
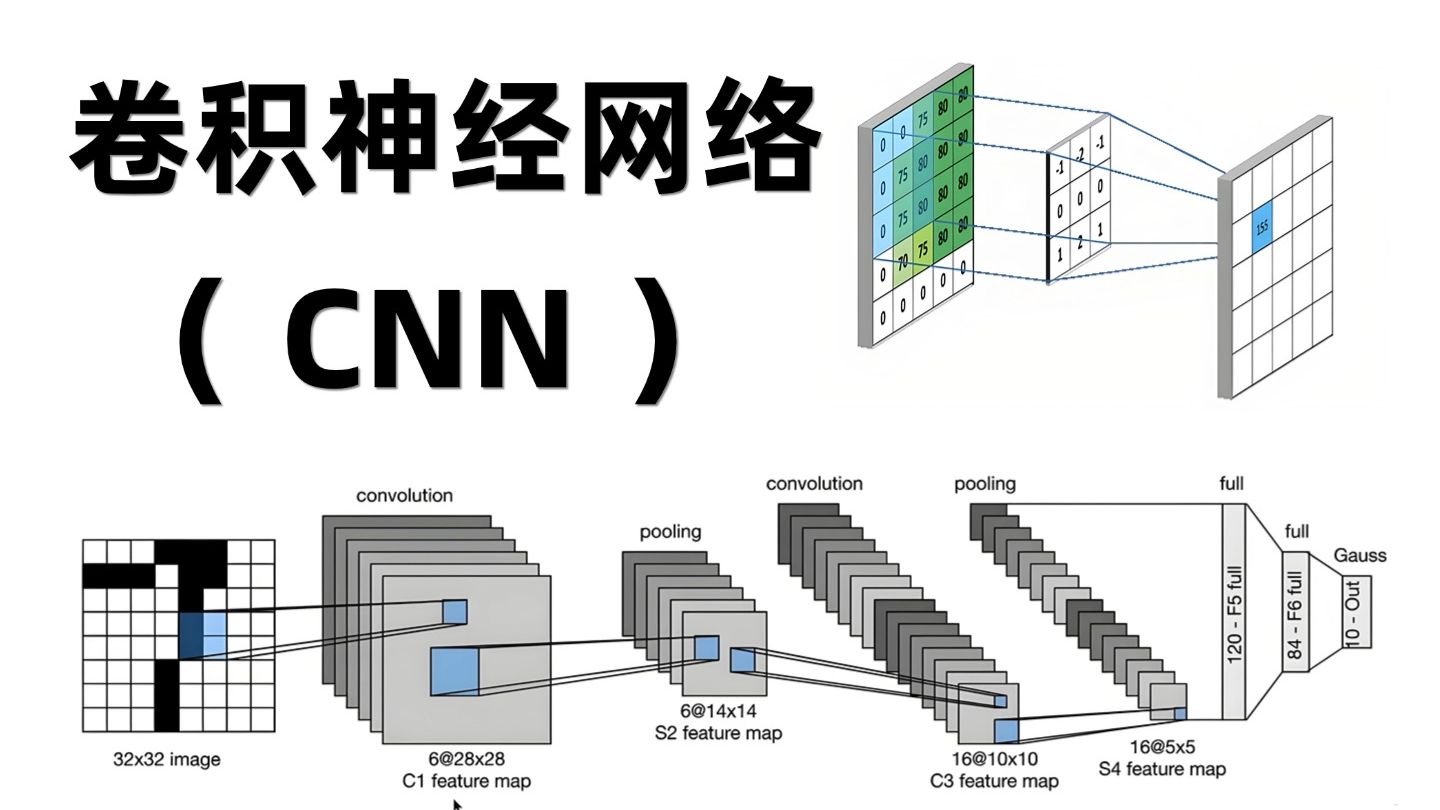
CNN(Convolutional Neural Network,卷积神经网络) 是一种专门用于处理具有网格结构数据(如图像、视频、音频频谱图)的深度学习模型。它是计算机视觉领域的基石,广泛应用于图像分类、目标检测、人脸识别、医学影像分析等任务。
与传统的全连接神经网络(FCN)不同,CNN 通过局部连接和权值共享机制,极大地减少了参数量,并能够有效提取数据的空间特征(如边缘、纹理、形状)。
一、CNN的核心原理
CNN 的设计灵感来源于生物视觉皮层。其核心思想是:图像的特征具有局部性和平移不变性。
- 局部性:图像中的某个像素只与其周围的像素密切相关(例如,识别一只猫的眼睛不需要看整张图的所有像素,只需关注眼睛周围的区域)。
- 平移不变性:无论猫在图片的左上角还是右下角,它依然是猫。CNN通过共享卷积核参数来实现这一特性。
三大关键机制:
- 局部感知(Local Connectivity):神经元只连接输入数据的一小部分区域(感受野),而不是全部。
- 权值共享(Parameter Sharing):同一个卷积核(滤波器)在整张图像上滑动,使用相同的权重去检测特征。这意味着无论特征出现在图像的哪个位置,都能被同一个卷积核检测到。
- 下采样(Downsampling):通过池化操作降低数据维度,保留主要特征,减少计算量并防止过拟合。
二、CNN的典型网络结构
一个标准的CNN通常由以下几种层交替堆叠而成,形成一个从“低级特征”到“高级语义”的层级结构:
1. 卷积层 (Convolutional Layer) —— 特征提取器
这是 CNN 的核心。
- 操作:使用一个或多个卷积核(Filter/Kernel)在输入图像上滑动(卷积运算)。
- 过程:卷积核与输入图像的局部区域进行点积运算,生成一个特征图(Feature Map)。
- 作用:
- 浅层卷积核通常提取低级特征(如边缘、颜色、角点)。
- 深层卷积核提取高级特征(如眼睛、车轮、复杂的纹理)。
- 关键参数:
- 卷积核大小(如 3×3, 5×5)。
- 步长 (Stride):卷积核滑动的步幅。
- 填充 (Padding):在图像周围补零,以控制输出尺寸或保留边缘信息。
2. 激活层 (Activation Layer) —— 引入非线性
通常紧跟在卷积层之后。
- 常用函数:ReLU (Rectified Linear Unit, f(x)=max(0,x) )。
- 作用:将负值置为 0,保留正值。引入非线性因素,使网络能够拟合复杂的非线性关系。如果没有激活层,多层卷积等同于单层线性变换,无法解决复杂问题。
3. 池化层 (Pooling Layer) —— 降维与抗噪
也称为下采样层。
- 操作:在特征图的局部区域内取最大值或平均值。
- 类型:
- 最大池化 (Max Pooling):取区域内的最大值(最常用,能保留最显著的特征)。
- 平均池化 (Average Pooling):取区域内的平均值。
- 作用:
- 减小特征图尺寸,降低计算量。
- 扩大感受野。
- 提供一定程度的平移不变性(即使物体稍微移动,池化后的结果可能不变)。
- 防止过拟合。
4. 全连接层 (Fully Connected Layer, FC) —— 分类器
通常位于网络的末端。
- 操作:将前面所有层提取到的二维/三维特征图“展平”(Flatten)成一维向量,然后通过传统的全连接神经网络进行处理。
- 作用:整合所有局部特征,进行最终的分类或回归预测(例如:输出这张图是“猫”的概率是 98%)。
5. 输出层 (Output Layer)
- 根据任务不同,使用不同的激活函数:
- 分类任务:Softmax(输出各类别的概率分布)。
- 回归任务:Linear(直接输出数值)。
三、CNN的工作流程示例(以识别猫为例)
假设输入一张猫的图片:
- 输入层:接收原始像素矩阵(例如 224x224x3)。
- 卷积块 1:
- 多个 3×3 卷积核扫描图像 -> 提取边缘、颜色斑点。
- ReLU 激活 -> 去除负值。
- 最大池化 -> 尺寸减半,保留显著边缘。
- 卷积块 2:
- 在上一轮特征图上继续卷积 -> 组合边缘形成简单形状(如圆形、线条)。
- ReLU + 池化。
- 卷积块 3…N:
- 深层网络将简单形状组合成复杂部件(如耳朵、眼睛、胡须)。
- 全连接层:
- 将所有特征拉平,综合判断:“有耳朵 + 有胡须 + 圆脸 = 猫”。
- 输出:
- Softmax 输出:[猫: 0.95, 狗: 0.03, 鸟: 0.02]。
四、经典CNN架构演变
为了让你更好地理解结构的变化,以下是几个里程碑式的模型:
| 模型 | 年份 | 特点 | 意义 |
| :— | :— | :— | 😐
| LeNet-5 | 1998 | 7 层结构,用于手写数字识别 | CNN 的鼻祖,证明了卷积的有效性 |
| AlexNet | 2012 | 8 层,引入 ReLU、Dropout、GPU 加速 | 引爆深度学习热潮,在 ImageNet 大赛夺冠 |
| VGGNet | 2014 | 使用连续的 3×3 小卷积核,结构规整 | 证明了“深度”比“宽度”更重要 |
| GoogLeNet | 2014 | 引入 Inception 模块,多尺度卷积并行 | 在不增加参数量的情况下增加深度和宽度 |
| ResNet | 2015 | 引入残差连接 (Residual Connection) | 解决了深层网络梯度消失问题,让训练上千层的网络成为可能 |
| :— | :— | :— | 😐
| LeNet-5 | 1998 | 7 层结构,用于手写数字识别 | CNN 的鼻祖,证明了卷积的有效性 |
| AlexNet | 2012 | 8 层,引入 ReLU、Dropout、GPU 加速 | 引爆深度学习热潮,在 ImageNet 大赛夺冠 |
| VGGNet | 2014 | 使用连续的 3×3 小卷积核,结构规整 | 证明了“深度”比“宽度”更重要 |
| GoogLeNet | 2014 | 引入 Inception 模块,多尺度卷积并行 | 在不增加参数量的情况下增加深度和宽度 |
| ResNet | 2015 | 引入残差连接 (Residual Connection) | 解决了深层网络梯度消失问题,让训练上千层的网络成为可能 |
五、概括一下
CNN(卷积神经网络) 是通过模拟生物视觉机制,利用卷积提取局部特征、池化降低维度、全连接进行分类的强大工具。
- 核心优势:参数少(权值共享)、特征提取能力强(自动学习)、对平移和形变有鲁棒性。
- 适用场景:几乎所有涉及图像、视频处理的 AI 任务,甚至扩展到自然语言处理(文本分类)和时间序列分析。
虽然现在出现了 Vision Transformer (ViT) 等新架构,但 CNN 凭借其高效性和成熟的生态,依然是工业界最主流的视觉模型基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...