GPT Image 2是OpenAI于2026年4月推出的新一代AI图像生成模型,它标志着AI生图从“去噪”走向“推理”的范式转移。该模型具备“思考”能力,能够进行复杂的推理和规划,在图像质量、文字渲染和指令遵循等方面实现了巨大飞跃。

GPT Image 2核心突破
GPT Image 2的核心创新在于其底层架构的重写。与DALL-E 3等传统扩散模型从噪点中“擦”出图像不同,GPT Image 2采用了自回归生成的方式。
- 像写字一样画图:它将图像视为一串“图像token”(类似文字的单元),然后像GPT写文章一样,一个token接一个 token地按顺序“写”出图像。
- 全局思考,逻辑一致:这种“按顺序生成”的模式迫使模型在每一步都进行全局思考,确保生成的每个局部都与整体逻辑保持一致,从根本上解决了元素摆放“随缘”的问题。
GPT Image 2主要能力与特点
GPT Image 2的强大能力源于其三大核心架构革新:
- 原生多模态处理:文本和图像在同一个Transformer模型内部并行处理,共享同一套语义空间。这意味着模型在“读”到提示词时,就能同步理解并规划图像内容,避免了信息在传递过程中的损耗。
- “思考-生成”一体化:模型将理解需求的“思考”过程和渲染像素的“生成”过程合二为一,在同一次计算中完成。这不仅大幅提升了速度,也保证了执行与意图的高度统一。
- 生成后“自我检查”:模型在生成图像后,会用自身的视觉理解能力对结果进行“自我审查”,评估其与提示词的匹配度。如果分数不够,它会自动重新生成,直到达标为止,相当于内置了一位严格的质检员。
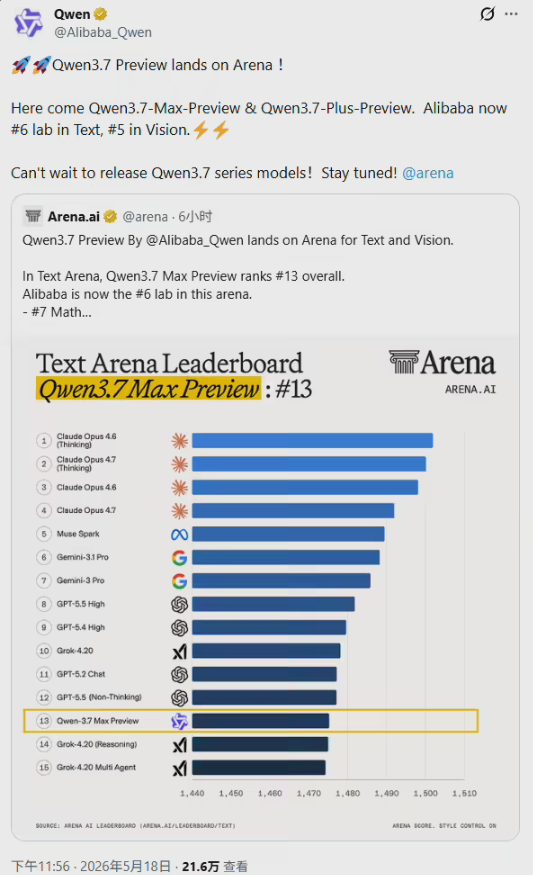
GPT Image 2性能指标对比
相较于前代模型,GPT Image 2在多个关键指标上实现了质的飞跃。
表格
| 指标 | 上一代模型 | GPT Image 2 | 提升意义 |
|---|---|---|---|
| 文字渲染准确率 | 90-95% | 99% | 告别“AI 鬼画符”,精准呈现多语言文字 |
| 最大分辨率 | 1024×1024 | 4096×4096 (4K) | 达到商业级高清可用标准 |
| 复杂空间推理失败率 | ~12% | <2% | 元素摆放精准,逻辑性强 |
| 单图生成延迟 | 10-20 秒 | 3 秒内 | 从“等等看”到“秒出” |
GPT Image 2应用场景
GPT Image 2 的强大能力使其成为一个真正的生产力工具,但也带来了不容忽视的风险。
强大的生产力应用
- 商业设计:能够快速生成商品广告、产品分解图、宣传海报等,大幅降低设计门槛。
- 内容创作:可一次性生成最多8张保持角色和风格一致的图像,非常适合制作漫画、故事集或系列配图。
- UI/UX 复刻:能够精准理解和复刻抖音、英雄联盟等复杂应用的界面布局和视觉元素。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...