量:
- Query (Q):我想查询什么信息?
- Key (K):我拥有什么信息标签?
- Value (V):我的实际内容是什么?
- 计算过程:
- 用当前词的 Q 去和句中所有词的 K 做点积运算,计算相关性分数(注意力权重)。
- 比如:处理“银行”这个词时,如果句中有“钱”,相关性分数就高;如果句中有“河岸”,相关性分数也高。
- 将这些分数归一化(Softmax),变成概率分布。
- 用这些概率对所有的 V 进行加权求和。
- 用当前词的 Q 去和句中所有词的 K 做点积运算,计算相关性分数(注意力权重)。
- 结果:每个词的新向量都融合了全句的信息。原本孤立的词变成了“懂语境”的词。
第 3 步:前馈神经网络 (Feed-Forward Network, FFN)
- 作用:对自注意力层输出的信息进行进一步的非线性处理和特征提取。
- 比喻:如果说自注意力机制是“收集信息”,FFN 就是“消化思考”。它对每个位置的向量独立地进行复杂的数学变换,提取更抽象的特征。
第 4 步:残差连接与层归一化 (Residual Connection & Layer Norm)
- 残差连接:将输入直接加到输出上( Output=Input+Function(Input) )。
- 目的:防止网络太深导致梯度消失,让信息能无损地传递到深层。
- 层归一化:将向量的数值分布拉回到标准范围。
- 目的:加速训练收敛,保持模型稳定。
- 结构:通常一个编码器层包含:
[自注意力 + 残差 + 归一化] -> [FFN + 残差 + 归一化]。
第 5 步:堆叠与输出 (Stacking & Output)
- 堆叠:上述的编码器层会重复堆叠很多层(例如 BERT 有 12 层,大型模型可能有几十层)。
- 浅层关注语法、词性。
- 深层关注语义、逻辑、情感。
- 最终输出:经过所有层处理后,输出一组最终的上下文向量序列。这组向量就是机器对这段文字的“终极理解”。
三、流程示例
假设输入句子:“我爱吃苹果”
- 输入层:
[我, 爱, 吃, 苹果]→ 初始向量。 - 自注意力层:
- “苹果”这个词发现它与“吃”的相关性很高,与“爱”也有关系。
- “苹果”的向量更新:融合了“食物”的语义(因为旁边是“吃”),排除了“科技公司”的语义。
- FFN 层:进一步提炼“水果”、“美味”等特征。
- 多层堆叠:经过 12 层处理后,“苹果”的向量已经极其丰富,包含了它在整个句子中的完整逻辑地位。
- 输出:得到 4 个高维向量,分别代表这句话中每个词在特定语境下的含义。
四、编码器在不同模型架构中的差异
表格
| 模型类型 | 编码器的工作方式 | 典型代表 |
|---|---|---|
| Encoder-Only | 双向可见。编码时可以看到句子的过去和未来。理解力最强,但不能直接生成文本。 | BERT, RoBERTa (用于搜索、分类) |
| Encoder-Decoder | 双向可见。专门负责理解源句子,将理解结果传递给解码器去生成目标句子。 | T5, BART (用于翻译、摘要) |
| Decoder-Only | 单向可见(掩码)。严格来说没有独立的编码器模块。输入嵌入后直接进入 Decoder 层,利用“已看到的过去”来理解上下文并预测未来。 | GPT-4, Llama 3 (用于聊天、写作) |
小编简单概括一下
大模型编码器的工作原理就是:
通过分词嵌入建立基础,利用自注意力机制实现全局上下文关联,经过多层神经网络的深度提炼,最终将人类语言转化为机器可计算的高密度语义向量。它是大模型具备“理解能力”的物理基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...