ELF(Embedded Language Flows,嵌入式语言流)是由计算机视觉领域顶级科学家何恺明及其MIT团队在2026年5月推出的首个连续扩散语言模型。
它打破了以GPT为代表的“预测下一个词”的自回归范式,证明了连续扩散模型在文本生成领域不仅可行,而且在效率和资源消耗上具备巨大优势。
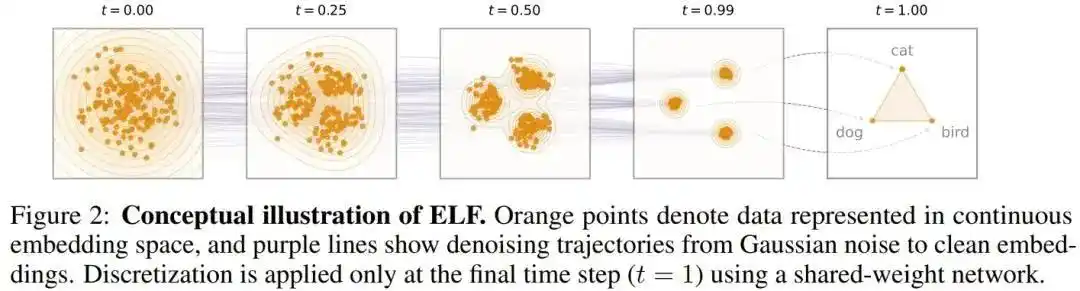
ELF核心理念
传统的扩散语言模型主要分为两派:一派是直接在离散的token空间做扩散(离散派);另一派是将token映射到连续空间去噪,但往往中途又要切回离散空间(不彻底的连续派)。
ELF 的核心突破在于将“连续”做到了极致:
- 全程连续去噪:它把整个文本生成过程完全保留在连续的语义嵌入(embedding)空间中进行。模型从一团纯高斯噪声出发,逐步去噪,还原出干净的连续向量。
- 最后一步离散化:只有在去噪过程的最后一步,ELF 才会将处理好的连续向量“翻译”成具体的离散 token(词汇)。
这种设计避免了在碎片化的token序列上进行低效扩散,让模型在更具全局一致性的向量空间中优化生成路径。
ELF核心亮点
ELF 用极小的资源消耗,跑赢了主流的大规模扩散模型,展现了极高的数据效率和计算效率:
- 极小的参数规模:仅有 1.05亿(105M) 参数。
- 极少的训练数据:仅使用了约 450亿(45B) 个 token 进行训练。相比之下,同级别的离散扩散模型(如 MDLM、Duo 等)通常需要 5000亿(500B+)以上的token,ELF的数据量不足对手的十分之一。
- 极快的推理速度:仅需 32步 采样就能生成高质量文本。而主流离散扩散模型往往需要运行 1024 步才能达到相近的效果。
- 出色的生成质量:在OpenWebText基准测试中,ELF的生成困惑度(Generative Perplexity,越低越好)低至 24,文本自然度超越了众多主流模型。
ELF技术实现与性能表现
- 技术框架:ELF 采用了在图像生成领域大火的流匹配(Flow Matching)框架。它使用 T5 预训练编码器将文本转化为连续嵌入,并在推理时引入了“无分类器引导(CFG)”和“自条件(Self-Conditioning)”机制,进一步提升了生成质量。
- 多任务能力:除了基础的文本生成,ELF在WMT14 机器翻译和 XSum文本摘要等条件生成任务上也表现稳定,不仅超越了现有的扩散语言模型,甚至压制了一些同等规模的自回归基线模型。
行业意义
ELF的推出不仅是何恺明团队在语言生成方向上的重要跨界创新,也为整个AI行业带来了新的思考:
- 打破范式迷信:证明了语言模型不一定要走 GPT 的自回归老路,扩散模型在语言领域同样大有可为。
- 降本增效新路径:展示了通过创新的架构设计(而非单纯堆砌参数和数据),也能实现高质量的语言生成,为在普通硬件上部署高质量生成模型提供了潜在可能。
简单来说,ELF 就像是文本生成领域的“新物种”,它用一种更优雅、更省资源的方式,挑战了当前大模型“大力出奇迹”的传统路线。
ELF的项目地址
- GitHub仓库:https://github.com/lillian039/ELF
- arXiv技术论文:https://arxiv.org/pdf/2605.10938
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...