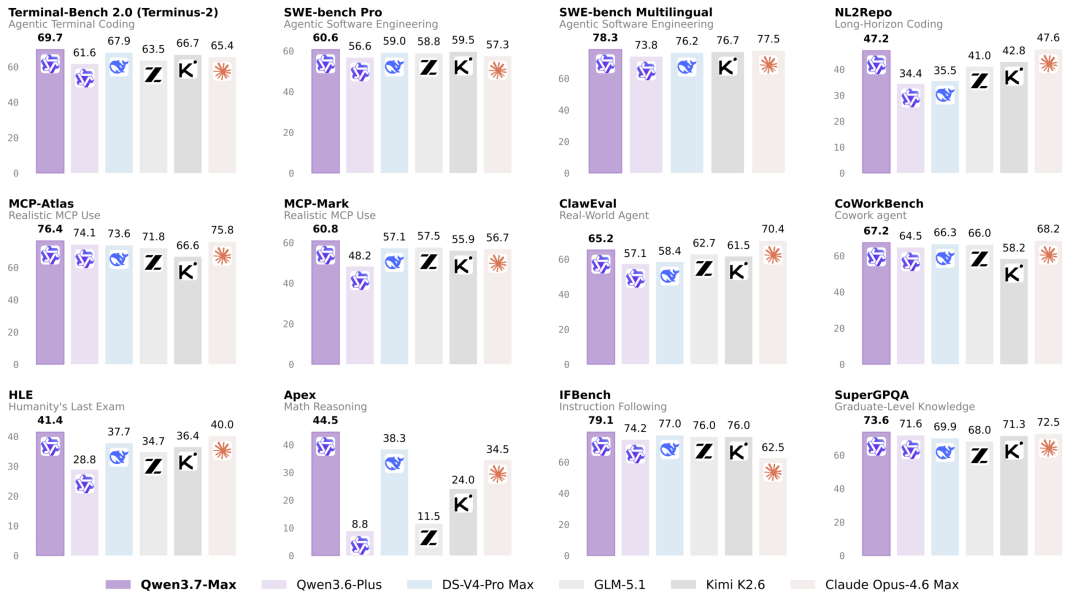
Qwen3.7-Max是阿里巴巴发布的千问系列新一代旗舰大模型,核心定位为面向智能体(Agent)时代的全能基座模型,其最大突破在于无需人工干预即可自主完成超长周期复杂任务(如35小时连续工作、1158次工具调用),并将关键推理内核性能提升10倍。该模型标志着大模型从“对齐人类偏好”向“对齐任务目标”的范式转移,重点解决智能体在真实生产环境中易断片、易崩溃的行业痛点,而非仅追求参数规模或单次对话能力。

Qwen3.7-Max定位与技术突破
1. 从“说得好”到“做得到”的范式转移
- 传统大模型侧重单次对话的流畅性,而Qwen3.7-Max专为长周期自主执行任务设计,能持续跟踪数百至数千步的复杂流程,保持逻辑连贯性。阿里巴巴通义大模型事业部负责人周靖人指出,这是大模型从“聊天助手”向“生产级智能体”的关键进化。
- 通过“任务-运行框架-验证器”正交解耦技术,模型摆脱了对特定开发框架的依赖,在Claude Code、OpenClaw等不同环境中均能稳定输出,避免因环境切换导致性能骤降。
2. 长程任务自主执行能力验证
- 在无任何硬件文档支持的极端测试中,模型仅凭任务说明书,在平头哥真武M890芯片上自主完成35小时连续工作,独立执行432次内核评估、1158次工具调用,最终将推理速度较官方参考实现提升10倍(远超GLM 5.1的7.3倍和Kimi K2.6的5.0倍)。
- 关键突破点在于:模型在运行超30小时后仍能主动发起架构重设计,证明其具备动态问题诊断与持续迭代能力,而非依赖预设规则。
Qwen3.7-Max关键能力表现
1. 编程与推理能力
- 编程智能体:在SWE-Pro(60.6分)、SWE-Multilingual(78.3分)等真实编程任务评测中领先国际主流模型,Terminal Bench 2.0-Terminus得分69.7,超越DeepSeek-v4-pro-Max(67.9分)。
- 推理与泛化:在GPQA Diamond(92.4分)和HLE(41.4分)等高难度推理测试中超越Claude Opus-4.6(91.3分、40.0分),多语言能力WMT24++(85.8分)、MAXIFE(89.2分)处于全球第一梯队。
2. 办公与生产力场景
- 通过MCP集成与多智能体协作,实现端到端工作流自动化。在SpreadSheetBench-v1办公自动化基准中得分87.0分,为当前顶尖水平,可将原本需专业团队耗时1-2周的项目压缩至数小时内完成。
- 支持从需求分析到测试迭代的全流程闭环,能自主产出工业级可用成果(如实时交互3D粒子系统网页)。
Qwen3.7-Max技术架构特点
1. 全栈Agent化支持体系
- 阿里云同步推出“芯片—云—模型—推理”全栈升级:平头哥真武M890芯片、百炼推理平台、云产品Skill化改造,形成智能体原生技术底座。
- 模型API将通过阿里云百炼平台提供服务,用户可直接调用,无需自行适配底层基础设施。
2. 长时序强化学习优化
- 针对智能体场景设计训练机制,通过全局批次平衡损失函数和ChunkFlow上下文并行技术,解决超长任务中的训练不稳定问题,支撑256K上下文高效处理。
- 动态思考预算控制:允许用户配置推理深度,在响应速度与任务质量间灵活平衡。
Qwen3.7-Max应用场景与生态
1. 企业级落地价值
- AI Infra优化:自主完成芯片级算子调优,显著降低企业推理成本(如10倍加速可减少90%算力消耗)。
- 复杂流程自动化:在模拟经营决策任务中,Qwen3.7-Max驱动的智能体营收可达前代模型的数倍,展现长周期策略进化能力。
2. 开放生态策略
- 阿里云百炼平台已全面开放,支持与月之暗面、智谱等第三方模型协同,提供“一个入口、多模型可选”的标准化服务。
- 同步推出Qwen3.7-Plus等衍生版本,覆盖多模态理解与视觉智能体场景,形成从编程到视觉的全栈智能体能力矩阵。
Qwen3.7-Max的核心价值在于将智能体从“理论可行”推向“工程现实”。其35小时自主任务验证不仅证明了长周期执行的可靠性,更揭示了未来AI将从“工具”进化为“自主生产力单元”的趋势。目前模型API即将上线阿里云百炼,企业用户需关注其在真实业务场景中的稳定性表现,而开发者可通过百炼平台快速接入,降低智能体应用开发门槛。需注意,该模型对算力要求较高,轻量化部署可能需等待后续Qwen3.7-Turbo版本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...