
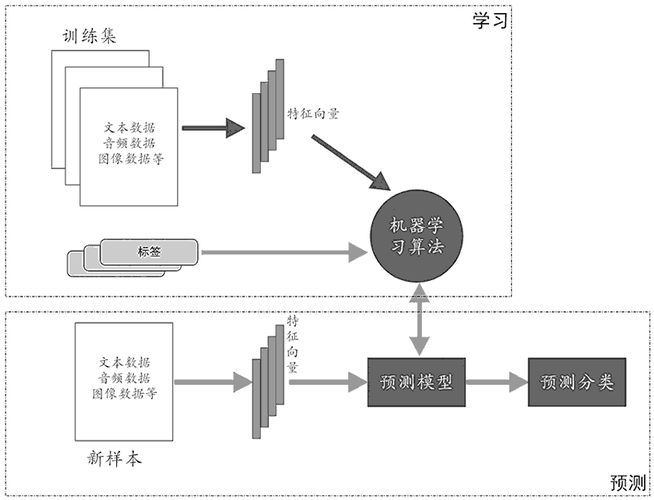
监督学习(Supervised Learning)是机器学习中最基础、应用最广泛的一种方法。你可以把它理解为“有老师指导的学习”。
它的核心逻辑是:我们给计算机提供大量的“题目”(输入数据)和对应的“标准答案”(标签),让算法通过分析这些数据,自己总结出规律。当它学成之后,面对新的“题目”时,就能自己推导出“答案”。
核心概念:什么是“监督”?
在监督学习中,“监督”指的是训练数据中包含了标签(Label)。
- 输入(特征):比如一张图片的像素数据。
- 输出(标签):比如这张图片是“猫”还是“狗”。
算法通过不断对比自己的预测结果和标准答案,计算误差(损失),然后调整内部参数,直到误差最小化。这就像学生做题,做完后马上对答案,错了就纠正,直到下次考试(测试集)能拿高分。
两大核心任务类型
监督学习主要解决两类问题:分类和回归。
表格
| 任务类型 | 目标 | 输出结果 | 典型应用场景 |
|---|---|---|---|
| 分类 (Classification) | 预测数据属于哪个类别 | 离散的标签 (如:是/否,红/绿/蓝) | 垃圾邮件识别、人脸识别、疾病诊断 |
| 回归 (Regression) | 预测一个具体的数值 | 连续的数值 (如:价格、温度、身高) | 房价预测、股票趋势分析、销量预测 |
常见的监督学习算法
针对上述两类任务,科学家们发明了多种算法,以下是几种最经典的:
1. 线性回归 (Linear Regression)
- 用途:主要用于回归任务。
- 原理:试图在数据点之间画一条直线(或超平面),来拟合输入和输出之间的关系。比如根据房屋面积预测房价。
2. 逻辑回归 (Logistic Regression)
- 用途:虽然名字里有“回归”,但它主要用于分类任务(特别是二分类)。
- 原理:通过Sigmoid函数将线性回归的输出压缩到0到1之间,用来预测某件事发生的概率。例如,预测一封邮件是垃圾邮件的概率是否超过50%。
3. 决策树 (Decision Tree)
- 用途:分类和回归均可。
- 原理:模拟人类做决策的过程,通过一系列“如果…那么…”的规则对数据进行拆分。它的结构像一棵倒置的树,具有很好的可解释性。
4. 支持向量机 (SVM)
- 用途:主要用于分类。
- 原理:在高维空间中找到一个“超平面”,将不同类别的数据点尽可能宽地分隔开。它在处理小样本、高维数据时表现非常出色。
5. K-近邻算法 (KNN)
- 用途:分类和回归。
- 原理:“近朱者赤,近墨者黑”。看一个新数据点周围最近的K个邻居是谁,如果大多数邻居是“猫”,那它大概率也是“猫”。
6. 集成学习 (Ensemble Learning)
- 代表算法:随机森林 (Random Forest)。
- 原理:“三个臭皮匠,顶个诸葛亮”。通过构建多个决策树(弱学习器),将它们的预测结果汇总(投票或平均),从而获得比单个模型更准确、更稳定的结果。
监督学习的工作流程
一个完整的监督学习项目通常包含以下步骤:
- 数据收集与准备:收集带有标签的数据,并进行清洗、去重和标准化。
- 数据集划分:将数据分为训练集(用来学习)、验证集(用来调参)和测试集(用来考试)。
- 模型选择与训练:选择合适的算法(如SVM或随机森林),让模型在训练集上进行学习,不断调整权重以最小化误差(损失函数)。
- 评估与优化:使用测试集评估模型表现。
- 分类问题常看:准确率、精确率、召回率。
- 回归问题常看:均方误差 (MSE)。
- 部署与预测:模型训练好后,就可以部署到实际应用中,对新数据进行预测。
需要注意的问题
在训练过程中,你可能会遇到两个常见的挑战:
解决这些问题的关键在于平衡偏差 (Bias) 和方差 (Variance),这也是监督学习中一个核心的权衡点。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...