
BERT(Bidirectional Encoder Representations from Transformers)是由Google于 2018 年提出的一种预训练语言模型。它的出现被视为自然语言处理(NLP)领域的里程碑,开启了“预训练-微调”范式的黄金时代,对后续的大语言模型发展产生了深远影响。
简单来说,BERT的核心创新在于其深度双向的架构,这使它能够同时利用一个词左右两侧的上下文信息来理解其含义,从而实现了比之前单向模型更深刻的语言理解。
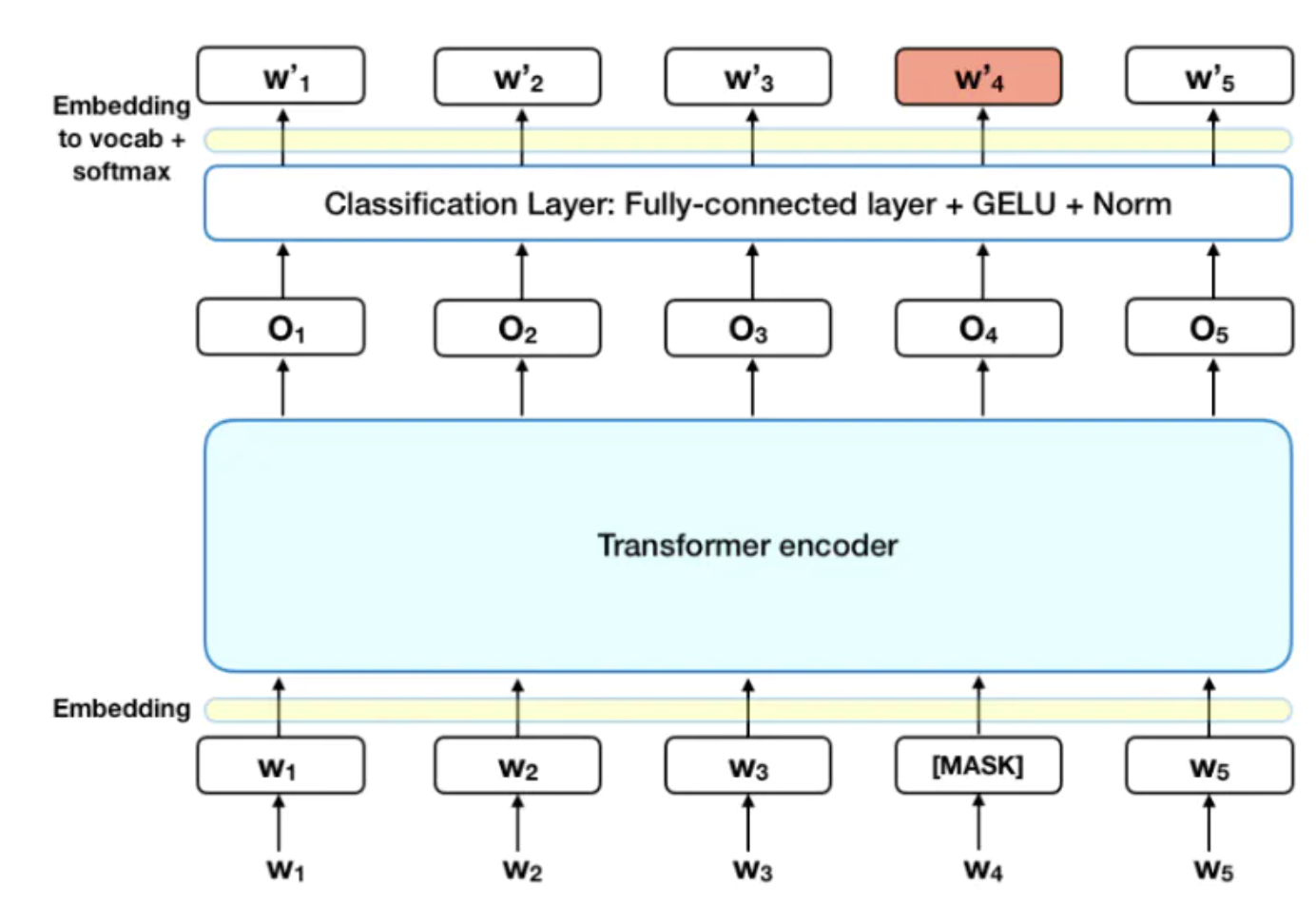
核心原理:真正的“双向”理解
这种双向理解能力主要通过两个自监督的预训练任务来实现:
- 掩码语言模型 (Masked Language Model, MLM)
这是BERT最核心的创新。在训练时,模型会随机遮蔽(Mask)输入句子中 15% 的词,然后让模型根据剩下的上下文去预测被遮蔽的词是什么。- 例子:输入“我 [MASK] 自然语言处理。”,模型需要预测出
[MASK]位置应该是“爱”。这个过程迫使模型学会利用双向信息进行推理。
- 例子:输入“我 [MASK] 自然语言处理。”,模型需要预测出
- 下一句预测 (Next Sentence Prediction, NSP)
为了让模型理解句子之间的关系,BERT还会接收两个句子(A 和 B)作为输入,并判断句子 B 是否是句子 A 的真实下一句。这个任务对问答、自然语言推理等需要理解句间关系的任务至关重要。
模型架构与输入
BERT的架构完全基于Transformer的编码器(Encoder)部分堆叠而成。它的输入由三种嵌入(Embedding)向量相加构成:
- 词嵌入 (Token Embedding):词或子词本身的向量表示。
- 段嵌入 (Segment Embedding):用于区分输入中的两个句子(例如句子 A 标记为 0,句子 B 标记为 1)。
- 位置嵌入 (Position Embedding):提供词在序列中的位置信息,因为 Transformer 本身不具备处理序列顺序的能力。
主要版本对比
BERT 主要发布了两个版本,它们在模型规模和性能上有所不同:
表格
| 模型版本 | Transformer层数 | 隐藏层维度 | 注意力头数 | 参数量 |
|---|---|---|---|---|
| BERT-Base | 12层 | 768维 | 12头 | 约1.1亿 |
| BERT-Large | 24层 | 1024维 | 16头 | 约3.4亿 |
应用与影响
BERT 采用“预训练-微调”的范式。先在海量无标签文本(如BooksCorpus和英文维基百科)上进行预训练,学习通用的语言知识。然后,针对具体的下游任务(如文本分类、问答、情感分析),只需在预训练模型的基础上进行简单的微调,就能取得当时最先进的性能。
- 主要应用:文本分类、问答系统、情感分析、命名实体识别等。
- 工业界应用:2019年,谷歌搜索开始应用BERT来处理查询,显著提升了搜索结果的准确性,并迅速扩展到全球70多种语言。
模型变体与演进
BERT的成功催生了大量优秀的变体模型,它们在不同方向上进行了优化:
- 性能优化:RoBERTa 通过移除 NSP 任务、使用更大批次训练等方式,进一步提升了模型性能。
- 轻量化:DistilBERT 和 ALBERT 通过知识蒸馏、参数共享等技术,在保持大部分性能的同时,显著减小了模型体积,提升了推理速度。
- 中文优化:BERT-wwm 等模型采用了全词掩码(Whole Word Masking)技术,更好地适应了中文等语言的特性。
如今,BERT及其变体已成为NLP领域的基础组件,通过Hugging Face等开源库,开发者可以非常方便地使用这些强大的预训练模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...