Xiaomi OneVL是小米正式对外发布并全面开源的自动驾驶大模型。Xiaomi OneVL的核心定位是“一步式潜空间语言视觉推理框架”。OneVL并非简单的视觉模型,而是小米XLA(认知大模型架构)在自动驾驶领域的首次系统性落地,旨在解决当前自动驾驶大模型长期面临的“精度”与“速度”难以兼得的行业痛点。
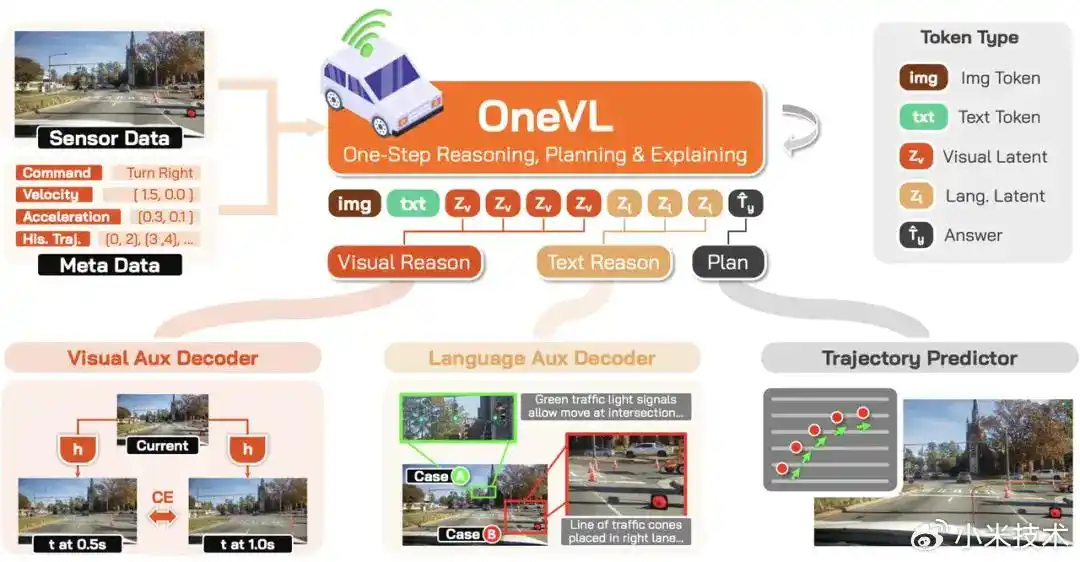
Xiaomi OneVL核心突破:首次统一 VLA 与世界模型
在传统的自动驾驶技术路线中,VLA(视觉语言动作模型)和世界模型通常是两条独立发展的路线:
- VLA:擅长理解当前场景并输出驾驶动作,但缺乏对未来的预测能力。
- 世界模型:擅长预测未来场景的演变,但往往独立于决策系统之外。
Xiaomi OneVL在业内率先通过潜空间推理,将VLA、世界模型和潜空间推理三大技术路线统一到了同一套框架中。它让模型不仅能“看懂”现在的路况,还能在内部“预演”未来的画面,从而实现更精准的驾驶决策。

Xiaomi OneVL三大关键技术
为了实现“又快又准”的推理,OneVL采用了三项核心技术:
- 双模态潜令牌(让模型在心里想清楚):
- 视觉潜令牌:负责编码场景的物理因果结构(如车辆运动、道路几何)。
- 语言潜令牌:负责编码驾驶意图的语义表达。
- 两者结合,让模型在内部完成复杂的思考,而不是“边说边想”。
- 双辅助解码器(训练时用,推理时丢):
- 视觉解码器:在训练时预测未来 0.5秒 / 1秒 的画面,赋予模型世界模型的未来预测能力。
- 语言解码器:在训练时重建人类可读的思维链文字,保障决策的可解释性。
- 在正式推理时,这两个解码器会被完全移除,实现零额外计算开销。
- “预填充式”一步推理(快到极致):
- 抛弃了传统大模型逐字逐句生成的显式思维链(CoT),改为将所有潜令牌直接预填充进上下文,一次并行完成推理。
- 这使得它的推理延迟与“仅输出答案”的模型几乎一致,比传统的显式CoT最高快 2.3倍。
Xiaomi OneVL性能表现与落地前景
Xiaomi OneVL在多个主流基准测试中刷新了性能上限,并展现出了极强的车端部署潜力:
表格
| 维度 | 核心数据表现 |
|---|---|
| 推理速度 | 延迟低至 0.24秒(4.16 Hz),仅为传统 VLA 自回归推理的 5.4% |
| 决策精度 | 在 NAVSIM 基准测试中 PDM-score 达到 88.84,首次在潜空间推理中超越显式 CoT(88.29) |
| 综合排名 | 在 ROADWork、Impromptu、Alpamayo-R1 三项基准上均达到 SOTA(当前最优水平) |
双重可解释性:拒绝“黑箱决策”
为了解决自动驾驶“为什么这么开”的安全疑虑,OneVL提供了语言和视觉双维度的可解释性:
- 文字说明:能用自然语言解释决策原因(例如:“因为右侧有施工锥桶和停放的卡车,所以需要向左变道并保持减速”)。
- 画面预测:能直接展示模型预测出的“接下来会发生什么”的未来画面。
全面开源与生态战略
- 对行业:极大地降低了中小企业的研发门槛,为量产车端的实时部署提供了可行的技术路径。
- 对小米:这是小米“人车家全生态”战略的核心技术底座。通过开源,小米旨在吸引全球开发者共建生态,不仅服务于小米汽车(如 SU7、YU7),未来还有望打通机器人、智能家居等跨设备的智能协同。
Xiaomi OneVL的项目地址
项目官网:https://xiaomi-embodied-intelligence.github.io/OneVL/
GitHub仓库:https://github.com/xiaomi-research/onevl
arXiv技术论文:https://arxiv.org/pdf/2604.18486
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...