
强化学习(Reinforcement Learning,简称 RL)是机器学习的三大支柱之一(另外两个是监督学习和无监督学习)。
如果说监督学习是“有老师教”,无监督学习是“自学”,那么强化学习就是“通过试错来学习”,就像训练宠物或小孩子学走路一样。它不依赖现成的数据集,而是让智能体(Agent)在环境(Environment)中不断尝试,根据获得的奖励或惩罚来调整策略,最终学会如何做出最优决策。
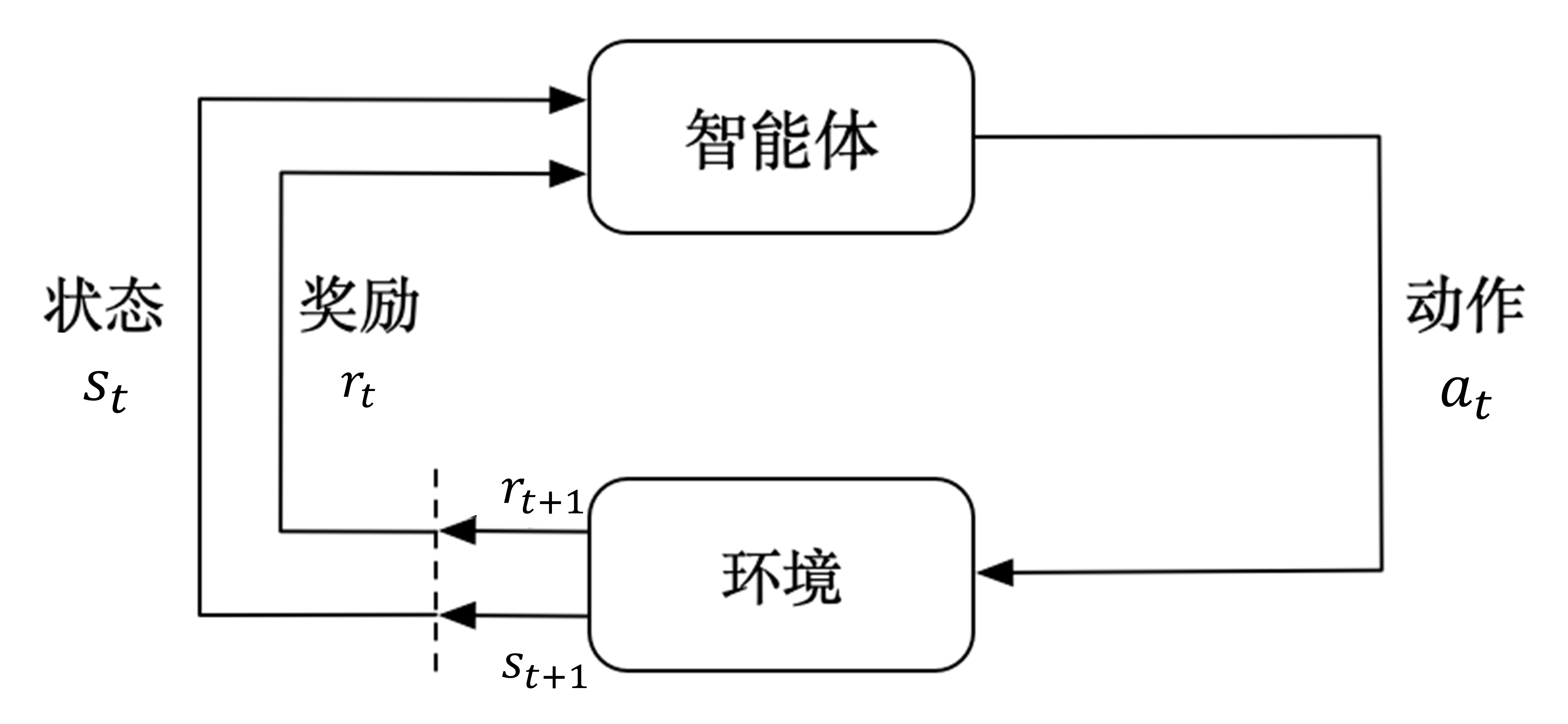
核心概念:RL 的“五要素”
强化学习的故事通常由以下五个角色构成:
表格
| 要素 | 名称 | 解释 | 类比(以训练小狗为例) |
|---|---|---|---|
| Agent | 智能体 | 学习的主体,负责做决策。 | 小狗 |
| Environment | 环境 | 智能体所处的外部世界。 | 房间/训练场 |
| State | 状态 | 智能体在某一时刻对环境的观察。 | 小狗看到主人手里拿着球 |
| Action | 动作 | 智能体在特定状态下采取的行为。 | 小狗坐下、握手或叫唤 |
| Reward | 奖励 | 环境对动作的反馈(正反馈或负反馈)。 | 给零食(正奖励)或 批评(负奖励) |
| Policy | 策略 | 智能体根据状态选择动作的规则(大脑中的决策逻辑)。 | 小狗学会“看到球就要坐下”的规矩 |
运作机制:试错与延迟满足
强化学习的核心逻辑是一个循环:
- 观察:智能体观察当前的状态 St 。
- 行动:根据策略,智能体选择一个动作 At 。
- 反馈:环境接收动作,给予一个奖励 Rt+1 ,并进入下一个状态 St+1 。
- 目标:智能体的目标不是获得眼前的奖励,而是最大化长期的累积奖励。
关键难点:
- 探索与利用:是尝试新的动作看看有没有更好的奖励(探索),还是坚持已知的能拿高分的动作(利用)?
- 信用分配:如果最后赢了,是哪一步棋下得好?如果输了,是哪一步走错了?(比如围棋,最后赢了,但关键可能在于第50步的布局)。
经典案例:从游戏到现实
强化学习在需要序列决策的领域表现最强:
- 游戏 AI(里程碑):
- AlphaGo:通过强化学习自我对弈,击败了人类围棋冠军李世石。它学会了人类从未下出的“神之一手”。
- Atari 游戏:DeepMind 的 DQN 算法直接看屏幕像素,学会了玩几十种雅达利游戏,甚至超过了人类高手。
- 机器人控制:让机器人学会走路、翻跟头、抓取物体,而不需要工程师写死每一个关节的运动轨迹。
- 大语言模型:ChatGPT 之所以说话好听、符合人类价值观,是因为在训练最后阶段使用了基于人类反馈的强化学习 (RLHF)。人类给模型的回答打分,模型根据分数优化自己的生成策略。
- 自动驾驶与金融:控制车辆变道、加速,或者在股市中进行高频交易决策。
主要算法流派
强化学习的算法非常多,主要可以分为以下几类:
- 基于价值 (Value-Based):
- 核心思想:学习一个价值函数(Q表),评估在某个状态下做某个动作“值多少钱”(期望回报)。
- 代表算法:Q-Learning、DQN (Deep Q-Network)。DQN 结合了深度学习,能处理像游戏画面这样复杂的输入。
- 基于策略 (Policy-Based):
- 核心思想:不计算价值,直接输出动作的概率(比如 80% 概率向左,20% 向右)。
- 代表算法:Policy Gradient (策略梯度)。
- 演员-评论家 (Actor-Critic):
- 核心思想:结合了以上两者。“演员”(Actor)负责选动作,“评论家”(Critic)负责评价这个动作好不好,并指导演员改进。
- 代表算法:A3C、PPO (近端策略优化)、DDPG。PPO 是目前应用最广泛的算法之一,稳定性很好。
对比:强化学习 vs. 监督学习
表格
| 维度 | 监督学习 | 强化学习 |
|---|---|---|
| 数据形式 | 静态的“输入-标签”对(如图片-猫) | 动态的交互序列(状态-动作-奖励) |
| 反馈信号 | 直接:直接告诉答案(这是猫) | 延迟/评价式:只告诉你好坏(得10分),不告诉正确动作 |
| 目标 | 拟合数据分布,做预测 | 学习策略,最大化长期回报 |
| 典型应用 | 图像识别、垃圾邮件分类 | 游戏、机器人、自动驾驶、量化交易 |
概括一下
强化学习是通往通用人工智能 (AGI) 的关键路径之一,因为它模拟了生物在未知环境中自主学习的能力。虽然它的训练难度比监督学习大(需要大量试错、收敛慢),但在解决复杂的决策问题上,它是目前最强大的工具。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...