Transformer神经网络和卷积神经网络(CNN)是当前人工智能领域两大核心架构,它们在设计理念、工作机制和应用场景上存在根本性的区别。
简单来说,CNN像一个专注细节的“显微镜”,擅长通过局部特征逐步构建对整体的理解;而Transformer则像一个掌控全局的“广角镜”,能够一次性洞察所有元素之间的关联。
核心机制:局部扫描 vs. 全局关联
这是两者最根本的区别,决定了它们处理信息的方式。
- 卷积神经网络 (CNN)
- 核心思想:局部感知和权重共享。
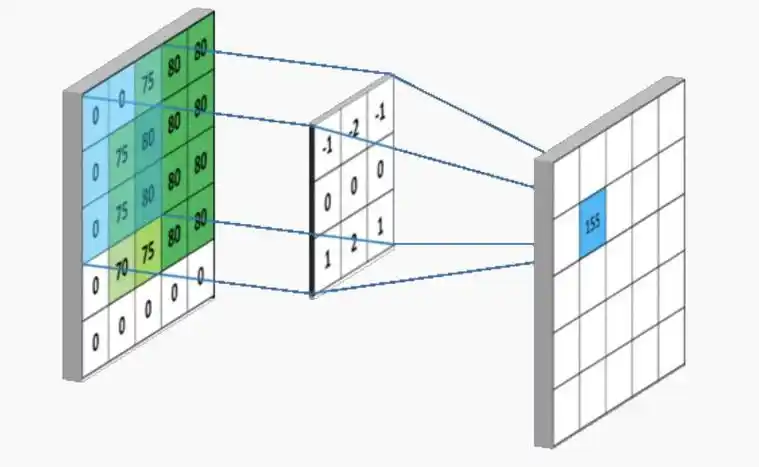
- 工作方式:CNN使用一个被称为“卷积核”的小窗口(如3×3像素)在图像上滑动。它一次只关注一个小的局部区域,通过提取边缘、纹理等基础特征,再通过层层堆叠,逐步组合成更复杂的概念(如眼睛、人脸)。同一个卷积核在图像的不同位置使用相同的参数,这极大地减少了需要学习的参数量。
- Transformer
- 核心思想:自注意力机制 (Self-Attention)。
- 工作方式:Transformer在处理一个序列(如一句话)时,允许序列中的任何一个元素(如一个词)直接“关注”并与序列中的所有其他元素进行交互,无论它们相距多远。这就像一场全员讨论会,每个词都能同时获取整个句子的上下文信息,从而捕捉长距离的依赖关系。
详细对比
下面的表格可以更清晰地展示它们在多个维度上的差异:
表格
| 特性 | 卷积神经网络 (CNN) | Transformer |
|---|---|---|
| 核心机制 | 卷积操作(局部滤波) | 自注意力机制(全局关联) |
| 感受野 | 局部,需多层堆叠才能扩大 | 全局,理论上一步即可关注所有位置 |
| 位置信息 | 隐含,由卷积核的滑动顺序自然引入 | 显式,需要额外添加“位置编码” |
| 长距离依赖 | 建模能力较弱,路径长 | 建模能力极强,路径恒为1 |
| 并行计算 | 高,但层与层之间是串行的 | 极高,序列内所有位置可同时计算 |
| 参数效率 | 较高(得益于权重共享) | 相对较低(参数量通常更大) |
| 数据需求 | 相对较少,自身具备较强的归纳偏置 | 需要海量数据来训练,以避免过拟合 |
擅长领域:图像处理 vs. 序列建模
基于上述核心差异,两者在不同类型的任务上各领风骚。
- CNN的天下:计算机视觉 (CV)
CNN天生适合处理具有空间局部相关性的网格数据,如图像和视频。它的局部感知特性完美契合了图像中相邻像素关系紧密的特点。因此,在图像分类(如ResNet)、目标检测(如YOLO)、人脸识别等领域,CNN长期占据主导地位。 - Transformer的王国:自然语言处理 (NLP)
Transformer在处理序列数据上表现卓越。在自然语言中,一个词的含义往往取决于上下文,甚至是很远的词。Transformer的全局注意力机制能完美捕捉这种长距离依赖,因此彻底改变了NLP领域,成为BERT、GPT等大语言模型的基础。
融合与发展:界限正在模糊
值得注意的是,两者并非完全对立,而是呈现出相互借鉴和融合的趋势。
- Vision Transformer (ViT):将图像分割成一个个小块(Patch),每个块被视为一个“词”,然后送入Transformer进行处理。这使得Transformer在图像分类等任务上也能达到甚至超越CNN的性能。
- 混合模型:如Swin Transformer,它在Transformer中引入了类似CNN的局部窗口注意力,兼顾了全局建模和计算效率。而一些CNN架构也开始加入注意力模块来增强对全局信息的捕捉能力。
总而言之,CNN和Transformer是两种不同但都极其强大的思想。CNN凭借其高效的局部特征提取能力,在视觉领域根基深厚;而Transformer则以其卓越的全局建模能力,在序列数据处理上独占鳌头。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...