
过拟合(Overfitting),也叫“过适”,是机器学习中最常见的问题之一。
简单来说,过拟合就是模型“死记硬背”了训练数据,却没能学会其中的规律。这就像一个学生为了应付考试,把练习题的答案全部背了下来,但并没有理解解题思路。一旦考试题目稍微换个问法(遇到新数据),他就完全不会做了。
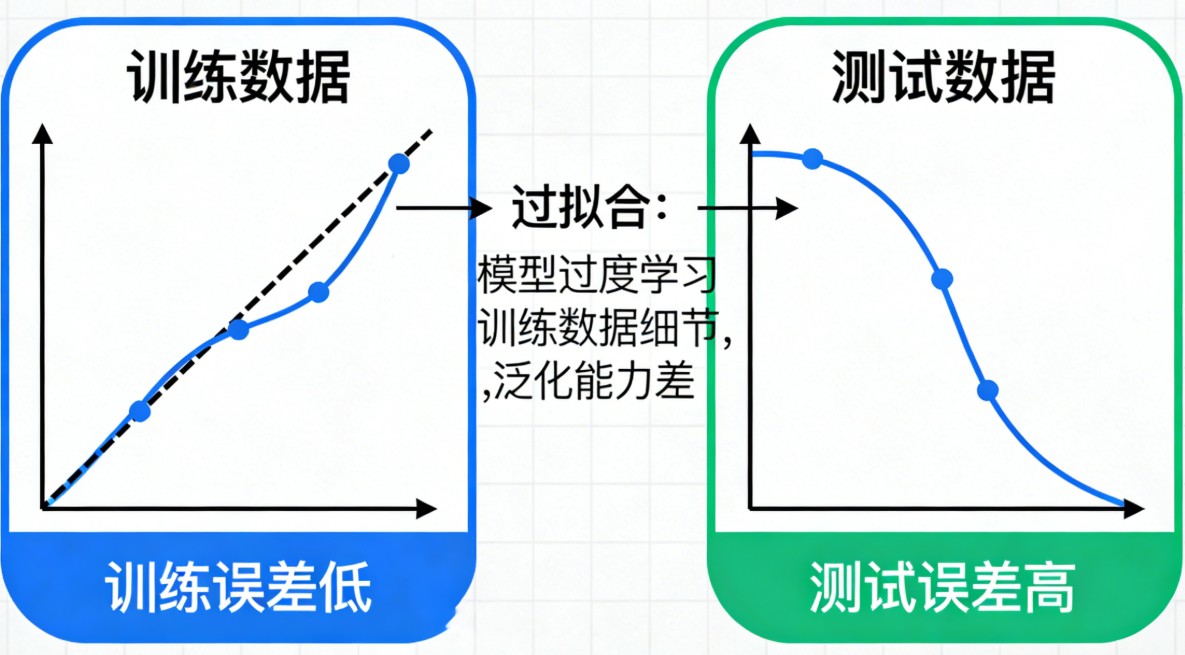
🧐 核心表现
过拟合的模型通常表现出两个鲜明的特征:
- 在训练数据上表现极好:误差非常低,甚至能达到100%的准确率。
- 在未见过的数据(测试/验证集)上表现很差:泛化能力弱,预测结果一塌糊涂。
🎯 为什么会发生过拟合?
过拟合的本质是模型的复杂度超出了数据本身包含的信息量,导致它捕捉到了数据中的“噪声”和偶然规律,而不是普适的真实规律。主要原因有:
- 模型过于复杂:模型的参数太多、结构太复杂(如层数过深的神经网络、阶数过高的多项式),学习能力“过强”,以至于把训练数据中的每一个微小波动和噪声都当成了重要特征学了进去。
- 训练数据量不足:当训练数据太少时,模型无法从中学习到全面的规律,只能“记住”有限的样本,导致以偏概全。
- 训练时间过长:在训练过程中,模型会先学习数据的主要规律,然后开始学习噪声。如果训练时间过长,就会导致过拟合,这在神经网络中也被称为“过度训练”(overtraining)。
🛠️ 如何解决过拟合?
解决过拟合的核心思路是降低模型复杂度或增加有效数据,以提升模型的泛化能力。常见的方法包括:
- 增加训练数据:提供更多样化的数据,让模型有机会学习到更普遍的规律,而不是局限于少数样本。
- 数据增强 (Data Augmentation):通过对现有数据进行变换(如图像的旋转、裁剪)来“创造”更多训练样本。
- 正则化 (Regularization):在模型的损失函数中加入一个惩罚项(如L1或L2正则化),限制模型参数的大小,从而降低模型的复杂度,防止它过度拟合。
- 早停法 (Early Stopping):在训练过程中监控模型在验证集上的表现。一旦发现验证集的性能开始下降,就立即停止训练,防止模型开始学习噪声。
- 降低模型复杂度:减少神经网络的层数或节点数,或者降低决策树的深度。
- Dropout:在神经网络训练时,随机“关闭”一部分神经元,强迫网络不过度依赖某些特定路径,从而提升泛化能力。
- 交叉验证 (Cross-Validation):通过将数据分成多份进行多次训练和验证,更准确地评估模型的泛化性能,帮助选择最优模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...