
卷积神经网络(CNN)和循环神经网络(RNN)是深度学习领域两大基石,它们的核心区别在于处理不同类型的数据:CNN擅长处理具有空间结构的数据(如图像),而RNN则专为处理序列数据(如文本、语音)而生。
可以将它们想象成两种不同的专家:
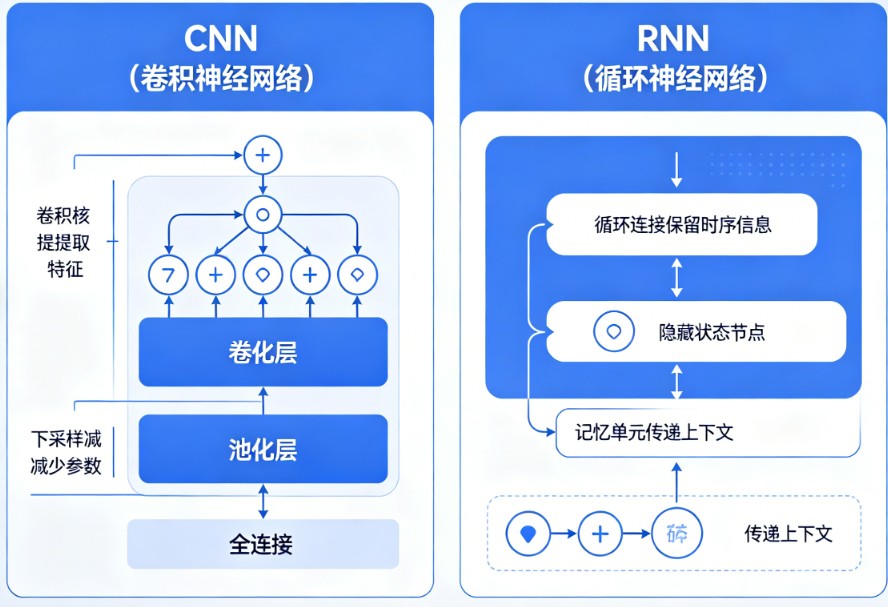
- CNN 像一位图像分析师,通过“扫描仪”(卷积核)在图像上滑动,识别出边缘、纹理等局部特征,再组合成整体。
- RNN 像一位故事朗读者,逐字逐句地阅读,并依靠“记忆”来理解上下文,从而把握整个故事的脉络。
核心区别对比
下表清晰地展示了它们在多个维度上的差异:
表格
| 特性 | 卷积神经网络 (CNN) | 循环神经网络 (RNN) |
|---|---|---|
| 核心机制 | 卷积操作(局部特征提取) | 循环连接(信息记忆与传递) |
| 擅长数据 | 空间数据(如图像、视频) | 序列数据(如文本、语音、时间序列) |
| 信息流动 | 前馈式,层与层之间单向传递 | 循环式,信息在时间步之间传递 |
| 记忆能力 | 无内在记忆,每次处理独立 | 有“隐藏状态”作为记忆,可联系上下文 |
| 并行计算 | 效率高,可高度并行处理 | 效率低,必须按顺序串行计算 |
| 典型应用 | 图像识别、目标检测 | 机器翻译、语音识别 |
工作机制:空间扫描 vs. 时间记忆
- 卷积神经网络 (CNN)
- 核心思想:局部感知。CNN通过一个或多个“卷积核”在输入数据(如图像)上滑动,每次只关注一个小的局部区域。
- 工作方式:它像使用滤镜一样,提取出图像中的基础特征(如线条、颜色),然后通过堆叠多个卷积层,将这些简单特征组合成更复杂的特征(如眼睛、车轮),最终形成对整体的理解。
- 循环神经网络 (RNN)
- 核心思想:记忆传递。RNN的核心在于其“隐藏状态”,它像一个记忆单元,能够保存之前处理过的信息。
- 工作方式:在处理序列时(如一句话),RNN会逐字读取。在处理当前词时,它不仅会看这个词本身,还会结合“隐藏状态”中保存的关于前面所有词的信息,从而理解上下文。
擅长领域:视觉任务 vs. 序列任务
基于不同的工作机制,它们在各自擅长的领域大放异彩。
- CNN的天下:计算机视觉 (CV)
CNN天生适合处理具有网格状拓扑结构的数据。在图像中,相邻的像素关系紧密,CNN的局部感知特性能够高效地捕捉这些空间特征。因此,它在图像分类、人脸识别、医学影像分析等领域是首选模型。 - RNN的王国:序列建模
RNN专为处理前后相关的序列数据而设计。在自然语言或语音中,当前元素的含义往往依赖于之前的元素。RNN的记忆能力使其能够建模这种时间上的动态依赖关系,因此在机器翻译、文本生成、语音识别和时间序列预测(如股票走势)等任务中表现出色。
融合与发展:取长补短
在实际应用中,许多复杂任务同时具备空间和时序特征,单一网络难以胜任,这时就需要将两者结合。
- 视频行为分析:先用CNN提取视频中每一帧图像的空间特征(如人物的姿态),再将这些特征按时间顺序输入RNN,以捕捉帧与帧之间的动作变化,从而识别出完整的动作(如“跑步”或“挥手”)。
- 视频字幕生成:同样,CNN负责“看懂”视频画面中的内容,RNN则根据这些视觉信息,像讲故事一样生成连贯的字幕。
此外,由于传统的RNN存在“梯度消失”问题,难以捕捉长距离的依赖关系,其改进版本如长短期记忆网络(LSTM)和门控循环单元(GRU)在实际应用中更为常见,它们通过更复杂的门控机制有效地解决了这一问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...