
生成式概率模型(Generative Probabilistic Model)是人工智能领域中一类通过学习数据内在分布规律,从而能够生成与真实数据相似的新样本的模型。
简单来说,它就像一个“数据模仿大师”。它不只是简单地复制数据,而是先深入研究大量真实数据(比如成千上万张人脸照片),总结出这些数据背后的“生成套路”和统计规律,然后利用这些规律,凭空“创造”出全新的、但看起来非常真实的数据。
核心原理:学习“数据是如何被制造出来的”
生成式概率模型的核心在于对数据的联合概率分布 P(X, Y) 进行建模。这里的 X 代表数据本身(如图像像素),Y 代表数据的标签(如“猫”或“狗”)。
- 学习过程:模型通过分析海量数据,学习“猫”这个类别的数据通常长什么样(P(X|Y=猫)),以及“狗”的数据又是什么样(P(X|Y=狗))。它不仅记住了特征,更理解了这些特征组合在一起的概率。
- 生成过程:当需要生成一张新的“猫”的图片时,模型会根据它学到的关于“猫”的概率分布,随机采样一组特征,然后“合成”出一张全新的、符合“猫”特征的图像。
与判别式模型的区别
为了更好地理解,我们可以将它与另一类主流模型——判别式模型(Discriminative Model)进行对比。
表格
| 维度 | 生成式模型 (Generative Model) | 判别式模型 (Discriminative Model) |
|---|---|---|
| 学习目标 | 学习数据的联合概率分布 P(X, Y),即“猫长什么样”和“狗长什么样”。 | 学习**条件概率分布 P(Y |
| 核心思想 | 学习每类数据的生成机制,理解数据本身。 | 寻找不同类别之间的最优分类边界,区分差异。 |
| 能力 | 既能分类,更能创造新数据(如AI绘画、写文章)。 | 擅长分类和预测,但无法生成新数据。 |
| 类比 | 一位画家,他学过无数猫的画法,能自己画出一只从未见过的猫。 | 一位鉴定师,他能准确分辨出眼前的动物是猫还是狗,但不会画画。 |
主要类型与应用
生成式概率模型家族庞大,涵盖了从经典统计模型到现代深度学习的多种架构。
主要类型
- 经典模型:如朴素贝叶斯(Naive Bayes)和隐马尔可夫模型(HMM)。它们是基于概率图模型的经典代表,常用于文本分类和语音识别。
- 现代深度学习模型:
- 生成对抗网络(GANs):由一个“生成器”和一个“判别器”相互博弈、共同进步,能生成极其逼真的图像。
- 变分自编码器(VAEs):通过将数据编码到一个压缩的“潜在空间”,再从中解码生成新数据,输出通常更平滑、稳定。
- Transformer模型:以GPT系列为代表,通过学习海量文本的序列规律,能够生成连贯、富有逻辑的文章和代码。
典型应用
- AI内容创作:AI绘画(如DALL-E)、文本生成(如ChatGPT)、音乐合成。
- 数据增强:生成合成数据,用于训练其他AI模型,解决真实数据稀缺的问题。
- 科学发现:在药物研发中,生成具有特定属性的新分子结构。
- 图像处理:图像修复、超分辨率重建、AI换脸。
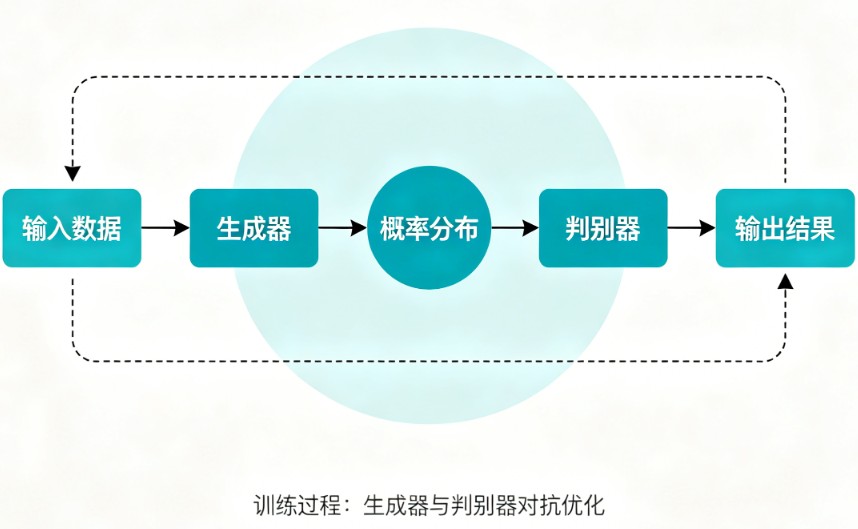
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...