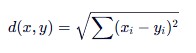

K-Means(K-均值)算法是无监督学习中最经典、最基础的聚类算法。它的目标非常直观:在没有标签的数据中,自动将相似的数据点归为一类。 简单来说,它的核心思想就是“物以类聚”——让同一个簇内的数据点尽可能紧密地聚集在一起,而不同簇之间尽可能分开。 
核心原理:寻找“重心”
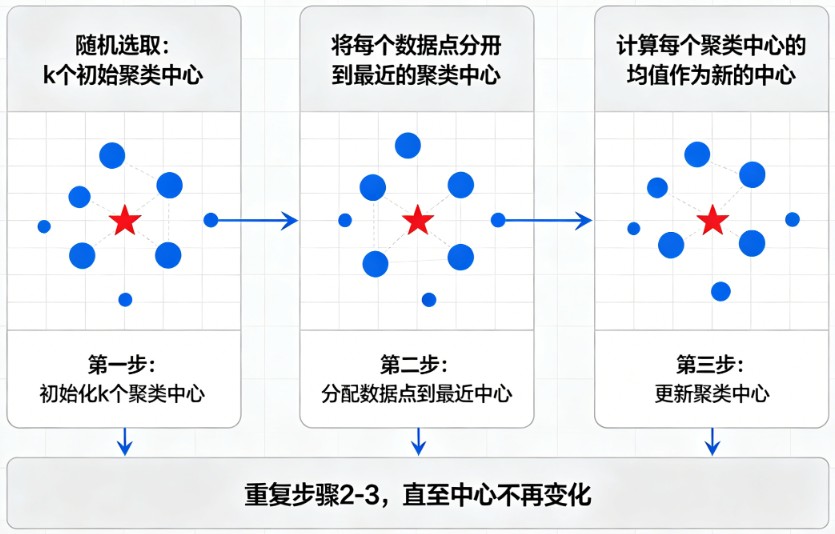
K-Means 的工作逻辑类似于“重心迁移”。想象你在地上撒了一把弹珠,你想把它们分成几堆。K-Means 的做法是:
- 先随机定几个“中心点”。
- 把每个弹珠分给最近的中心点。
- 分完后,计算每一堆弹珠的平均位置,把中心点移到这个新位置。
- 重复上述过程,直到中心点不再移动。
在这个过程中,算法试图最小化误差平方和(SSE),也就是让所有数据点到其所属簇中心的距离之和最小。
算法执行的 4 个标准步骤
K-Means 的算法流程非常规范,通常被称为“初始化→分配→更新→收敛”的循环:
表格
| 步骤 | 名称 | 详细操作 |
|---|---|---|
| Step 1 | 初始化 | 首先你需要指定一个数字 K(代表你想把数据分成几类)。然后,算法会随机从数据集中选择 K 个点作为初始的“簇中心”(Centroids)。 |
| Step 2 | 分配 | 计算每个数据点到这 K 个中心的距离(通常用欧氏距离)。把每个点分配给离它最近的那个中心。此时,数据就被分成了 K 个临时的簇。 |
| Step 3 | 更新 | 针对每一个簇,计算该簇内所有点的平均值(均值向量)。将这个平均值作为新的簇中心。 |
| Step 4 | 迭代/收敛 | 重复 Step 2 和 Step 3。直到簇中心的位置不再发生明显变化(或者变化小于某个阈值),或者达到了预设的最大迭代次数,算法停止。 |
关键要素详解
为了更深入理解,你需要掌握以下三个关键概念:
1. 距离的度量
K-Means 判断“相似”的标准通常是距离。最常用的是欧氏距离(Euclidean Distance),也就是两点之间的直线距离。
- 公式概念:
- 这意味着 K-Means 倾向于发现球状或凸形的簇,对于长条形或不规则形状的簇效果可能不佳。
2. K 值的选择(肘部法则)
K-Means 最大的痛点是你必须预先指定 K 值。选多少个合适呢?最常用的方法是肘部法则(Elbow Method):
- 尝试不同的 K 值(如 1, 2, 3…10)。
- 计算每个 K 值对应的 SSE(簇内误差平方和)。
- 画出折线图。随着 K 增加,SSE 会减小。但当 K 超过某个“最佳点”后,SSE 下降的幅度会突然变缓,形成一个像手肘一样的拐点。这个“肘部”对应的 K 值通常就是最优解。
3. 初始中心的选择(K-Means++)
原始的 K-Means 是随机选初始中心,这可能导致陷入“局部最优”(结果不是最好的)。
- 改进方案:现在常用的 K-Means++ 算法优化了这一步。它让初始中心点之间的距离尽可能远,从而大大提高了收敛速度和结果的准确性。
概括与局限
优点:
- 简单高效:原理易懂,计算速度快,适合处理大数据集。
- 可解释性强:结果直观,容易向业务方解释。
局限:
- 必须指定 K 值:很多时候我们并不知道数据里到底有几类。
- 对异常值敏感:因为它是取“平均值”,一个极端的异常值可能会把簇中心拉偏。
- 只能处理数值型数据:无法直接处理类别型数据(如“男/女”),需要先进行编码。
如果你需要处理的数据是数值型的,且大致呈团状分布,K-Means通常是你的首选算法。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...