Vision Transformer (ViT) 是计算机视觉领域的一个里程碑式模型,它由Google Research团队在 2020 年提出。ViT的核心突破在于,它打破了卷积神经网络(CNN)在该领域长达十年的主导地位,证明了纯 Transformer架构同样能够出色地处理图像任务,甚至在大规模数据集上表现更优。
简单来说,ViT 将 NLP(自然语言处理)中处理文本序列的成功经验,创造性地应用到了图像处理上,其核心思想是将图像视为一个“词序列”。
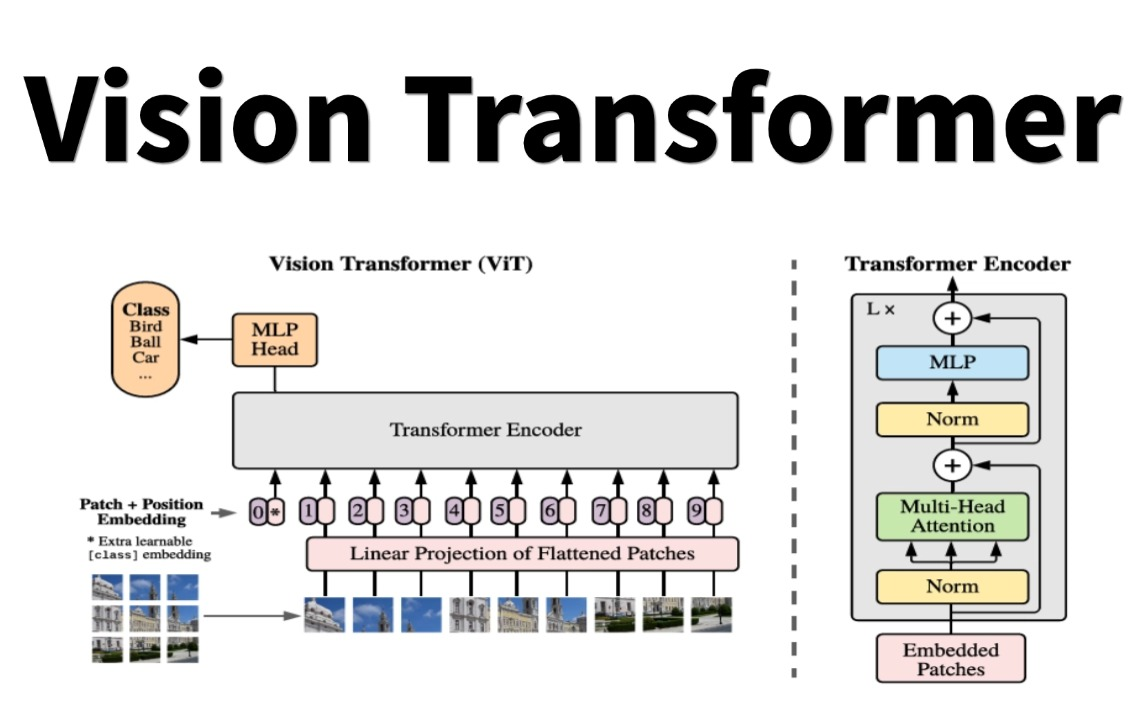
核心思想:图像即序列
传统CNN通过卷积核在图像上滑动来提取局部特征,并逐层构建全局理解。而 ViT 则采取了完全不同的路径:
- 图像分块 (Patch Embedding)
ViT 首先将一张完整的图像(例如 224×224 像素)切割成一系列固定大小的小方块(例如 16×16 像素)。这个过程就像把一句话切分成一个个单词。 - 序列化与嵌入
每个图像块被展平成一个一维向量,然后通过一个线性投影层,转换为 Transformer 可以处理的“词嵌入”(Token Embedding)。 - 注入位置信息 (Positional Embedding)
由于 Transformer 本身不具备感知序列顺序的能力,ViT 会为每个图像块的嵌入向量加上一个可学习的位置编码,以保留其在原始图像中的空间位置信息。 - 添加分类标记 ([CLS] Token)
在图像块序列的开头,ViT 会添加一个特殊的、可学习的[CLS]标记。这个标记在整个 Transformer 编码器的处理过程中,会不断聚合来自所有图像块的全局信息,其最终输出状态将被用于图像分类任务。
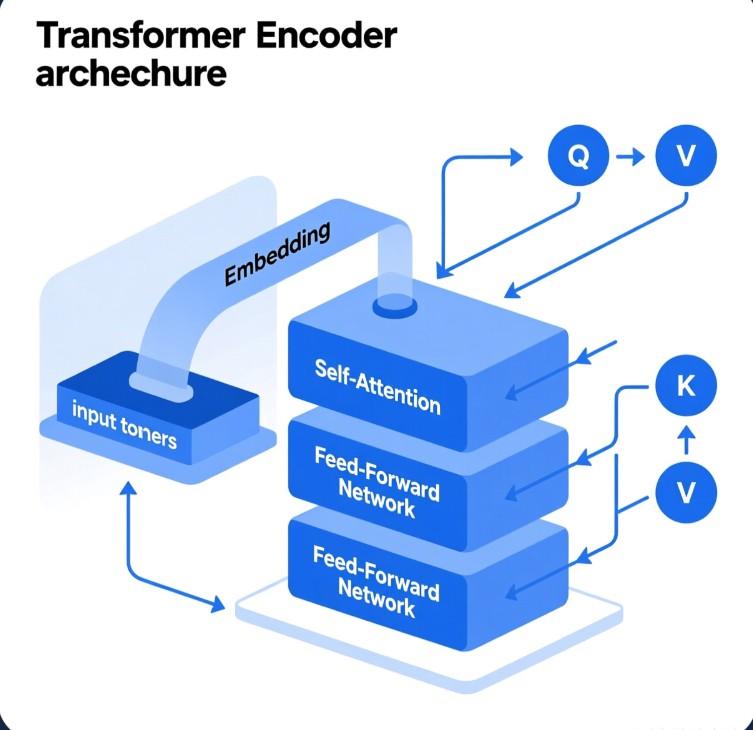
模型架构
完成上述预处理后,得到的序列就会被输入到一个标准的Transformer编码器中。这个编码器由多层堆叠而成,每一层都包含两个核心模块:
- 多头自注意力 (Multi-Head Self-Attention, MSA):这是 ViT 的“心脏”。它允许序列中的每一个图像块与所有其他图像块进行交互,从而直接捕捉图像中的长距离依赖关系和全局上下文。例如,在处理一张鸟的图片时,模型可以同时关注到喙、眼睛和羽毛,并理解它们之间的空间关系。
- 前馈网络 (MLP):一个包含两层全连接层的简单网络,用于对自注意力模块提取的特征进行非线性变换。
此外,每层都使用了残差连接和层归一化(LayerNorm)等标准技术来稳定训练过程。
与CNN的关键区别
ViT和CNN代表了两种截然不同的视觉处理范式。
表格
| 特性 | CNN (卷积神经网络) | ViT (视觉Transformer) |
|---|---|---|
| 核心机制 | 卷积操作(局部特征提取) | 自注意力机制(全局关系建模) |
| 感受野 | 局部,需多层堆叠才能扩大 | 全局,从第一层就开始关注全图 |
| 归纳偏置 | 强(平移不变性、局部性) | 弱(几乎无预设,依赖数据学习) |
| 数据需求 | 相对较少,在小数据集上表现好 | 数据饥渴,需要海量数据才能发挥优势 |
| 计算成本 | 相对较低 | 较高,尤其对于高分辨率图像 |
优势、局限与演进
主要优势
- 强大的全局建模能力:自注意力机制使其能直接捕捉图像中任意两个区域的关系,特别适合需要理解整体结构的复杂场景。
- 卓越的可扩展性:在大规模数据集(如 JFT-300M)上预训练后,其性能会随着模型和数据规模的增大而持续提升,展现出强大的扩展规律。
主要局限
- 数据饥渴:由于缺乏CNN的归纳偏置,ViT 在中小规模数据集(如 ImageNet-1k)上从头训练时,性能往往不如 CNN,且容易过拟合。
- 计算成本高:自注意力机制的计算复杂度与图像块数量的平方成正比,处理高分辨率图像时计算开销巨大。
重要变体与改进
为了克服这些局限,研究者们提出了大量优秀的ViT变体:
- DeiT (Data-efficient Image Transformer):通过引入知识蒸馏技术,让ViT能够利用CNN作为“老师”进行训练,从而在较小的数据集上也能高效训练。
- Swin Transformer:引入了滑动窗口机制和层次化结构,将自注意力计算限制在局部窗口内,大大降低了计算复杂度,使其更适合目标检测、语义分割等密集预测任务。
- DINOv2:Meta 推出的一个基于ViT的自监督学习模型。它通过在海量无标签图像上进行预训练,学习到极其强大的通用视觉特征,无需微调即可在分类、分割、深度估计等多种下游任务上取得优异表现。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...