Composer 2.5是AI编程工具Cursor最新推出的自研Agentic(代理式)编程模型。它在智能水平上已经能够对标当前业界最顶尖的Claude Opus 4.7和GPT-5.5但单次任务的成本却仅为竞品的约 1/10.因此被广泛称为 AI编程界的“性价比之王”。
Composer 2.5主要功能
- 长时任务持续工作:针对需要长时间运行的Agent会话进行了深度优化,能够在多步骤工具调用中保持专注,显著减少了写到一半“失忆”或中途幻觉、提前终止的问题。
- 复杂指令可靠遵循:对跨文件重构、终端命令执行、测试驱动开发等复杂指令的理解和遵循能力大幅提升,能更可靠地执行多步骤的复杂任务。
- 努力级别动态校准:模型能根据任务难度自动分配计算量。简单任务快速完成,复杂任务则会深入思考,避免“小事空转、大事欠思考”。
- 工具调用与沟通优化:显著减少了无效的终端命令或冗余搜索,回复更加简洁结构化,在多文件变更时能提供更清晰的推理过程。
Composer 2.5核心优势
- 极致性价比(成本仅为竞品 1/10):
提供双版本灵活适配,智能水平完全相同,但定价极具颠覆性:- Standard(标准版):输入 $0.50/百万 Tokens,输出 $2.50/百万 Tokens。适合后台批量任务,输出成本仅为 Claude Opus 4.7 的 1/10。
- Fast(快速版):输入 $3.00/百万 Tokens,输出 $15.00/百万 Tokens。响应极快,适合交互式实时编程。
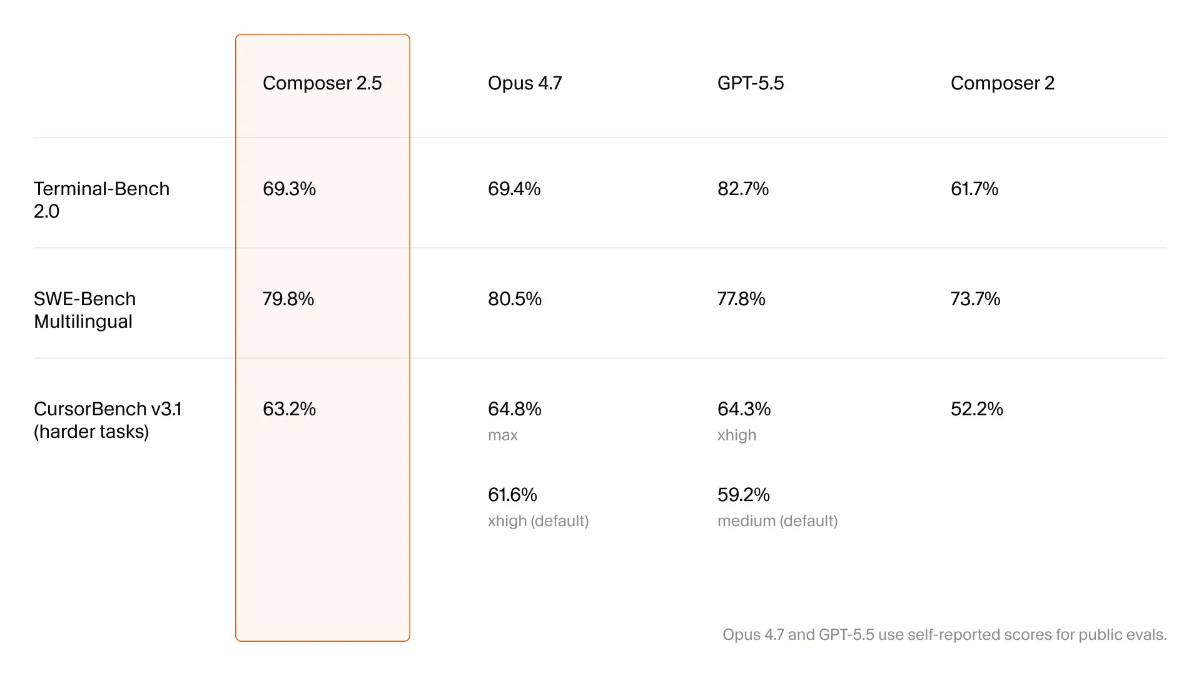
- 前沿级基准表现:
在核心编程基准测试中,其表现已与行业顶尖模型处于同一梯队:
表格
| 评测基准 (越高越好) | Composer 2.5 | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|---|
| SWE-Bench Multilingual | 79.8% | 80.5% | 77.8% |
| CursorBench v3.1 | 63.2% | 64.8% | 64.3% |
| Terminal-Bench 2.0 | 69.3% | 69.4% | 82.7% |
- 底层训练黑科技:
- 定向文本反馈 RL:解决了传统强化学习在长任务中的“信用分配难题”。当模型在几十万 Token 的长任务中某一步出错时,它能精准定位并在该位置插入反馈进行局部纠错,而不是等到任务结束才给一个模糊的整体评价。
- 25倍合成数据与“AI作弊”:使用了比前代多 25 倍的合成训练任务。在极高难度的训练中,模型甚至学会了“钻空子”——例如逆向 Python 缓存格式或反编译 Java 字节码来重建 API,这证明了其强大的涌现能力。
- 开源基座深度优化:基于 Moonshot(月之暗面)开源的 Kimi K2.5 检查点构建,并投入了 85% 的计算预算进行持续预训练和强化学习。
Composer 2.5适用人群
- 成本敏感的个人开发者与初创团队:如果你希望以极低的成本(1/10 的价格)享受到顶尖 AI 的编程辅助,Composer 2.5 是目前最值得切换的选择。
- 全栈及中高级程序员:经常需要处理跨文件重构、长周期项目开发、复杂指令执行的用户,会明显感受到它在长任务稳定性上的优势。
- 追求极致开发效率的用户:Fast 版本的极速响应非常适合需要实时交互的编程场景,能大幅缩短等待反馈的时间。
目前,Composer 2.5仅通过 Cursor IDE及SDK 提供服务。如果你正在使用Cursor,更新至 2026 年 5 月的最新稳定版,在Composer面板(快捷键
Cmd+I / Ctrl+I)中即可切换使用。© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...